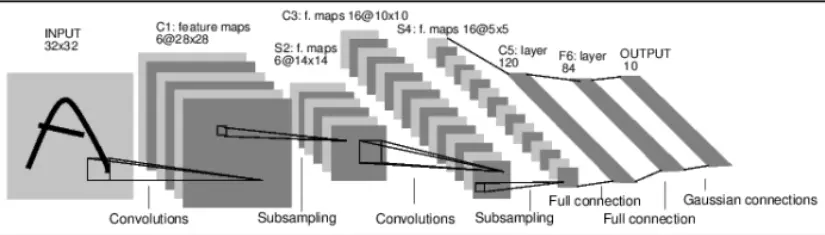
[深度学习]不平衡样本的处理
demi 在 周五, 09/28/2018 - 10:35 提交
机器学习中经典假设中往往假定训练样本各类别是同等数量即各类样本数目是均衡的,但是真实场景中遇到的实际问题却常常不符合这个假设。一般来说,不平衡样本会导致训练模型侧重样本数目较多的类别,而“轻视”样本数目较少类别,这样模型在测试数据上的泛化能力就会受到影响。一个例子,训练集中有99个正例样本,1个负例样本。在不考虑样本不平衡的很多情况下,学习算法会使分类器放弃负例预测,因为把所有样本都分为正便可获得高达99%的训练分类准确率。
下面将从“数据层面“和”算法层面“两个方面介绍不平衡样本问题。
数据层面处理办法
数据层面处理方法多借助数据采样法使整体训练集样本趋于平衡,即各类样本数基本一致。
数据重采样