卷积神经网络是如何实现不变性特征提取的
demi 在 周一, 02/17/2020 - 16:17 提交
传统的图像特征提取(特征工程)主要是基于各种先验模型,通过提取图像关键点、生成描述子特征数据、进行数据匹配或者机器学习方法对特征数据二分类/多分类实现图像的对象检测与识别。卷积神经网络通过计算机自动提取特征(表示工程)实现图像特征的提取与抽象,通过MLP实现数据的回归与分类。二者提取的特征数据都具不变性特征。
卷积神经网络(CNN)是一种深度学习算法,特别擅长处理图像和视频数据。它通过模拟生物视觉系统的方式,利用卷积层、池化层等多层网络结构自动提取图像中的特征,进行分类、识别和预测。CNN被广泛应用于计算机视觉任务,如图像分类、人脸识别、物体检测等,已成为深度学习领域的重要模型之一。
传统的图像特征提取(特征工程)主要是基于各种先验模型,通过提取图像关键点、生成描述子特征数据、进行数据匹配或者机器学习方法对特征数据二分类/多分类实现图像的对象检测与识别。卷积神经网络通过计算机自动提取特征(表示工程)实现图像特征的提取与抽象,通过MLP实现数据的回归与分类。二者提取的特征数据都具不变性特征。

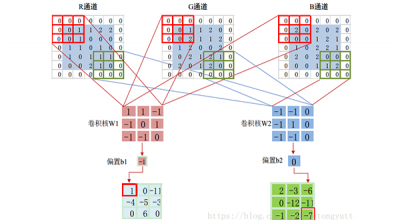
卷积神经网络由输入层,卷积层,激活函数,池化层,全连接层组成。卷积操作是使用一个二维的卷积核在一个批处理的图片上进行不断扫描。具体操作是将一个卷积核在每张图片上按照一个合适的尺寸在每个通道上面进行扫描。

现如今,卷积神经网络在人工智能领域应用的广泛性及重要性可谓是不言而喻。为了让大家对卷积的类型有一个清晰明了的认识,可以快速概述不同类型的卷积及其好处。在这里绘制了动图,以方便大家的学习(仅关注二维卷积)。

卷积层(Convolutional layer)主要是用一个采样器从输入数据中采集关键数据内容;池化层(Pooling layer)则是对卷积层结果的压缩得到更加重要的特征,同时还能有效控制过拟合。
关于深度卷积神经网络的前世今生,就不在此处进行过多的介绍。在此,主要对网络的各个组成部分进行简要介绍。深度卷积神经网络主要是由输入层、卷积层、激活函数、池化层、全连接层和输出层组成。

卷积神经网络(也称作 ConvNets 或 CNN)是神经网络的一种,它在图像识别和分类等领域已被证明非常有效。 卷积神经网络除了为机器人和自动驾驶汽车的视觉助力之外,还可以成功识别人脸,物体和交通标志。

池化(Pooling)是卷积神经网络中另一个重要的概念,它实际上是一种形式的降采样。有多种不同形式的非线性池化函数,而其中“最大池化(Max pooling)”是最为常见的。它是将输入的图像划分为若干个矩形区域,对每个子区域输出最大值。

在卷积神经网络中,感受野(Receptive Field)的定义是卷积神经网络每一层输出的特征图(feature map)上的像素点在输入图片上映射的区域大小。再通俗点的解释是,特征图上的一个点对应输入图上的区域......

卷积神经网络的训练过程分为两个阶段。第一个阶段是数据由低层次向高层次传播的阶段,即前向传播阶段。另外一个阶段是,当前向传播得出的结果与预期不相符时,将误差从高层次向底层次进行传播训练的阶段,即反向传播阶段。

卷积神经网络的卷积核大小、卷积层数、每层map个数都是如何确定下来的呢?看到有些答案是刚开始随机初始化卷积核大小,卷积层数和map个数是根据经验来设定的,但这个里面应该是有深层次原因吧?