作者: 张俊红
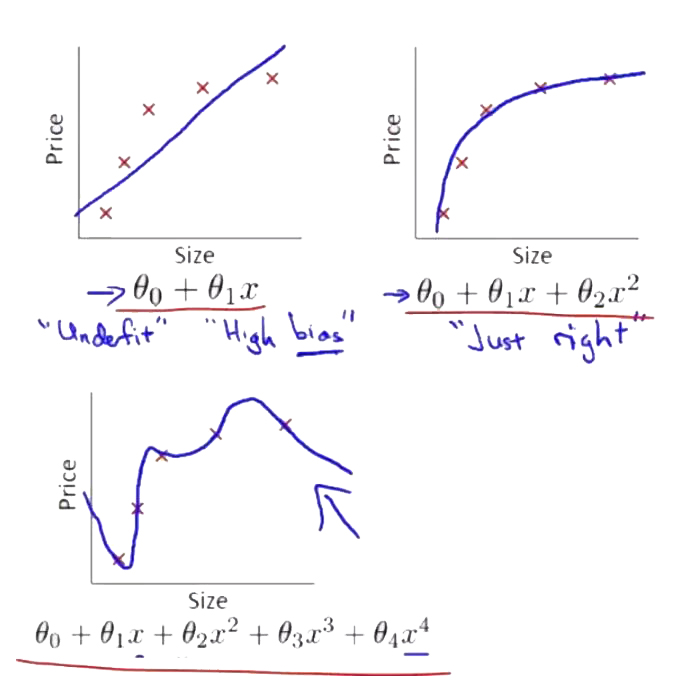
在机器学习中,同一个数据集可能训练出多个模型即多个函数(如下图所示,同样的数据集训练出三种不同的函数),那么我们在众多函数中该选择哪个函数呢?首选肯定是那个预测能力较好的模型,那么什么样的函数/模型就是预测好的呢?有没有什么评判标准?
损失函数和风险函数
前面说过我们应该首选那个预测能力较好的模型,那么该怎么判断预测能力的好坏呢?模型是用来做预测的,那么好的模型肯定是准确率较高的,也就是预测值和实际值之间的误差较小。
对于任一函数,我们给定一个x,函数都会输出一个f(X),这个输出的f(X)与真实值Y可能相同,也可能不同。我们用一个函数来度量这两者之间的相同度,这个函数称为损失函数(loss function),或者叫代价函数(cost function)。损失函数是一次的拟合结果,一次具有偶然性,所以又提出了另外一个概念-风险函数,或者叫期望损失,风险函数是用来度量平均意义下的模型预测能力的好坏。
经验风险与期望风险
模型F(X)关于训练集的平均损失称为经验风险或经验损失(因为训练集是历史数据,是以往的经验的数据,所以称为经验风险),记作Remp。
模型的输入、输出是随机变量,遵循联合概率分布P(X,Y)。期望风险是模型关于联合分布(即P(Y|X))的期望损失。但是联合分布我们又不知道,所以无法求得。这里引用大数定理,当样本容量足够大时,经验风险趋于期望风险,所以可以用经验风险来代替期望风险。
经验风险最小化和结构风险最小化
上面说过经验风险是用来表示整个训练集中所有预测值的预测差距,而经验风险最小化就是表示预测差距最小,而模型好坏的标准也是用预测好坏来评判的,所以我们认为经验风险最小化(预测差距最小)所对应的模型就是最优模型。
当样本容量很小时,经验风险最小化的效果就未必很好,会产生所谓的“过拟合”现象。而结构风险最小化就是为了防止过拟合而提出来的策略。
结构风险是在经验风险上加上表示模型复杂度的正则化项或罚项,正则化项有L1正则和L2正则,公式如下:
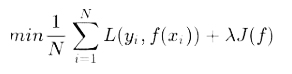
上面公式的前半部分是经验风险,后半部分是正则化项,J(f)是用来表示模型的复杂度,λ>=0是正则项系数,用来权衡经验风险和模型复杂度。
所以,监督学习问题就成了经验风险或结构风险函数最优化问题,而这时经验风险函数或结构风险函数就成了目标优化函数(因为有的时候不需要加正则项,这个时候就只需要看经验风险就好)。
常见的损失函数
1. 0-1损失函数:
0-1损失当预测值与实际值相等时,损失为0,预测值与实际值不相等时,损失为1。
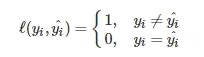
2. 平方损失函数
平方损失就是线性回归中的残差平方和,常用在回归模型中,表示预测值(回归值)与实际值之间的距离的平方和。
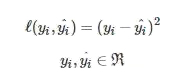
3. 绝对损失函数
绝对损失与平方损失类似,也主要用在回归模型中,表示预测值与实际值之间的距离。
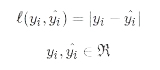
4. 指数损失函数
指数损失函数主要用在boosting算法模型中,具体公式如下:
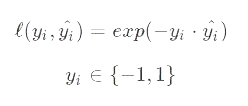
Yi表示实际样本分类,Yi=-1时为负样本,Yi=1时为正样本。
5. 对数损失函数
对数损失函数主要用在逻辑回归中,在逻辑回归模型中其实就是预测某个值分别属于正负样本的概率,而且我们希望预测为正样本的概率越高越好。具体模型为P(Y|X),在当前模型的基础上,对于样本X,其预测值为Y,也就是预测正确的概率。由概率乘法公式可得,概率之间可以相乘,为了将其转化为加法,我们将其取对数。最后由于是损失函数,所以预测正确的概率越高,其损失值应该是越小,因此再加个负号取个反。
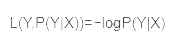
6. Hinge损失函数
Hinge损失主要用在SVM算法中,具体公式如下:
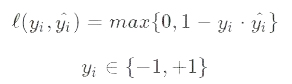
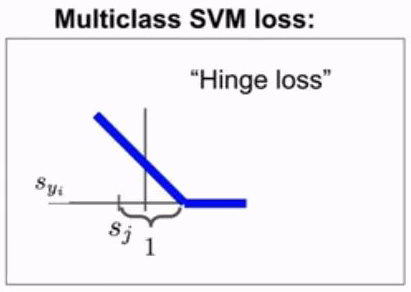
Yi表示样本真实分类,Yi=-1表示负样本,Yi=1表示正样本,Yi~表示预测的点到分离超平面的距离,当该距离大于1时,1与该距离做差为负值,此时损失为0,表示样本被被正确分类。反之,差值即为具体的损失。
7. 不同损失函数对比
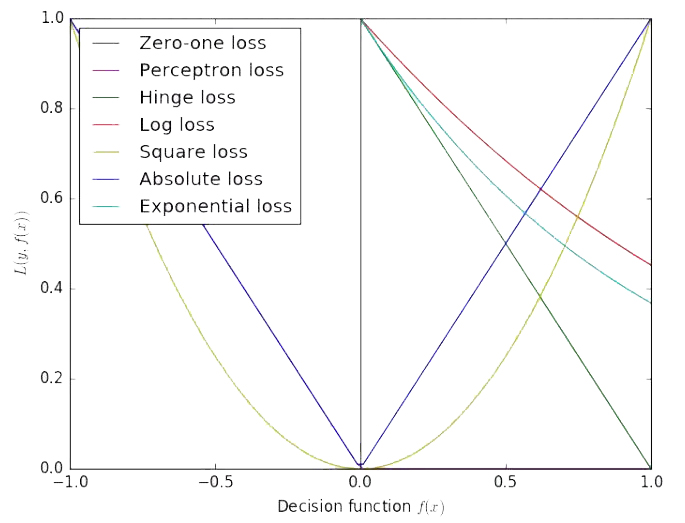
横轴表示真实(正确)分类样本的分数,纵轴表示损失大小,随着正确分类样本分数的增加,大部分决策函数的损失降低,绝对损失和平方损失会随着真实分类样本分数增加而损失又出现了增加。
转自:微信号 张俊红