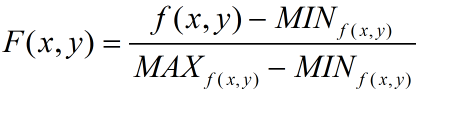机器学习(十)—聚类算法(KNN、Kmeans、密度聚类、层次聚类)
demi 在 周二, 11/13/2018 - 10:11 提交
聚类算法
任务:将数据集中的样本划分成若干个通常不相交的子集,对特征空间的一种划分。
性能度量:类内相似度高,类间相似度低。两大类:1.有参考标签,外部指标;2.无参照,内部指标。
距离计算:非负性,同一性(与自身距离为0),对称性,直递性(三角不等式)。包括欧式距离(二范数),曼哈顿距离(一范数)等等。
1、KNN
k近邻(KNN)是一种基本分类与回归方法。
其思路如下:给一个训练数据集和一个新的实例,在训练数据集中找出与这个新实例最近的k 个训练实例,然后统计最近的k 个训练实例中所属类别计数最多的那个类,就是新实例的类。其流程如下所示:
1、计算训练样本和测试样本中每个样本点的距离(常见的距离度量有欧式距离,马氏距离等);
2、对上面所有的距离值进行排序;
3、选前k 个最小距离的样本;
4、根据这k 个样本的标签进行投票,得到最后的分类类别;
KNN的特殊情况是k =1 的情况,称为最近邻算法。对输入的实例点(特征向量)x ,最近邻法将训练数据集中与x 最近邻点的类作为其类别。