成为一名机器学习算法工程师,你需要这些必备技能!
demi 在 周五, 01/18/2019 - 14:44 提交
成为一名合格的开发工程师不是一件简单的事情,需要掌握从开发到调试到优化等一系列能力,这些能力中的每一项掌握起来都需要足够的努力和经验。而要成为一名合格的机器学习算法工程师(以下简称算法工程师)更是难上加难,因为在掌握工程师的通用技能以外,还需要掌握一张不算小的机器学习算法知识网络。
下面我们就将成为一名合格的算法工程师所需的技能进行拆分,一起来看一下究竟需要掌握哪些技能才能算是一名合格的算法工程师。
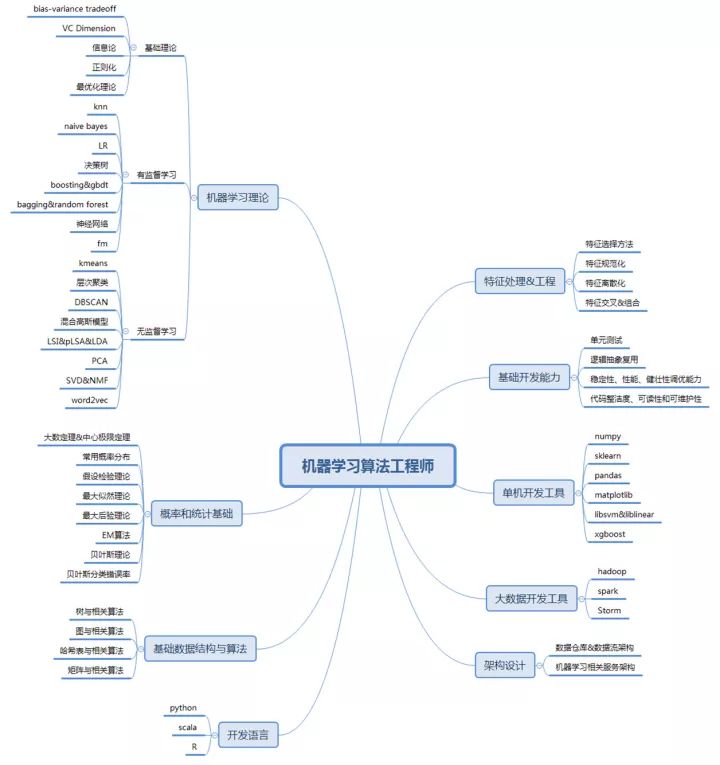
基础开发能力