[译]机器学习:有监督算法之分类
demi 在 周一, 01/14/2019 - 16:25 提交
机器学习横跨计算机科学、工程技术和统计学等多个科学。人们很难直接从原始数据本身获得所需信息,机器学习可以把无序的数据转换成有用的信息;移动计算和传感器产生的海量数据意味着未来将面临越来越多的数据,如何从中抽取到有价值的信息很重要,机器学习可以帮助我们从中抽取有用的信息。
算法是一组用于解决特定问题或执行特定任务的有序步骤。在计算机科学中,算法是用于完成计算任务的一系列定义明确的指令。算法可以用于处理数据、执行计算、解决问题或执行其他与计算有关的任务。
机器学习算法是机器学习领域中用于从数据中学习模式并做出预测或决策的数学模型或规则。这些算法可以分为多个主要类别,取决于学习任务的类型和目标。
机器学习横跨计算机科学、工程技术和统计学等多个科学。人们很难直接从原始数据本身获得所需信息,机器学习可以把无序的数据转换成有用的信息;移动计算和传感器产生的海量数据意味着未来将面临越来越多的数据,如何从中抽取到有价值的信息很重要,机器学习可以帮助我们从中抽取有用的信息。

临时研究了下机器视觉两个基本算法的算法原理 ,可能有理解错误的地方,希望发现了告诉我一下
主要是了解思想,就不写具体的计算公式之类的了
<(一) ICP算法(Iterative Closest Point迭代最近点)/strong>
ICP(Iterative Closest Point迭代最近点)算法是一种点集对点集配准方法,如下图1
如下图,假设PR(红色块)和RB(蓝色块)是两个点集,该算法就是计算怎么把PB平移旋转,使PB和PR尽量重叠,建立模型的

摘要: 本文对机器学习的一些基本概念给出了简要的介绍,并对不同任务中使用不同类型的机器学习算法给出一点建议。
在从事数据科学工作的时候,经常会遇到为具体问题选择最合适算法的问题。虽然有很多有关机器学习算法的文章详细介绍了相关的算法,但要做出最合适的选择依然非常困难。
在这篇文章中,我将对一些基本概念给出简要的介绍,对不同任务中使用不同类型的机器学习算法给出一点建议。在文章的最后,我将对这些算法进行总结。
首先,你应该能区分以下四种机器学习任务:
• 监督学习
• 无监督学习
• 半监督学习
• 强化学习
监督学习
监督学习是从标记的训练数据中推断出某个功能。通过拟合标注的训练集,找到最优的模型参数来预测其他对象(测试集)上的未知标签。如果标签是一个实数,我们称之为回归。如果标签来自有限数量的值,这些值是无序的,那么称之为分类。

1. LDA
LDA是一种三层贝叶斯模型,三层分别为:文档层、主题层和词层。该模型基于如下假设:
1)整个文档集合中存在k个互相独立的主题;
2)每一个主题是词上的多项分布;
3)每一个文档由k个主题随机混合组成;
4)每一个文档是k个主题上的多项分布;
5)每一个文档的主题概率分布的先验分布是Dirichlet分布;
6)每一个主题中词的概率分布的先验分布是Dirichlet分布。
文档的生成过程如下:
1)对于文档集合M,从参数为β的Dirichlet分布中采样topic生成word的分布参数φ;
2)对于每个M中的文档m,从参数为α的Dirichlet分布中采样doc对topic的分布参数θ;
3)对于文档m中的第n个词语W_mn,先按照θ分布采样文档m的一个隐含的主题Z_m,再按照φ分布采样主题Z_m的一个词语W_mn。

在三维显示,空间可视化表达和图像处理中,插值处理是比较重要的一个部分。如何能找到快速、简单、有效的插值算法是目前研究者们津津乐道的问题。
以下几种是前人收集起来的比较常用的插值算法,仅供参考:
• Inverse Distance to a Power(反距离加权插值法)
• Kriging(克里金插值法)
• Minimum Curvature(最小曲率)
• Modified Shepard's Method(改进谢别德法)
• Natural Neighbor(自然邻点插值法)
• Nearest Neighbor(最近邻点插值法)
• Polynomial Regression(多元回归法)
• Radial Basis Function(径向基函数法)
• Triangulation with Linear Interpolation(线性插值三角网法)
• Moving Average(移动平均法)
• Local Polynomial(局部多项式法)
下面简单说明不同算法的特点。

AIoT领域中人机交互的市场机会
自2017年开始,“AIoT”一词便开始频频刷屏,成为物联网的行业热词。“AIoT”即“AI+IoT”,指的是人工智能技术与物联网在实际应用中的落地融合。当前,已经有越来越多的人将AI与IoT结合到一起来看,AIoT作为各大传统行业智能化升级的最佳通道,已经成为物联网发展的必然趋势。
在基于IoT技术的市场里,与人发生联系的场景(如智能家居、自动驾驶、智慧医疗、智慧办公)正在变得越来越多。而只要是与人发生联系的地方,势必都会涉及人机交互的需求。人机交互是指人与计算机之间使用某种对话语言,以一定的交互方式,为完成确定任务的人与计算换机之间的信息交互过程。人机交互的范围很广,小到电灯开关,大到飞机上的仪表板或是发电厂的控制室等等。而随着智能终端设备的爆发,用户对于人与机器间的交互方式也提出了全新要求,使得AIoT人机交互市场被逐渐激发起来。
AIoT发展路径

一、空洞卷积的提出
空洞卷积(atrous convolutions)又名扩张卷积(dilated convolutions),向卷积层引入了一个称为 “扩张率(dilation rate)”的新参数,该参数定义了卷积核处理数据时各值的间距。
该结构的目的是在不用pooling(pooling层会导致信息损失)且计算量相当的情况下,提供更大的感受野。 顺便一提,卷积结构的主要问题如下:
池化层不可学
内部数据结构丢失;空间层级化信息丢失。
小物体信息无法重建 (假设有四个pooling layer 则 任何小于 2^4 = 16 pixel 的物体信息将理论上无法重建。)
而空洞卷积就有内部数据结构的保留和避免使用 down-sampling 这样的特性,优点明显。
二、空洞卷积原理
如下如,卷积核没有红点标记位置为0,红点标记位置同正常卷积核。

传统的Canny边缘检测算法是一种有效而又相对简单的算法,可以得到很好的结果(可以参考上一篇Canny边缘检测算法的实现)。但是Canny算法本身也有一些缺陷,可以有改进的地方。
1. Canny边缘检测第一步用高斯模糊来去掉噪声,但是同时也会平滑边缘,使得边缘信息减弱,有可能使得在后面的步骤中漏掉一些需要的边缘,特别是弱边缘和孤立的边缘,可能在双阀值和联通计算中被剔除。很自然地可以预见,如果加大高斯模糊的半径,对噪声的平滑力度加大,但也会使得最后得到的边缘图中的边缘明显减少。这里依然用Lena图为例,保持Canny算法中高阀值100,低阀值50不变,高斯半径分别为2,3,5的Canny边缘二值图像如下。可知高斯模糊把很多有用的边缘信息也模糊掉了,因此如何精确的选择高斯半径就相当重要。

在图像几何变换的过程中,常用的插值方法有最邻近插值(近邻取样法)、双线性内插值和三次卷积法。
最邻近插值:
这是一种最为简单的插值方法,在图像中最小的单位就是单个像素,但是在旋转个缩放的过程中如果出现了小数,那么就对这个浮点坐标进行简单的取整,得到一个整数型坐标,这个整数型坐标对应的像素值就是目标像素的像素值。取整的方式就是:取浮点坐标最邻近的左上角的整数点。
举个例子:
3 * 3 的灰度图像,其每一个像素点的灰度如下所示

我们要通过缩放,将它变成一个 4 * 4 的图像,那么其实相当于放大了4/3倍,从这个倍数我们可以得到这样的比例关系:
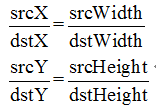

随着机器学习浪潮的高涨,越来越多的算法在许多任务中表现得很好。但是我们通常不可能在事先知道哪种算法会是最优的。如果你有无限的时间逐一去尝试每一个算法那就另当别论。接下来的文章我们将依赖从模型选择和超参数调节中得到的知识向你一步一步展示如何来选择最优的算法。
原文地址:http://www.askaswiss.com/2017/02/how-to-choose-right-algorithm-for-your-...
Step 1: 基本知识
在深入讨论之前,我们应当确保已经疏通了基本的知识点。首先,我们应该知道机器学习主要有三大分类:监督学习、无监督学习和强化学习。