深度学习模型各层参数数目对于性能的影响
demi 在 周四, 02/28/2019 - 15:56 提交
近年来深度学习在图像识别、语音识别等领域得到了广泛的应用,取得了优异的效果,但深度学习网络的结构设计没有一般规律可循。本文基于卷积神经网络和递归卷积神经网络模型探究了深度学习网络不同层级间参数分布对网络性能的影响。
卷积神经网络(CNN)是一种深度学习算法,特别擅长处理图像和视频数据。它通过模拟生物视觉系统的方式,利用卷积层、池化层等多层网络结构自动提取图像中的特征,进行分类、识别和预测。CNN被广泛应用于计算机视觉任务,如图像分类、人脸识别、物体检测等,已成为深度学习领域的重要模型之一。
近年来深度学习在图像识别、语音识别等领域得到了广泛的应用,取得了优异的效果,但深度学习网络的结构设计没有一般规律可循。本文基于卷积神经网络和递归卷积神经网络模型探究了深度学习网络不同层级间参数分布对网络性能的影响。

学习RCNN系列论文时, 出现了感受野(receptive field)的名词, 感受野的尺寸大小是如何计算的,在网上没有搜到特别详细的介绍, 为了加深印象,记录下自己对这一感念的理解,希望对理解基于CNN的物体检测过程有所帮助。

在训练一个神经网络时,“离线的”和可以实时识别新对象的训练模型(称为“推理”)之间是有区别的,例如,如果一个神经网络设计成用来识别过往的图片,例如一只猫,那么就需要从数千张猫的图像数据库中了解到猫是什么样的。 经过适当的训练,当你给一个有神经网络的设备展示猫先生的图片时,即使它以前没有见过猫它也能够认出猫,这就是推理。

深度卷积神经网络(CNN)是一种特殊类型的神经网络,在各种竞赛基准上表现出了当前最优结果。深度 CNN 架构在挑战性基准任务比赛中实现的高性能表明,创新的架构理念以及参数优化可以提高 CNN 在各种视觉相关任务上的性能。本综述将最近的 CNN 架构创新分为七个不同的类别,分别基于空间利用、深度、多路径、宽度、特征图利用、通道提升和注意力。

典型的卷积神经网络,开始阶段都是卷积层以及池化层的相互交替使用,之后采用全连接层将卷积和池化后的结果特征全部提取进行概率计算处理。在具体的误差反馈和权重更新的处理上,不论是全连接层的更新还是卷积层的更新,使用的都是经典的反馈神经网络算法,这种方法较原本较为复杂的......

从图像分类到图像分割
卷积神经网络(CNN)自2012年以来,在图像分类和图像检测等方面取得了巨大的成就和广泛的应用。
CNN的强大之处在于它的多层结构能自动学习特征,并且可以学习到多个层次的特征:较浅的卷积层感知域较小,学习到一些局部区域的特征;较深的卷积层具有较大的感知域,能够学习到更加抽象一些的特征。这些抽象特征对物体的大小、位置和方向等敏感性更低,从而有助于识别性能的提高。
这些抽象的特征对分类很有帮助,可以很好地判断出一幅图像中包含什么类别的物体,但是因为丢失了一些物体的细节,不能很好地给出物体的具体轮廓、指出每个像素具体属于哪个物体,因此做到精确的分割就很有难度。
传统的基于CNN的分割方法的做法通常是:为了对一个像素分类,使用该像素周围的一个图像块作为CNN的输入用于训练和预测。

卷积神经网络(Convolution Neural Network,CNN)已经在许多计算机视觉(Computer Vision)任务上取得了成功。 对于可视化,CNN 可以怎么应用于图形感知任务? 这篇文章 [1] 通过复制 Cleveland 和 McGill 的1984年的开创性实验 [2] 来研究这个问题,该实验测量了不同视觉编码的人类感知效率,并定义了可视化的基本感知任务。 我们在五种不同的可视化任务上测量了四种网络架构的图形感知功能,并与现有人的感知能力进行比较。 虽然在有限的情况下 CNN 能够达到或超越人工任务表现,但我们发现 CNN 目前还不是人类图形感知的良好模型。 我们提供这些实验的结果,以促进理解 CNN 在应用于数据可视化时的成功和失败。
这篇文章为了确定CNN模型来拟合人类对图形的感知能力,文章中主要用了四种模型来进行实验:多层感知机、LeNet、VGG19、Xception。
下面是具体的模型结构:

作者:魏秀参
本文将以 Alex-Net、VGG-Nets、Network-In-Network 为例,分析几类经典的卷积神经网络案例。
在此请读者注意,此处的分析比较并不是不同网络模型精度的“较量”,而是希望读者体会卷积神经网络自始至今的发展脉络和趋势。
这样会更有利于对卷积神经网络的理解,进而举一反三,提高解决真实问题的能力。
01:Alex-Net 网络模型
Alex-Net 是计算机视觉领域中首个被广泛关注并使用的卷积神经网络,特别是 Alex-Net 在 2012 年 ImageNet 竞赛 中以超越第二名 10.9个百分点的优异成绩一举夺冠,从而打响了卷积神经网络乃至深度学习在计算机视觉领域中研究热潮的“第一枪”。
Alex-Net 由加拿大多伦多大学的 Alex Krizhevsky、Ilya Sutskever(G. E. Hinton 的两位博士生)和 Geoffrey E. Hinton 提出,网络名“Alex-Net”即 取自第一作者名。
关于 Alex-Net 还有一则八卦:由于 Alex-Net 划时代的意义,并由此开启了深度学习在工业界的应用。
Image Restoration Using Very Deep Convolutional Encoder-Decoder Networks with Symmetric Skip Connections
作者:Xiao-Jiao Mao、Chunhua Shen等
本文提出了一个深度的全卷积编码-解码框架来解决去噪和超分辨之类的图像修复问题。网络由多层的卷积和反卷积组成,学习一个从受损图像到原始图像的端到端的映射。卷积层负责特征提取,捕获图像内容的抽象信息,同时消除噪声/损失。相对应,反卷积层用来恢复图像细节。
网络结构
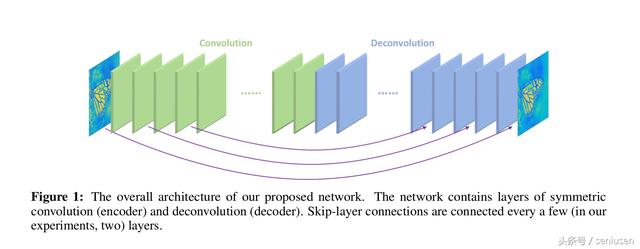
在底层图像修复领域,由于池化操作会丢失有用的图像细节信息,因此,本网络没有用到池化层,是一个全卷积的网络结构。
卷积层的特征图和与之相应成镜像关系的反卷积层特征图进行跳跃连接,对应像素直接相加后经过非线性激活层然后传入下一层。