作者:Jesus Garza
近年来,语音识别变得越来越重要:它使计算机能够将口语翻译成文本。它可以在不同类型的应用中找到,例如翻译器或隐藏字幕。以Mozilla的DeepSpeech 为例,它是一个开源的语音转文本引擎,其训练模型是基于百度深度语言研究论文的机器学习。我们将概述如何运行该模型的0.5.1版本,通过在Imagination神经网络加速器(NNA)上加速静态LSTM网络,为汽车应用创建语音助手原型。
首先,我们要考虑数据随时间推移而扩展的任务。例如,在视频中追踪人的轨迹,当目标人移动位置时,视频也会记录下不同的画面帧。而一些神经网络(比如一个典型的目标检测网络)面临的问题是,它们不记得之前的推断发生了什么,所以在连续两帧中检测一个人并不意味着它会记住这是同一个人。这意味着在某些情况下,我们需要注意发生在不同时间点的数据,因为它会影响结果。由于语音识别也是一个时间序列的任务,我们将使用一种特殊类型的神经网络来应对这一挑战:循环神经网络(RNN)。
为了记住过去发生的事情,RNN保持一个“hidden state”,这是对过去信息的一种表示。这允许数据通过推论流动,并对输出产生影响。除了我们需要的数据(我们使用的例子是一段音频),它还会被更新,以便下一步我们能够使用它。这样,在特定时间执行的数据对先前处理过的数据有一定的了解。然而,这些网络受到短期记忆的影响,在处理短期数据时效果更好。
长短期记忆(LSTM)网络是特定类型的RNN,在处理长数据序列时性能更好。它们有一个带有附加操作的单元,这些操作决定要忘记哪些信息、保留哪些信息以及更新哪些信息。在模型中,这作为一个“cell state”的额外输出返回,除了隐藏状态之外,它还被用作下一个推理的输入。下面是我们演示中的数据如何在网络中流动的概览:

在LSTM中发生的操作可以通过Imagination神经网络加速器来加速,在这个演示中,我们使用它来运行网络的静态实现,其已映射为NNA可以读取的格式。数据的预处理和后处理可以分别在GPU或CPU上完成。
对于音频输入源,我们可以使用麦克风实时数据流或音频文件。但神经网络期望的是音频以梅尔频率倒谱系数(MFCC)的序列,因此数据需要经过一系列的变换,例如:将其切割成多个帧,计算每帧的短时傅立叶变换(STFT)的幅度谱,将其映射到mel尺度,最后得到MFCC系数作为mel尺度谱图的对数的离散余弦变换(DCT)。完成这些步骤之后,由于我们使用的是RNN的静态版本,我们需要沿着时间维度移动预处理数据,以便每次执行网络时提供足够的数据。
除了源音频文件之外,我们还需要两种状态来维护信息:cell state(state C)和hidden state(state H)。因此,与音频数据一起,这些states也被用作输入,在执行期间,cell state和hidden state更新并返回推理的实际输出,它们可以在下一轮推理中使用。总之,每个推理需要三次输入,并返回三次输出——这样就可以随时间流动维持数据信息。
一个推断的输出包含字母表中每个字符在特定时间发生的概率(只有一个是最高概率)。在NNA返回所有MFCC系数的所有输出之后,我们最终得到了需要进行后处理的内容。为了将我们的概率转换成实际文本,我们使用了CTC解码算法,也可以对其调整以提高特定句子的准确识别。
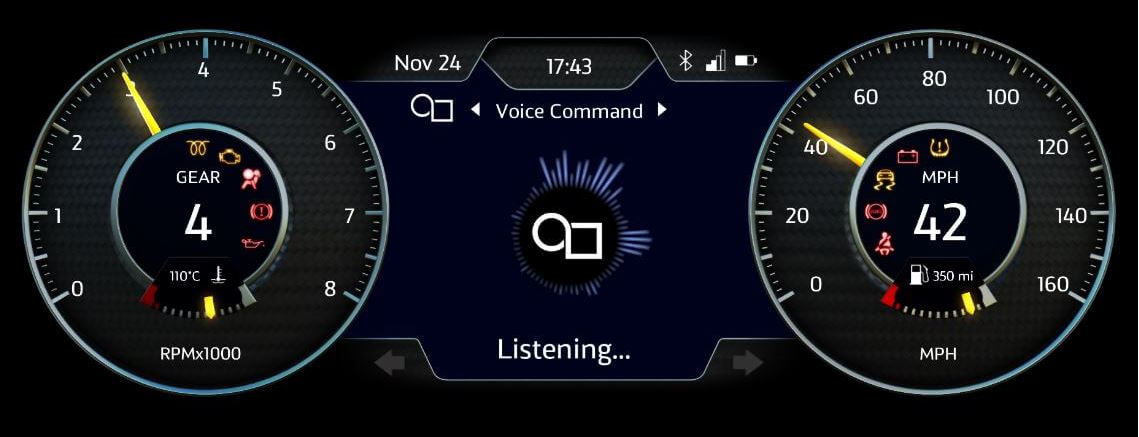
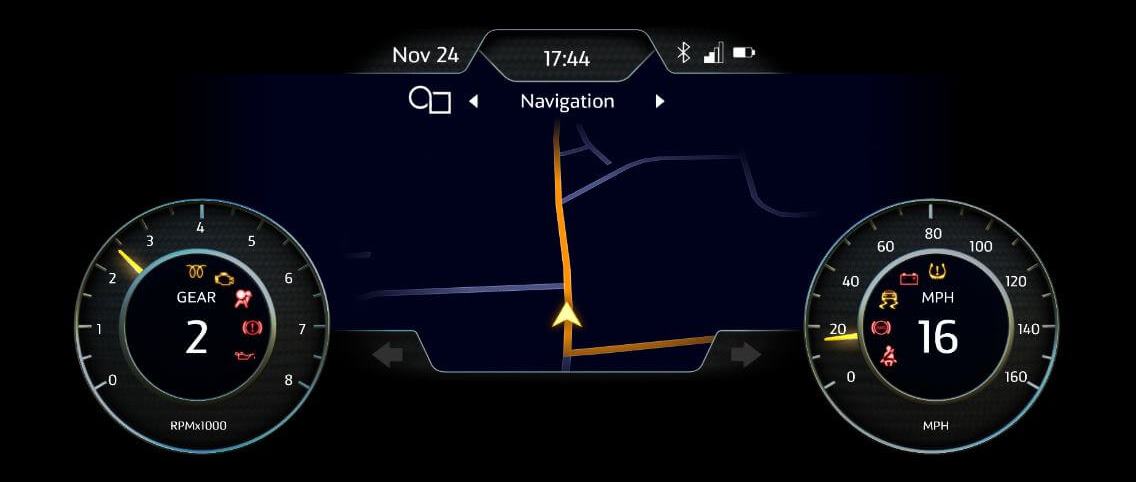
在这个演示中,我们使用解码后的文本来模拟汽车语音助手。在OpenGL®ES的帮助下,我们拥有一个类似于汽车数字集群的用户界面,通过麦克风输入音频源,我们可以说出诸如“增大音量”、“检查电池电量”或“显示导航”等命令,助手将识别这些命令,然后显示相应的结果。

在性能方面,网络的每次推理可以处理20毫秒的音频片段。如果我们使用实时音频流,我们必须在 1秒内处理50段音频。在这个速率下,因为我们的8TOPs NNA执行一次推理(可以并行处理一个或最多16个音频通道)需要1.22毫秒,所以仅占用了6.1%的性能。当占用NNA100%的性能时,它可以并行处理多达262个独立通道。如果以0.8TOPs的算力运行,推理时间是4.90毫秒,进行实时音频处理时占用了24.5%的性能,或者在100%的占用下工作时可以并行处理多达65个通道。
|
静态LSTM网络 |
8TOPS |
0.8TOPS |
|
每秒推断次数(100%占用) |
820 inf/s |
204 inf/s |
|
每步处理20毫秒的时间(1–16个通道) |
1.22毫秒(6.1%占用) |
4.90毫秒(24.5%占用) |
|
可并行运行的总音频通道数 |
262(100%占用) |
65(100%占用) |
随着技术的进步,人工智能系统变得越加复杂,加速这些操作的需求也在增加。Imagination的NNA性能使它成为运行这些网络的有效工具,它允许开发人员创建能够处理语音识别的交互式软件,这将在未来被广泛使用。
如果想了解NNA的更多信息,欢迎在评论区留言,告诉我们。

Jesus Garza,Imagination 案例演示视频开发团队 AI 应用工程师,专注于多种神经网络的研究,并通过创建案例演示视频以展示 Imagination 的神经网络加速器及相关的开发工具。
原文链接:https://www.imaginationtech.com/blog/running-lstm-neural-networks-on-an-imagination-nna/
声明:本文为原创文章,转载需注明作者、出处及原文链接





