基于深度卷积神经网络和跳跃连接的图像去噪和超分辨
demi 在 周三, 12/12/2018 - 11:33 提交
Image Restoration Using Very Deep Convolutional Encoder-Decoder Networks with Symmetric Skip Connections
作者:Xiao-Jiao Mao、Chunhua Shen等
本文提出了一个深度的全卷积编码-解码框架来解决去噪和超分辨之类的图像修复问题。网络由多层的卷积和反卷积组成,学习一个从受损图像到原始图像的端到端的映射。卷积层负责特征提取,捕获图像内容的抽象信息,同时消除噪声/损失。相对应,反卷积层用来恢复图像细节。
网络结构
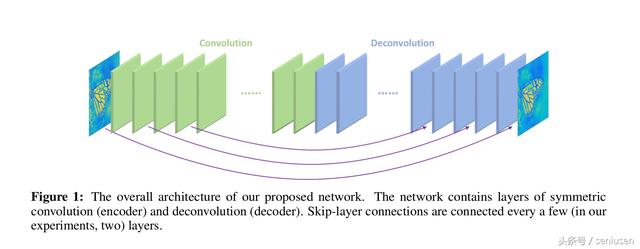
在底层图像修复领域,由于池化操作会丢失有用的图像细节信息,因此,本网络没有用到池化层,是一个全卷积的网络结构。
卷积层的特征图和与之相应成镜像关系的反卷积层特征图进行跳跃连接,对应像素直接相加后经过非线性激活层然后传入下一层。