作者:Gerry Raptis
利用乒乓机制的交错队列减少风险
在本篇文章中,我们将提到Vulkan 图形处理过程中夹杂计算任务时遇到的各式问题。为更准确地了解我们的话题,可查看文章第一部分。
第一部分概述了在Vulkan中如何使用barrier;具体来说,涉及图形→计算barrier,随后是一个中间帧计算→图形barrier。这会严重削弱GPU任务调度能力,并导致暂停,降低性能。为此我们给出了在多种资源配置情况下的不同解决方案。
体系架构级方法
"算法"优先的方法是手动使任务交错:也就是说,以我们希望的顺序提交任务,并使它们在GPU 上执行。这会生成正确结果,也为我们提供足够的可控性。在该情况下,首先为上一"逻辑"帧提交计算任务BN-1(注意缺少早期图形任务),然后提交当前帧AN的早期图形任务。随后,将提交计算/图形Barrier,接下来提交上一帧CN-1的后期图形任务,最后提交图形/计算Barrier。
这种方法会产生良好的结果,但会有损帧分离性,使维护更加困难。它对逻辑资源的需求将加倍,因为至少部分后期帧的操作代码需要比早期帧操作先调度。此外,会引入一个额外的滞后帧。
其执行过程如下:
帧N: BN-1→AN→ 计算/图形barrier → CN-1 → 图形/计算barrier→提交N-1
帧N+1: BN→ AN+1→ 计算/图形barrier → CN → 图形/计算barrier→提交N
这将允许BN-1/AN重叠。
听起来很复杂,而且也确实如此:计算多个帧操作通常需要大量的记录。但是,如果在此方案中任务封装的不错,至少一定程度上会缓解该问题。但是,如果复杂性更高时(即更复杂的猜测计算→barrier→图形→barrier→计算→barrier→图形工作负载),它仍然可能崩溃。在任何情况下,为降低不断增加的CPU 端复杂性成本,可以定制解决方案。
每个任务使用不同队列
另一个有效的解决方案是使用不同的队列,并在每个队列提交帧的不同部分:每个早期计算、后期计算、早期图形和后期图形提交到自己的队列,任务间连接使用信号量而非barrier。例如 ,PowerVR开发套件中的Vulkan粒子系统就是采用该方法,在对应的专用队列中提交所有计算。
但在我看来,该方案有其挑战性,它比交错帧更好,因为它允许 GPU 处理自己的问题,而不会弄乱引擎的非 API 部分。在我看来,它也是第一个"真正的"解决方案。类似于上述方案,它至少会缓解部分问题。在讨论其自身体系结构上的计算后处理时,Arm 在其社区网站上也将目光投向该方案。但是,它又取决于某些特定任务的重叠,一般来说,需要仔细生成大量的信号量,并且借助于队列优先级,这些增加了部分复杂性,但也为您提供了另一个控制向量。在多个交错计算/图形任务的情况下,它也可能不能完全按照我们预期的方式工作。该方案非常有效,可能将其与别的方案结合是个好思路。
我们已经找到了值得推荐的不同方案。
更简单、通用的方案:乒乓机制的交错队列
我们相信我们可以更简单、更有效的方式来完成计算。为此,我们需要从全局上考虑我们的最终目标:我们需要在没有Vulkan 规范介入的前提下,使 GPU 能够在连续两个帧中交替工作。
Vulkan 规范团队中的精明者可能已经意识到,barrier是始终指向单个队列的构造器。
PowerVR(和许多其它设备)设备可能会暴露多个相同/可互换的通用队列(图形+计算以及可能的呈现)。
因此,在这种情况下,为在不重新调整帧前提下避免跨帧同步,我们可以在不同队列中为每个帧提交负载。这将允许一个帧中的任何负载与下一帧中的任何负载交错执行,即使具有多个不同的图形、顶点和计算任务,因为它们在不同队列上显式执行,可以不受制于彼此的barrier。
简单来说:从同一队列源中创建两个相同的队列,然后对于每个帧,您提交负载到与上一队列不同的队列上。队列源很重要,因为它可以使您不必担心资源队列所有权等问题。
因此,帧提交过程如下:
帧 0:获取下一个图像→ 渲染 0(A0)→ 图形/计算barrier→ 计算0(B0)→计算/图形barrier→渲染0′(C0)→提交到队列0 →呈现到队列 0
帧 1:获取下一个图像→ 渲染 1A1→ 图形/计算barrier→ 计算1B1→计算/图形barrier→渲染1′C1→提交到队列1→呈现到队列1
帧 2:获取下一个图像→ 渲染2 A2→ 图形/计算barrier→ 计算2B2→计算/图形barrier→渲染2′C2→提交到队列0 →呈现到队列 0
帧 3:获取下一个图像→ 渲染 3A3→ 图形/计算barrier→ 计算3B3→计算/图形barrier→渲染3′C3→提交到队列1→呈现到队列1
...等等。
那么,这行得通吗?而且,如果可以,其原因是什么?
确实可行。BN(当前帧计算)和 CN(当前帧的后期图形)之间的barrier将阻止 CN在BN完成之前启动,但不会阻止 AN+1(下一帧的早期图形)启动,因为它在与Barrier不同的队列上提交(一个额外的好处,由于队列不同,AN+1与CN不需要强制排序)。
此技术解决了问题的核心:应用程序设置的barrier,旨在在单个帧中等待风险的发生,不会导致后续帧之间的任务间等待。我发现它相当令人欣喜,而且是迄今为止最简单的可实现方案——只要您的通用队列源中有多个队列,就可以使用单个计数器(甚至是布尔类型)并交换每一帧,此时无需进一步修改:只要我们确保 CPU 资源得到正确管理(与单个队列相同),不须施加额外同步。
简而言之,由于每个连续帧都在不同的队列中提交,因此 GPU 可以自由地在帧之间并行调度任务,预期结果为 (CN+1) 在(AN) 完成之后开始执行。它可确保渲染器及其相应的调度程序始终繁忙,并且中间的计算不会串行化帧。
—————–
计算工作负载:B0B1 B2B3 B4B5
图形工作负载:A0 A1 C0 C1 A2 A3 C2 C3 A4 A5 C4 C5 ...
或(基本相同的效果)如下:
计算工作负载:B0 B1 B2 B3 B4 B5
图形工作负载:A0 A1 C0 A2 C1 A3 C2 A4 C3 A5 C4 C5 ...
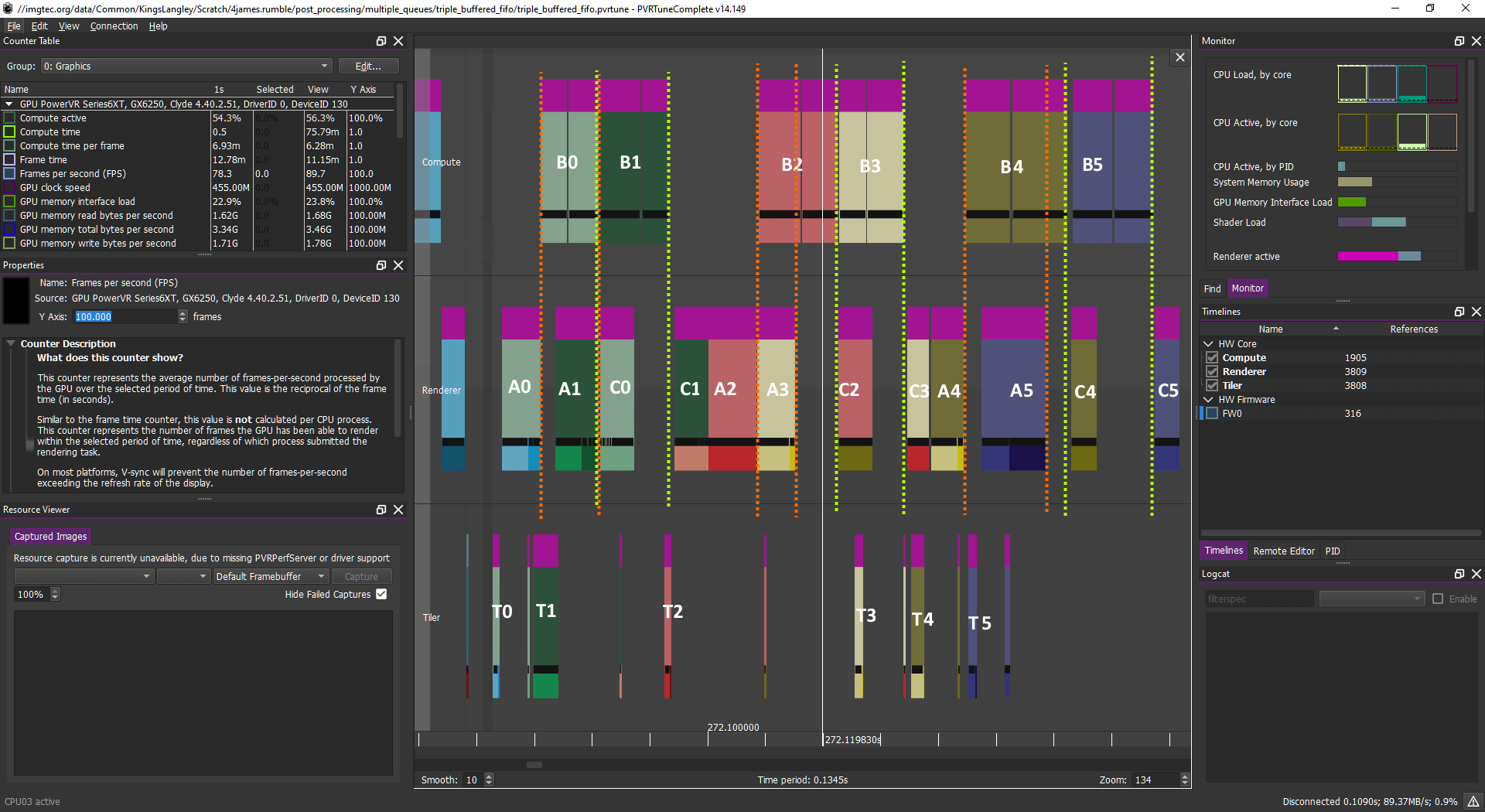
乍一看,这看起来可能很复杂,但实际很简单。无论如何,该图示告诉我们,GPU 正在处理一个帧(N)的计算,同时处理下一帧 (N+1) 的早期图形或上一帧的后期图形。
完全封装的情况是"相当不可能",它甚至没有必要达到这种水平的封装。但是,您应具备类似的特征,计算与顶点/片段任务一起调度,允许USC 加载使用尽可能多的容量。
其他的适用方案
通常,在任何存在barrier的情况下(而不仅仅是图形/计算/图形)时使用此技术是一个好思路。在任何情况下,它都不会有损性能,并且在--任何情况下调度器都具备更好的灵活性。调度器可能不需要额外的灵活性,但在任何情况下它都不会有损性能,而且增加的复杂性微不足道。
任何类型的barrier(包括图形/图形)都有可能损害 GPU 调度不同帧负载的能力并会导致暂停(顺便说一下,这是考虑使用barrier一个非常重要的原因,如果不考虑该因素,可以使用子类依赖性而非barrier)。计算示例非常重要,因为即使它们共享 PowerVR 上的执行内核、图形和计算部件,它们也在不同的数据主设备上工作,因此始终有些任务要并行执行,因此,如果可能,我们总是希望它们尽量重叠工作。但是,即使只是不同帧的图形负载交错执行,也通常允许您在顶点和片段任务之间获得更多的重叠,并确保 GPU 更好的饱和性。
因此,任何barrier情况都存在潜在风险,所以使用多个队列是备选。
注意事项:如何采用交错队列防止乱序
我们未能发现任何严重的不利条件。在不同帧之间使用不同的队列没有额外开销。我们确定的唯一限制很明显:同一队列源必须支持多个图形计算队列,不过,所有 PowerVR 设备都支持该特性。
我们能够识别的另一潜在问题是确保正确的呈现顺序。但是,交换链对象本身将确保这一点,因为图像以 FIFO 和邮箱呈现模式调用的 vkQueuePresent 顺序呈现。对于其它模式(例如即时),您可能需要确保当前操作正确同步,以便按顺序执行;这也相当容易实现。
最后,如果设备强制采用单个呈现队列,您可以修改如下,最终只在单个队列上呈现:
帧 0:获取下一个图像→ 渲染 0→ 记录图形/计算barrier→ 计算0 →计算/图形barrier→渲染0′→提交到队列0 →呈现到队列 0
帧 1:获取下一个图像→ 渲染 1→ 记录图形/计算barrier→ 计算1→计算/图形barrier→渲染1′→提交到队列1 →呈现到队列0
帧 2:获取下一个图像→ 渲染2→ 记录图形/计算barrier→ 计算2→计算/图形barrier→渲染2′→提交到队列0 →呈现到队列 0
帧 3:获取下一个图像→ 渲染 3→ 记录图形/计算barrier→ 计算3→计算/图形barrier→渲染3′→提交到队列1 →呈现到队列0
...等等。
它不仅利用了并行性,还确保了具有交换链"特殊"实现的驱动程序不会出现乱序帧呈现的风险。
简言之,我们完全可以放心的使用该技术。如果你发现了潜在的问题,请告诉我们。
重要性能说明
需要提醒的是,PowerVR 调度时与 CPU 线程调度工作方式不同,因为后者需要昂贵的上下文切换并保存到主存——如果调度器在同一 USC 上并行执行两个任务,在大多数情况下,它们之间切换成本为零,因此每当需要等待操作时(例如内存访问),调度器都可以切换到另一个任务并隐藏内存操作延迟。这是我们性能得以提升的重要部分。
下面是我们需要澄清的:该技术主要不是填充可能出现空闲的不同硬件部分负载,我们试图做的是指导驱动程序正确调度负载,减少开销并隐藏延迟。PowerVR 是一个统一的体系结构,顶点、图形和计算任务都在同一个 USC 上执行。与在不同顶点和片段着色器内核单独执行的早期图形设备不同,100%性能提升是无法实现的。我们不是要填充空闲内核;只是要 GPU非空闲时, 所有USC 都在运行(不排除一些意外状况发生)。
最后,在仅有图形的负载中,还可能会遇到这样的情况,barrier会阻止不同帧之间的重叠。
未来工作
当您希望将不同的任务提交到不同的队列类型/源情况下,此技术可以而且将起作用。一个重要的免责声明是,该技术不会取代帧的不同负载使用不同队列的潜在好处——如本文及其他文章中所讨论到的,使用不同的专用队列(特别是使用不同的队列优先级来最小化帧延迟)。
因此,在这些情况下,可以使用相同的逻辑——唯一的区别是,您不会将一个队列分裂为两个队列,而是将所有(或大多数)使用barrier的队列复用。这可能并非所有队列,因此不能替代常识和良好设计。在某些体系结构中,您可能使用三个不同的队列,并且只需要将其中一个或者多个中的两个队列复用并进行乒乓操作。最重要的是在barrier旁边至少增加一个队列。
例如,假设一个专用计算队列与多个通用队列并存,此技术可能仍然有用。事实上,在多数的有趣场景下,拥有多组具有不同优先级的不同队列并且帧之间交换集,这可以提供惊人的精细控制和灵活性。
这种情况可能工作如下:
(此处的队列 C2 是一个专用计算队列,队列 0 和队列 1 是我们要复用的通用队列):
帧 0:获取下一个图像→ 渲染 0 → 提交到队列 0 → 信号量给队列 2 → 计算 0,提交到队列 C2→ 信号量给队列 0 → 渲染0′→ 提交到队列 0→ 呈现给队列 0
帧1:获取下一个图像→ 渲染1→ 提交到队列 1→ 信号量给队列 2→ 计算 1,提交到队列 C2→ 信号量给队列 1→ 渲染1′→ 提交到队列 1→ 呈现给队列 1
帧2:获取下一个图像→ 渲染2→ 提交到队列 0 → 信号量给队列 2 → 计算 2,提交到队列 C2→ 信号量给队列 0 → 渲染2′→ 提交到队列 0→ 呈现给队列 0
帧 3:获取下一个图像→ 渲染3→ 提交到队列1→ 信号量给队列 2 → 计算 3,提交到队列 C2→ 信号量给队列 1→ 渲染3′→ 提交到队列 1→ 呈现给队列 1
帧 4:获取下一个图像→ 渲染4→ 提交到队列 0 → 信号量给队列 2 → 计算 4,提交到队列 C2→ 信号量给队列 0 → 渲染4′→ 提交到队列 0→ 呈现给队列 0
同样,此处的多个图形队列是必要的,以允许在当前帧的第二次渲染之前调度连续帧的第一次渲染。
结论
我们向您展现了一个非常完整和通用的解决方案,用以解决常见但现实的难题。无论何时,尽可能为每帧使用多个队列,您可以无风险、更简单地获得惊人的性能提升。希望这将对您的项目有帮助!如果该技术确实帮助到您,欢迎向我们分享您的故事。
我们在 PowerVR SDK中的许多演示中都使用此技术,而且我们在编写后处理演示时也受到了启发,并使用了该技术。
英文链接:https://www.imgtec.com/blog/vulkan-synchronisation-and-graphics-compute-...
声明:本文为原创文章,转载需注明作者、出处及原文链接,否则,本网站将保留追究其法律责任的权利。





