各种卷积结构原理及优劣总结
demi 在 周二, 01/08/2019 - 10:06 提交
卷积神经网络作为深度学习的典型网络,在图像处理和计算机视觉等多个领域都取得了很好的效果。
Paul-Louis Pröve在Medium上通过这篇文章快速地介绍了不同类型的卷积结构(Convolution)及优势。为了简单起见,本文仅探讨二维卷积结构。
卷积
首先,定义下卷积层的结构参数。
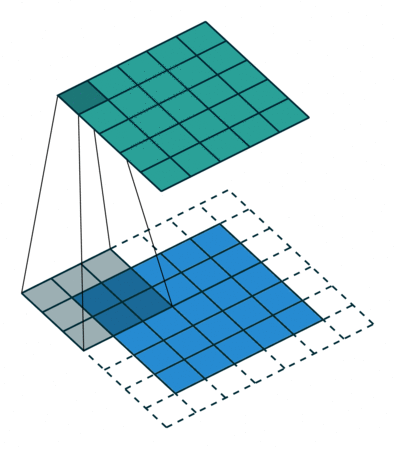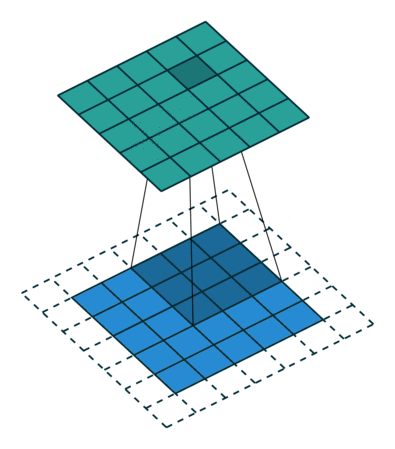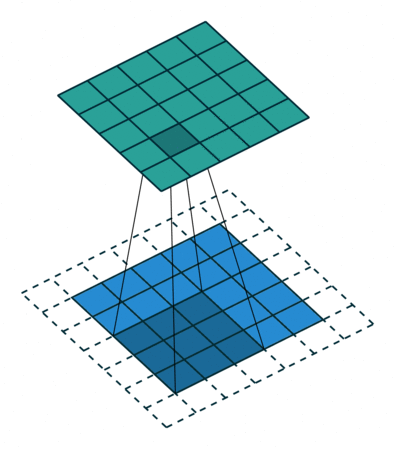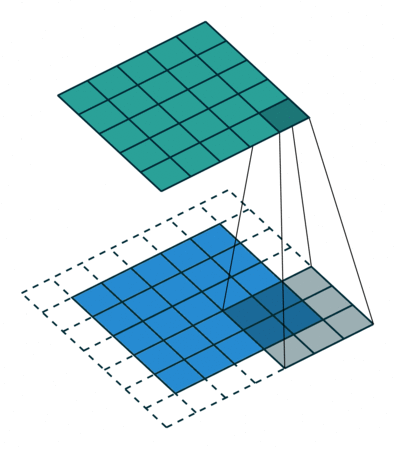
卷积核大小(Kernel Size):定义了卷积操作的感受野。在二维卷积中,通常设置为3,即卷积核大小为3×3。
步幅(Stride):定义了卷积核遍历图像时的步幅大小。其默认值通常设置为1,也可将步幅设置为2后对图像进行下采样,这种方式与最大池化类似。