循环神经网络中Dropout的应用
demi 在 周三, 09/26/2018 - 16:43 提交
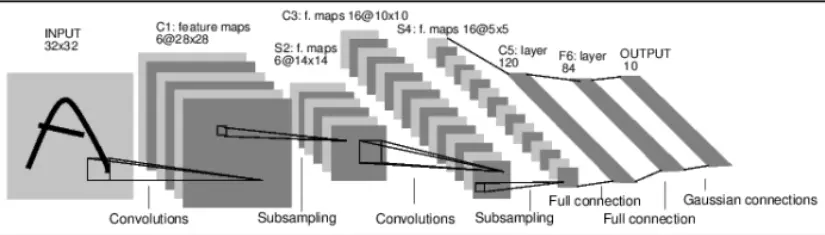
循环神经网络(RNNs)是基于序列的模型,对自然语言理解、语言生成、视频处理和其他许多任务至关重要。模型的输入是一个符号序列,在每个时间点一个简单的神经网络(RNN单元)应用于一个符号,以及此前时间点的网络输出。RNNs是强大的模型,在许多任务中表现出色,但会快速过拟合。RNN模型中缺少正则化使他难以处理小规模数据,为避免这种情况研究者经常使用提早停止,或者小规模的或未充分定义的模型。
Dropout是深度网络中常见的一种正则化技巧,在训练过程中网络单元随机的被隐藏/丢弃。但这种技巧在RNNs中一直未被成功应用。实证结果使很多人相信循环层(RNN单元之间的连接)中加入的噪音在长序列中会被放大,并淹没了信号。因此现存的研究认为这种技巧应仅用于RNN的输入和输出。但这种方式在研究中发现依然会导致过拟合。
最近贝叶斯和深度学习研究的交叉提供了一个从贝叶斯理解常见深度学习技巧的角度。这种深度学习中的贝叶斯观点也引入了一些新的技巧,例如从深度学习网络中获得主要非确定估计。例如Gal和Ghahramani展现了dropout可以被解释为一个贝叶斯神经网络后验的变体近似。它们的变体近似分布是两个小方差高斯的混合,平均数是一个高斯被固定在0。这种近似贝叶斯推论的dropout基础认为理论结果的延伸可为在RNN模型中使用该技巧提供见解。