0x00、概述
本文主要是和大家介绍一下:
1. 回顾Machine Learning分类器方法。
• 特征码提取自动化
• 数据集介绍
• n-gram N如何获取
• 特征选择
• 算法评估
2. Deep Learning分类器
• 为什么有Machine Learning还需要Deep Learning。
• 如何实现Deep Learning的方法。
• 效果验证。
0x01、Machine Learning分类器回顾
通常适用的两种主要方法恶意软件检测包括:静态分析和动态分析。我们这里先阐述静态分析。前面的几篇文章都已经阐述了目前静态分析主要是反汇编程序的原始操作码序列,使用N-gram提取特征。这种分类器的优势在于是能够直接从原始数据中自动学习特征,而不是事先通过专家分析来指定它们。当然在抽取反汇编程序的原始操作码序列当在N-gram提取特征提的时候,我们发现原始操作码的频率也是一个影响整个恶意软件分类判断的重要特征。
1、数据集介绍
为了更真实的模拟实际生产环境,在云平台搭建了一个IDS,通过IDS的文件还原功能,获取到了海量的样本,同时,使用静态特征检测的手段(传统杀毒软件)对恶意样本进行自动化标注,同时把样本输入到特征码提取自动化处理流程中。大致的数据流程图如下:
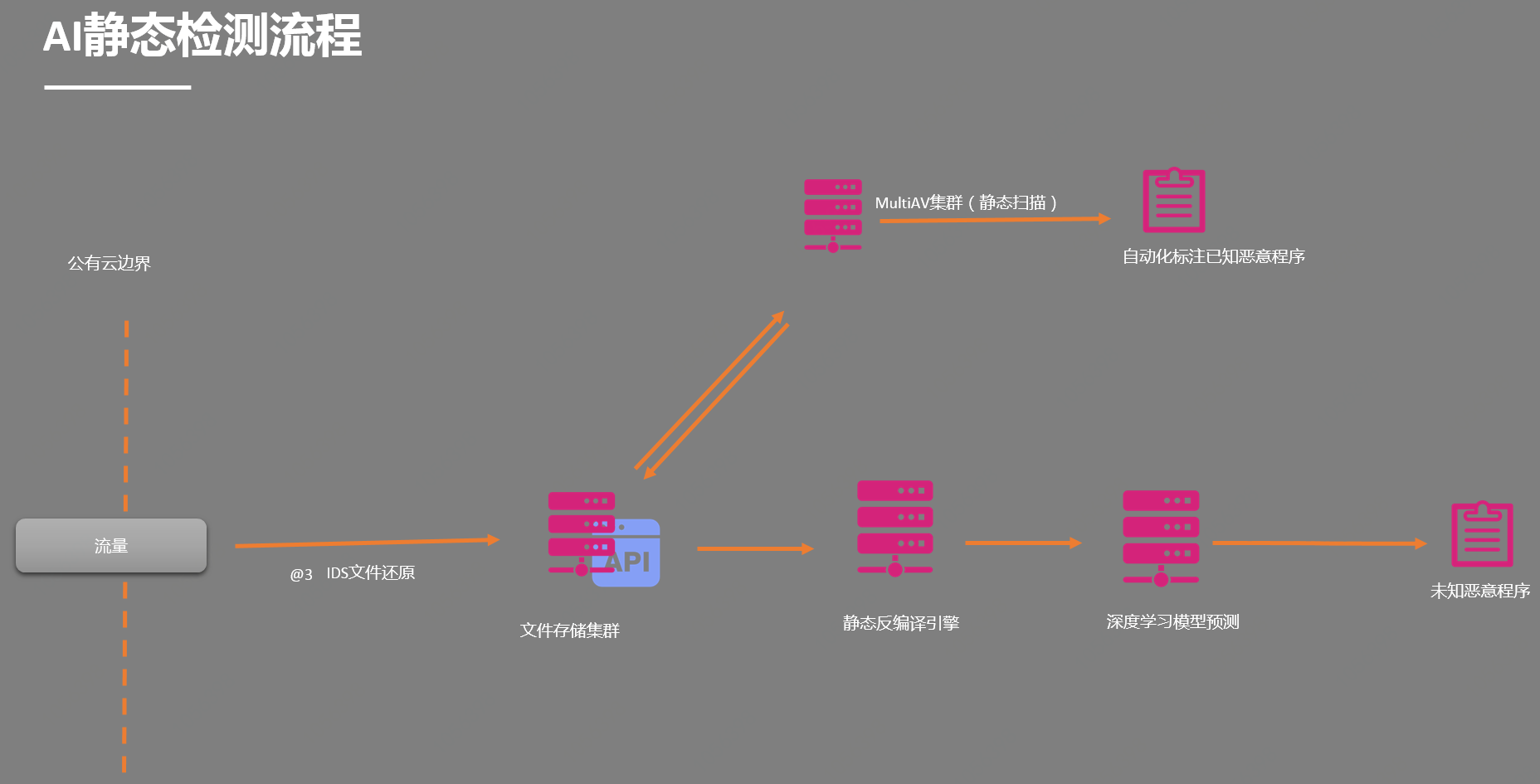
2、特征码提取自动化
https://github.com/viper-framework/viper 启动反汇编程序(IDA Pro) -> 统计频率
IDA分析完文件之后,会自动在文件目录下生成一个idb数据库文件,数据库文件以输入进行分析文件去掉后缀之后的文件名进行命名。但是因为本次实验中使用的数据集很多文件只是后缀有区别,前面文件名相同,所以要以完整文件名保存相应的分析结果。这种情况下,自定义idc脚本来完成分析后期工作比较方便。
下面是使用到的DIYanalysis.idc脚本,保存在ida目录下的idc文件夹
include <idc.idc>
static main()
{
SetShortPrm(INF_AF2, GetShortPrm(INF_AF2) | AF2_DODATA);
Message("Waiting for the end of the auto analysis...\n");
Wait();
Message("\n\n------ Creating the output file.... --------\n");
auto file = GetInputFilePath();
auto asmfile = file + ".asm";
auto idbfile = file + ".idb";
WriteTxt(asmfile, 0, BADADDR);
SaveBase(idbfile, 0);
Message("All done, exiting...\n");
Exit(0);
}
运行效果
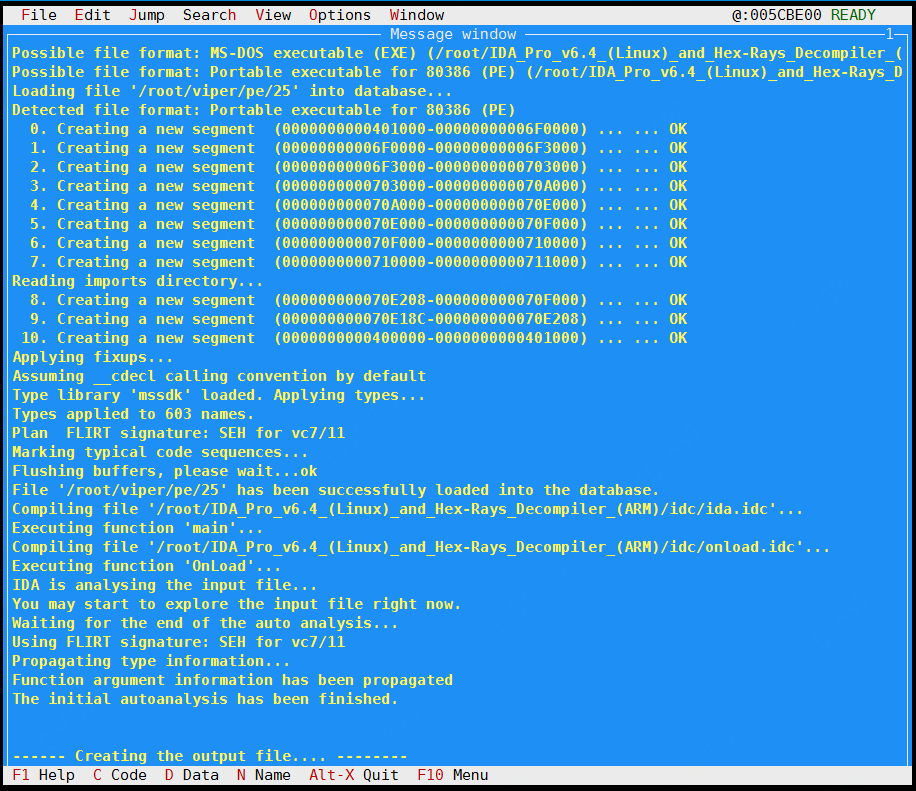
备注:在运行的过程中,这个时间稍微长一些,大约1~3分钟不等。所以,我只挑了2380个恶意样本和2380个良性样本。
3、n-gram N如何获取
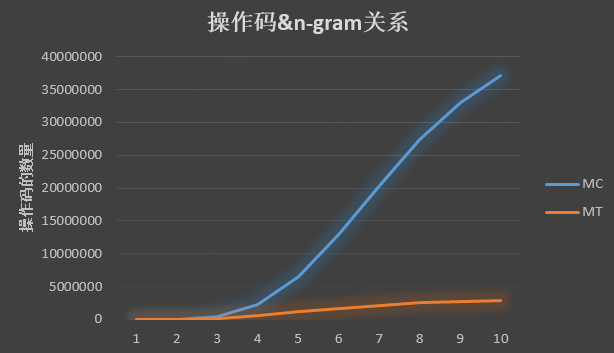
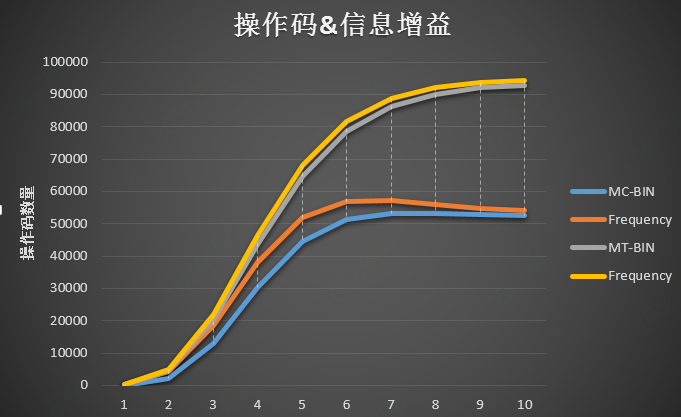
当n增加时,任何基于n-gram的方法都面临着独特n-gram数量呈指数增长的前景。 预计在n操作码中也会观察到类似的趋势。 图2和表I显示了来自我们的数据集的不同n的唯一n-操作码的数量,其包括2380个恶意软件样本和2380个良性样本。 在恶意软件分类(MC)研究中,我们处理了所有4760个样本的n-opcode提取,并计算了不同n的唯一n-opcodes的数量,n为1到10。
mc:malware classification
mt:malware categorization
4、特征选择
由于唯一n-opcode的数量过多,因此很难在原始数据上运行机器学习算法。 该问题的解决方案之一是特征选择,即识别最佳特征的过程,并且是过滤掉不太重要的特征的广泛使用的方法。 在特征选择阶段,我们测量每个特征的信息增益,然后滤除具有最低信息增益的不太重要的特征。熵是随机变量的不确定性的度量。 变量X的熵在下面的(1)中定义 观察变量Y的值后的X的熵在(2)中定义,其中P(xi)是X和P的所有值的先验概率(xi | yi)是给定值的X的后验概率。Y.
5、算法评估
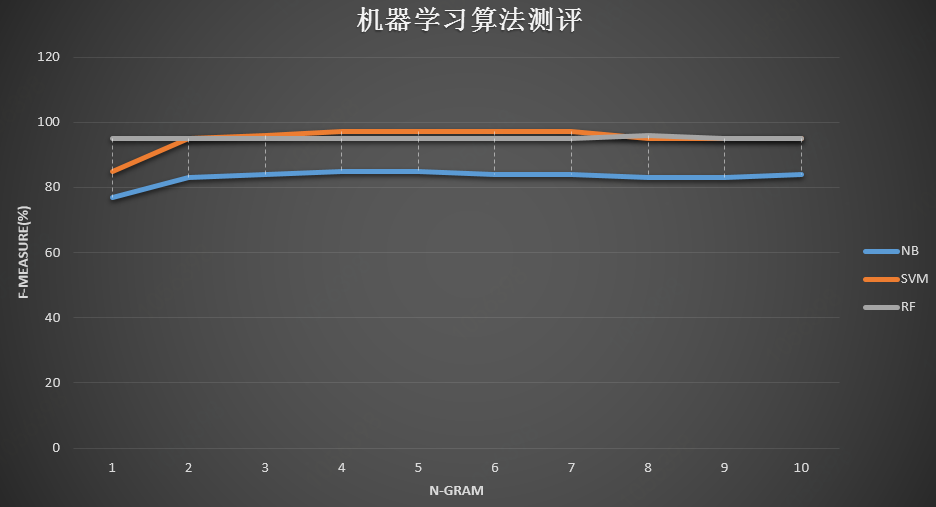
我们使用三种不同的机器学习算法:Naïve贝叶斯(NB),支持向量机(SVM),随机森林(RF)并利用公有云机器学习框架评估。报告了以下实验结果使用加权平均f-度量,它基于精确度和召回率。
具体实现方法,在单机下运行scikit-learn 中相应的SVM等分类方法。结论是SVM占上风。
用同样的方法使用深度学习做一下评估
最重要的部分来了,我们使用深度学习架构对其进行分类,看看效果。
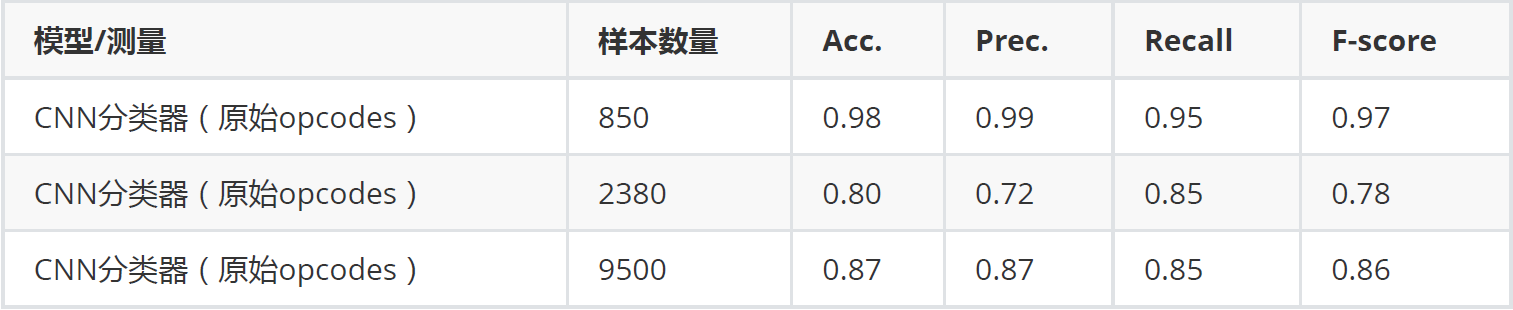
从简单的数据上看,目前深度学习效果不稳定,主要是还没有找到特征。
0x02、Deep Learning分类器
1、提升准确率和性能
在做这个实验的时候我发现一个问题,其实在沙箱上跑一个恶意软件的时间也是2-3分钟,而且可以躲避那些牛逼的加密混淆手段,那么,我们为啥不换一个思路呢?
2、具体做法
@1、提取特征
我们通过Cuckoo sandbox运行的结果会产生report.json文件提取APICall
"apistats": {
"2208": {
"CreateToolhelp32Snapshot": 1,
"LdrUnloadDll": 2,
"NtOpenSection": 1,
"GetAdaptersInfo": 2,
"RegCloseKey": 1,
"GetSystemInfo": 1,
"RegQueryValueExA": 2,
"IsDebuggerPresent": 1,
"NtClose": 15,
"RegCreateKeyExA": 1,
"GetFileAttributesW": 2,
"NtFreeVirtualMemory": 6,
"Process32NextW": 45,
"GetSystemMetrics": 3,
"SizeofResource": 3,
"CreateActCtxW": 4,
"SetFileTime": 1,
"NtDelayExecution": 1,
"SetErrorMode": 1,
"NtAllocateVirtualMemory": 10,
"RegOpenKeyExA": 11,
"DeleteFileW": 1,
"NtWriteFile": 1,
"NtMapViewOfSection": 3,
"Process32FirstW": 1,
"NtOpenFile": 24,
"SetUnhandledExceptionFilter": 1,
"__exception__": 1,
"NtCreateFile": 3,
"GetSystemTimeAsFileTime": 1,
"GetComputerNameA": 1,
"NtQueryAttributesFile": 1,
"NtCreateMutant": 2,
"NtProtectVirtualMemory": 8,
"LdrGetDllHandle": 2,
"NtCreateSection": 2,
"LoadStringW": 2,
"NtOpenKey": 1,
"NtOpenMutant": 3,
"LoadResource": 3,
"LdrGetProcedureAddress": 15,
"RegSetValueExA": 4,
"CopyFileA": 1,
"SetFileAttributesW": 1,
"LdrLoadDll": 6,
"FindResourceA": 3,
"NtQueryInformationFile": 1,
"CreateProcessInternalW": 1,
"NtQueryValueKey": 1
},
"1896": {
"RegCreateKeyExW": 4,
"LdrUnloadDll": 1,
"RegCloseKey": 4,
"NtTerminateProcess": 3,
"NtClose": 41,
"RegCreateKeyExA": 1,
"SizeofResource": 2,
"SetFileTime": 1,
"NtReadFile": 6,
"NtWriteFile": 18,
"LdrGetDllHandle": 4,
"NtAllocateVirtualMemory": 4,
"SetFilePointer": 4,
"NtCreateFile": 7,
"NtQueryAttributesFile": 1,
"RegSetValueExW": 4,
"NtOpenKey": 1,
"SearchPathW": 1,
"LoadResource": 2,
"LdrGetProcedureAddress": 2,
"GetFileType": 2,
"FindResourceA": 2,
"NtQueryInformationFile": 1,
"CreateProcessInternalW": 1,
"NtQueryValueKey": 1
},
"2104": {
"NtCreateSection": 1,
"SearchPathW": 1,
"LoadStringW": 2,
"SetUnhandledExceptionFilter": 1,
"SetErrorMode": 1,
"NtCreateFile": 1,
"NtClose": 2,
"GetSystemTimeAsFileTime": 1,
"LdrLoadDll": 1,
"GetFileAttributesW": 1,
"NtMapViewOfSection": 1
}提取api统计信息
@2、数据预处理
在使用API调用序列作为神经网络的输入之前,我们需要将数据转换为数字特征序列向量。
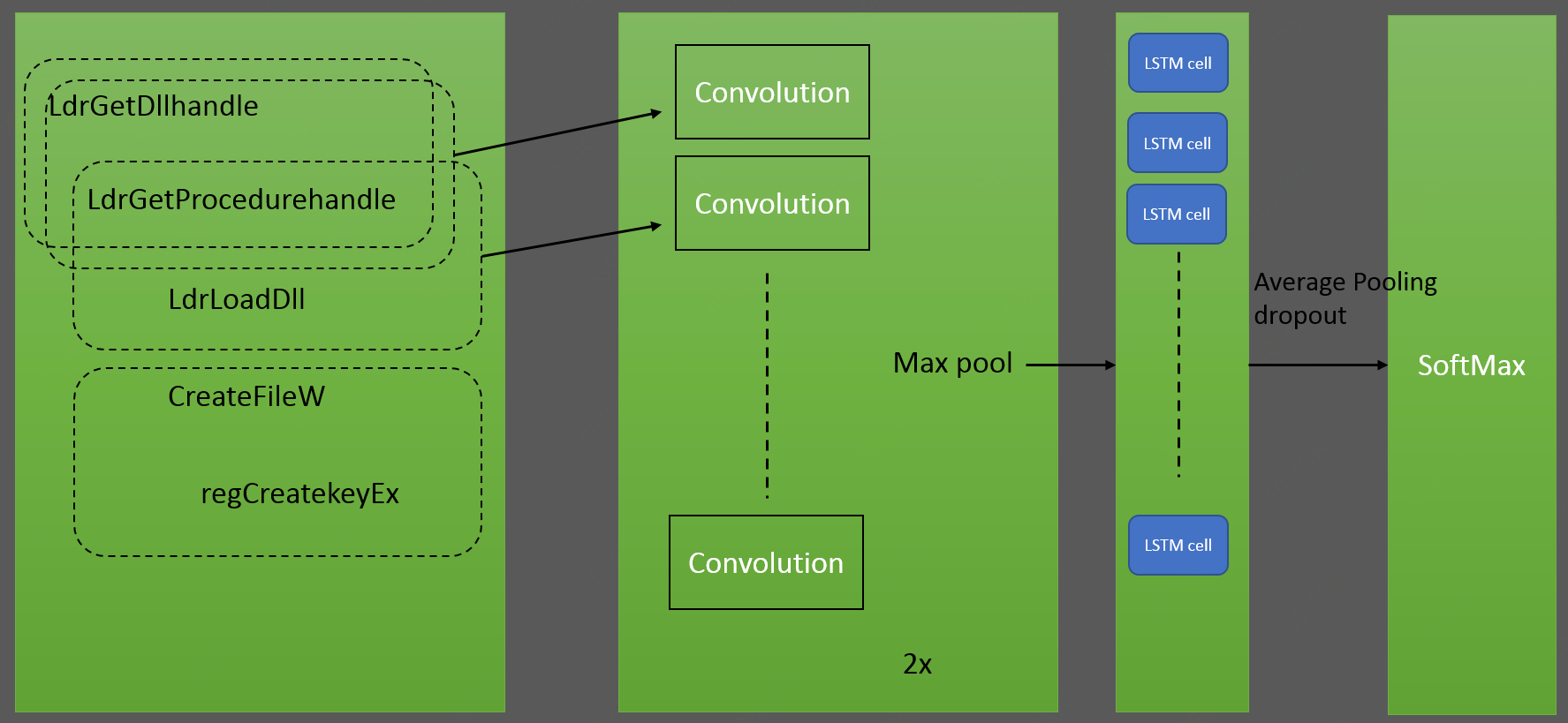
为了最大限度地利用神经网络给出的可能性方法论,我们将卷积和复发层结合在一个神经元中网络。图2描绘了我们的神经网络架构。卷积部分由卷积和池化层组成。一方面是卷积的层用于从原始单热矢量中提取特征。卷积 捕获相邻输入向量之间的相关性并产生新的特征。我们使用两个大小为3×60的卷积滤波器,相当于3-gram。作为卷积的结果,我们采用大小的特征向量对于每个输入特征,第一和第二卷积层的图10和20示出。后每个卷积层我们使用max-pooling来减少维数数据为两倍。我们的神经网络的卷积部分的输出连接到经常性部分。我们转发卷积的每个输出过滤器作为一个向量。使用LSTM细胞对得到的序列进行建模。我们使用LSTM cell,因为它们在训练方面很灵活,即使是最大序列长度限制为200个API Call。使用重复层我们能够在内核API中显式建模顺序依赖项痕迹。均值池用于从中提取最重要的特征LSTM输出并降低了进一步数据处理的复杂性。此外,我们使用Dropout来防止过度拟合和softmax层输出标签概率

3、效果验证
在本文中,我们构建深度神经网络以改进建模和分类系统调用序列。 通过结合卷积和复发在一个神经网络架构中,我们获得最佳分类结果。使用包含两个卷积层的混合神经网络一个复发层我们得到了一种新的恶意软件分类方法。 我们的神经网络不仅胜过其他更简单的神经架构,而且还胜过以前广泛使用的隐马尔可夫模型和支持向量机。总的来说,与之相比,我们的方法表现出更好的性能。
转自:嘶吼
原文地址: http://www.4hou.com/technology/13788.html