汽车高级驾驶辅助系统ADAS全盘点
demi 在 周二, 12/11/2018 - 09:23 提交
相比目前还无法大规模应用的无人驾驶,高级辅助驾驶系统是一种把汽车变的更智能的实用技术。目前的车辆都带有驾驶辅助系统,广泛应用的倒车雷达,比较高端的远程召唤,都属于辅助驾驶。
随着造车新势力的崛起,互联网公司的介入,越来越多的高科技技术应用到了汽车上。ADAS作为汽车智能化的典型功能,备受关注。
01 自适应巡航控制系统 Adaptive Cruise Control(ACC)
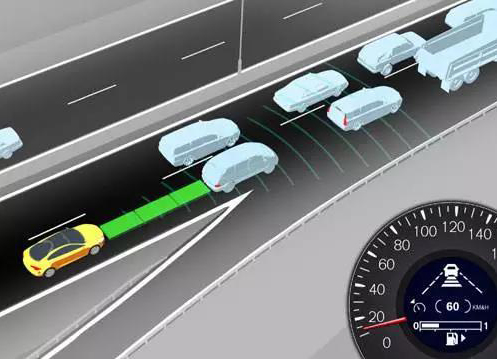
自适应巡航控制系统是一种智能化的自动控制系统,它是在早已存在的巡航控制技术的基础上发展而来的。
ACC的原理并不复杂。首先设置一个跟车距离,随后通过长距离毫米波雷达实时监测前方的汽车,通过对发动机和制动器的控制,使前车与自车始终保持在设定的距离。这样驾驶员就可以解放双脚。