一文读懂机器学习的6种优化方法:提升模型性能的关键路径
demi 在 周二, 03/25/2025 - 17:15 提交
随着数据量的爆发式增长和模型复杂度的不断提升,如何高效地调整模型参数,使模型性能达到最优,成为了研究者和从业者关注的核心问题。
随着数据量的爆发式增长和模型复杂度的不断提升,如何高效地调整模型参数,使模型性能达到最优,成为了研究者和从业者关注的核心问题。

我们在训练网络的时候经常会设置 batch_size,这个 batch_size 究竟是做什么用的,一万张图的数据集,应该设置为多大呢,设置为 1、10、100 或者是 10000 究竟有什么区别呢?

众所周知,梯度下降算法是机器学习中使用非常广泛的优化算法,也是众多机器学习算法中最常用的优化方法。几乎当前每一个先进的(state-of-the-art)机器学习库或者深度学习库都会包括梯度下降算法的不同变种实现。但是,它们就像一个黑盒优化器,很难得到它们优缺点的实际解释。

传统的梯度下降,每次梯度下降都是对所有的训练数据进行计算平均梯度,这种梯度下降法叫做full-batch梯度下降法。考虑一种情况,当训练数据量在千万级别时,一次迭代需要等待多长时间,会极大的降低训练速度。

我们在训练神经网络模型时,最常用的就是梯度下降,这篇博客主要介绍下几种梯度下降的变种(mini-batch gradient descent和stochastic gradient descent),这里主要介绍Mini-batch gradient descent和stochastic gradient descent(SGD)以及对比下Batch gradient descent、mini-batch gradient descent和stochastic gradient descent的效果。

梯度下降方法是机器学习中常用的参数求解方法。本文将从四个方面为大家详细介绍梯度下降的算法理论,具体包括:① 梯度下降方法原理;② 关于梯度,为什么负梯度方向是下降最大方向?③ 实践,以回归分析为例;④ 梯度下降的其他问题。

梯度下降的框架主要分三种:1,全量梯度下降:每次使用全部的样本来更新模型参数,优点是收敛方向准确,缺点是收敛速度慢,内存消耗大。;2,随机梯度下降:每次使用一个样本来更新模型参数,优点是学习速度快,缺点是收敛不稳定。;3,批量梯度下降:每次使用一个batchsize的样本来更新模型参数,平衡了全量梯度下降和随机梯度下降的方法。。

最优化问题是机器学习算法中非常重要的一部分,很多机器学习算法的核心都是在处理最优化问题。梯度下降法(gradient descent)是一种常用的一阶(first-order)优化方法,是求解无约束问题最简单、最经典的方法之一。
在应用机器学习算法时,我们通常采用梯度下降法来对采用的算法进行训练。其实,常用的梯度下降法还具体包含有三种不同的形式,它们也各自有着不同的优缺点。
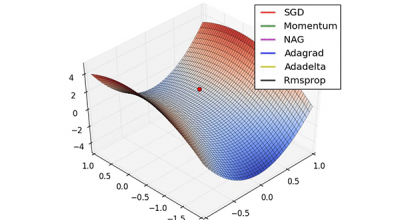
梯度下降法,是当今最流行的优化(optimization)算法,亦是至今最常用的优化神经网络的方法。本文旨在让你对不同的优化梯度下降法的算法有一个直观认识,以帮助你使用这些算法。我们首先会考察梯度下降法的各种变体,然后会简要地总结在训练(神经网络或是机器学习算法)的过程中可能遇到的挑战。