5G与物联网的强强联合,会带来哪些新的机遇?
demi 在 周三, 10/31/2018 - 16:04 提交
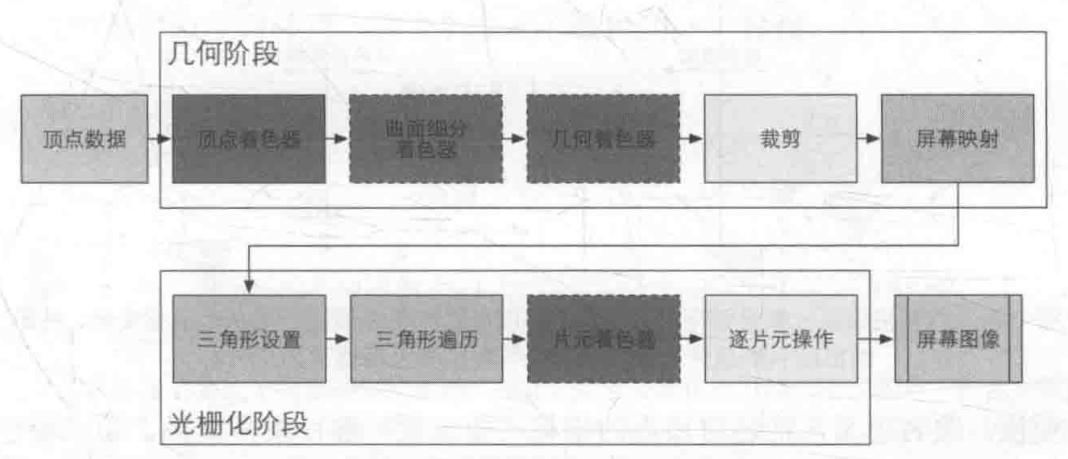
谈到5G网络,相信很多人都没有很清晰的认知,因为目前5G网络在中国市场还没有真正应用,那么它和4G、2/3G网络有什么区别?最明显的区别就是速率,当4G网络在2010年左右开始占领市场的时候,我们会觉得速度变得很快,下载一部电影,传送一个视频、文件或者照片等,终于不用像2/3G网络那样苦苦等待了,不过,这些在5G网络面前都不算什么,那么,我们即将面世的5G网络到底有多快呢?据悉,它的峰值理论传输速度可达每秒数10Gb,可以说一部超高清画质电影可在1秒之内下载完成,5G作为第五代移动通信技术,将把移动市场推到一个全新的高度。
那5G什么时候能真正到来呢?目前,日本、韩国、美国和中国等国家以及欧洲都在积极研究5G技术,寻找关键技术的突破点。5G技术的关键技术多达6项,其中包括大规模天线阵列技术或新型多天线技术、超密集组网技术、新型多址技术、D2D通信技术、更加扁平化的新型网络架构和C-RAN研究、高频段需求潜在候选频段研究。如此艰巨的任务给各个国家都带来了挑战,而一些5G技术已经开始测试,如AT&T和Verizon正在测试家庭和企业5G宽带固定网络。