作者:Gerry Raptis
在现代渲染环境中,很多情况下在一个数据帧期间会产生计算负荷。在GPU上计算通常(非固定功能)是并行编程的,通常用于具有挑战性,完全不可能或仅通过标准图形管道(顶点/几何/细化/栅格/碎片)实现的效率低下的技术。一般情况下,计算在实现技术方面提供了几乎绝对的灵活性。但是这种普遍性带来了其他挑战:在同步渲染任务方面,GPU可以做出的假设要少得多,尤其是在我们尝试优化GPU并使负载饱和的情况下。
无需过多的讨论,保持GPU的占用率至关重要。实际上,这是最重要的性能因素。如果GPU没有做任何事情,或者没有被充分利用,而我们的帧速率目标尚未实现,那么尝试对应用程序进行微优化实际上是毫无意义的。
另一方面,当达到我们的最大帧速率指标时,这种情况会逆转:如果我们已经在分配的最小帧时间内渲染了我们需要渲染的所有内容——换句话说是显示了我们需要的尽可能多的数据帧——我们应该允许GPU处于空闲状态,从而减少功耗并释放更少的热量。但是这不是没有正确同步的借口,如果同步不正确将不会很好的吸收小的负载峰值并可能导致不必要的FPS波动。
要在Vulkan中进行同步,从概念上讲我们需要清楚不同操作之间的依赖关系。Vulkan在这方面非常灵活且功能强大。但是这种灵活性可以说是一把双刃剑,随着同步变得复杂和冗长,该任务可能会变得艰巨并且要推理出最佳路径也不是一个简单的任务。用于同步的工具有barriers、Events、Semaphore (信号量)和Fences(栅栏),每个都在不同情况下强制执行操作顺序。最常见且最轻量级的是barrier,它仅在GPU本身之前和之后强制执行指定类型的命令。
本质上,barrier通常是用来搞清楚源程序和目标程序的依赖关系。具体可描述为:“对于到目前为止已记录的所有图形命令,确保至少已执行其片段步骤,在开始执行顶点步骤之前记录此点后续的图形命令数。
例如,一个通道的彩色附件(color attachment)被用于另一个通道的输入附件(input attachment)(不考虑subpass dependencies的特殊情况)。
然后将包含此barrier的渲染命令缓冲区提交到队列中,它将对该队列中的所有命令生效(对后文的提示)。如果我们需要在不同的队列中使用这种效果,正确的原语是一个semaphore(信号量)。如果需要同步以等待CPU的事件,则可以使用fence或event(事件)。如果我们想在CPU/GPU之间进行任意的同步则可以使用event(事件)。
在我们特定的案例中,barrier的作用如下:
“对于到目前为止已记录的所有计算命令确保他们执行完成,在开始顶点步骤之前记录后续的图形命令数量。”我们将其称为计算——图形barrier。
首要的事情:工具选择
在PowerVR平台上进行任何性能调整时,你最好的朋友是PVRTune。PVRTune是我们的GPU分析应用程序,可提供绝对全面的信息。这包括在GPU上实时执行的所有任务,大量硬件计数器,负载等级,处理速率等。我们不能对此施加太大压力——PVRTune应该始终是在设备上对应用程序进行性能分析的第一站和最后一站。它支持所有PowerVR平台,因此请确保下载PVRTune和所有其他免费的PowerVR工具。
下载地址:https://www.imgtec.com/developers/powervr-sdk-tools/
关于图表的注释
对于本文中下面的所有示例,为了简单起见我们将忽略tiler任务(在图表中标记为TN)。
Tiler在这里指的是与顶点(Vertex)任务相同的处理阶段,这两个术语可以互换使用。
渲染器(Renderer)指的是相同的处理阶段碎片/像素任务,这些术语可以互换使用。
总的来说,我们在本文中所指的内容可以扩展到“顶点任务”,但是顶点任务通常更容易处理,因为它们倾向于自然的重叠中间帧计算任务,这是此处讨论的最困难的情况,通常与片段阶段有依赖性。
但是如果你具有计算(compute)->vertex(甚至是vertex->compute)的barrier,则顶点任务可能会发生具有完全相同解决方案的类似情况。
关于多缓冲(multi-buffering)的说明
在台式机上双倍缓冲(double-buffering,在交换链中使用两个帧缓冲图像)似乎是目前的标准。
但是双缓冲(double-buffering)实际上不允许你在移动设备上重叠来自不同帧的操作。PowerVR是基于分块延迟渲染(TBDR)的体系结构,可以充分利用并行处理多个帧的功能。根据Vulkan规范,如果不够详细,通常就无法渲染在当前屏幕上呈现的帧缓冲区图像。这意味着在任何的时间点GPU都只能主动渲染“空闲状态”的图像(后台缓冲区)。
因此强烈建议使用三个帧缓冲图像创建交换链,特别是在启用垂直同步(Vsync)的情况下(或在Android平台上强制启用)。这种技术通常被称为三重缓冲,并且可以提供比双缓冲更高的性能。
与双缓冲相比三重缓冲的缺点是它引入了额外的帧延迟,在某些延迟敏感的情况下(如台式机上高FPS的竞争类游戏)这可能是不允许的,但在移动设备上很少出现此问题。
但是本文不是关于多缓冲的文章,因此我们将不做进一步的详细说明,仅说明本文假设你正在使用三个帧缓冲图像来利用这种并行性即可。如果你使用的是PowerVR SDK和其他可能的解决方案则默认为是三重缓冲模式。
琐碎情况
对于计算和图形负载而言,一个琐碎(但不常见)的案例在并行处理方面可能是令人尴尬的:彼此完全独立并且可以完全并行执行。如果我们在每一帧中都有一些无关的任务,例如为两个彼此不交互的屏幕渲染两个不同的工作负载就会发生这种情况。在这些之间通常不需要发生任何barrier(或其他同步原语),因此GPU可以并行的调度它们。
在API方面调用如下所示:
计算调度->绘制->展示
在PVRTune中计算和图形任务可能如下所示:
(数字表示不同框架中的任务)
————————
计算负载:B0 B1 B2 B3....
图形负载:A0 A1 A2 A3....
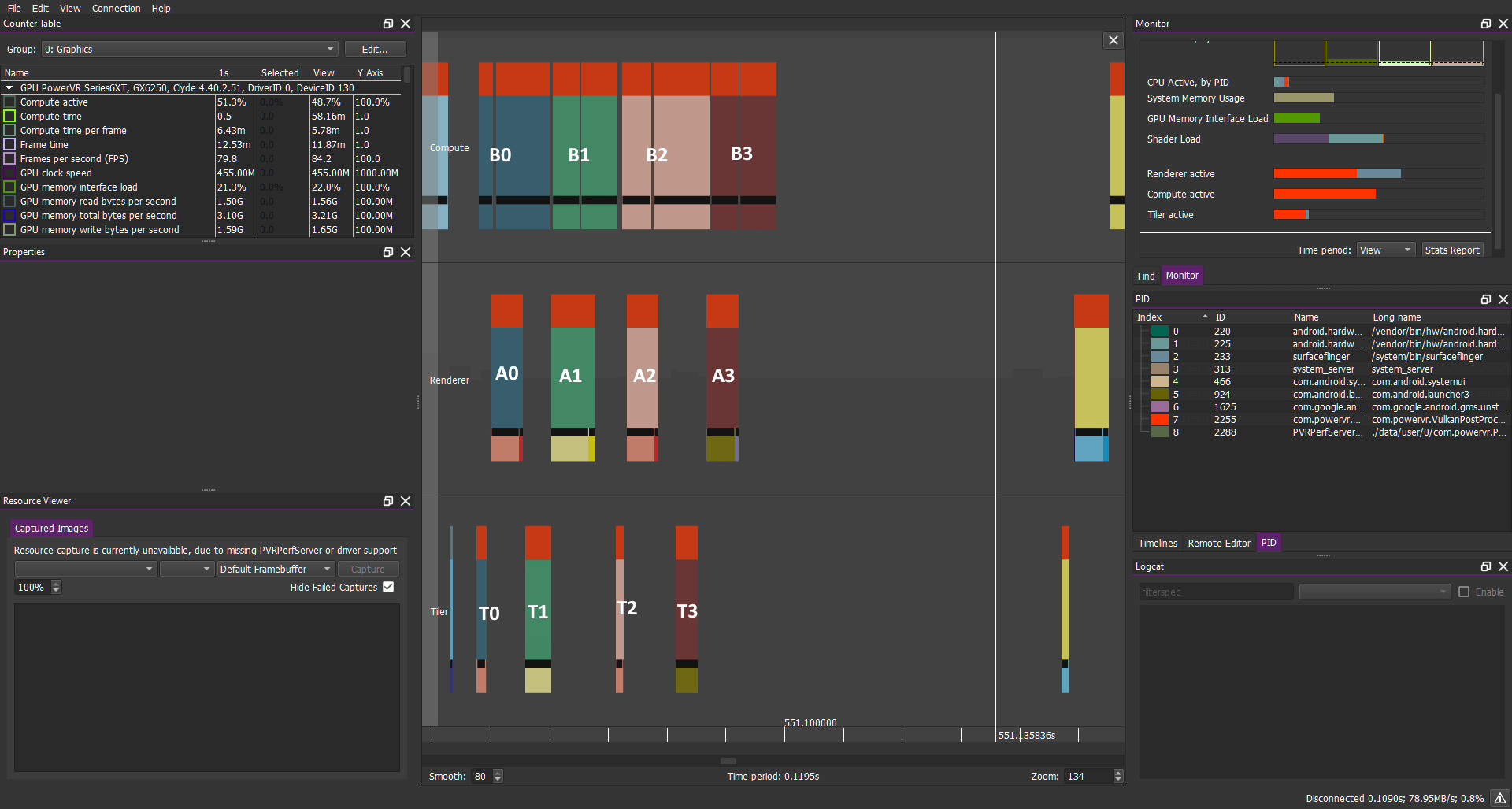
这可以带来巨大的好处:通过更多的任务来安排进出时间,GPU可以隐藏延迟并提供良好的性能优势,而不是一个接一个的执行这些任务。但是这种“令人尴尬的并行操作”的情况在这里并不会特别令人感兴趣,也不是那么的普遍。但是它强调了一个有用但并不总是显而易见的原则:仅同步所需的内容。
简单情况
这种情况不常见,我们对此并不感兴趣。更常见的是需要图形工作负载之前发生的计算工作负载。这可能是某种顶点处理,计算剔除,几何图形生成或图像帧中要求的其他操作。通常顶点着色器需要这些数据,在这种情况下我们将需要在vkCmdDispatchCompute和vkCmdDrawXXX之间插入vkCmdPipelineBarrier,以实现这种事前发生的关系。
调用流程看起来如下所示:
计算调度-->Barrier(源:计算,目标:图形/顶点)->绘制->展示
或者可能正好相反,例如执行一些计算后处理任务。但是这意味着直接通过计算(compute)写入缓冲区,这通常不是理想的情况:片段流水线为写入帧缓冲区进行了优化,具有帧缓冲区压缩等诸多优点。
绘制->Barrier(源:图形/片段,目标:计算)->计算调度->展示
可能会错误的期望会发生这样的事情,实际上如果我们只对缓冲区进行双缓冲或进行某种形式的过度同步操作,我们可能最终会失败。
如果我们使用双缓冲而不是三重缓冲则需要等待Vsync才能继续渲染,因此可能会丢失很多并行操作
————————
计算负载:B0 B1 B2 B3 B4...
图形负载:A0 A1 A2 A3 A4...
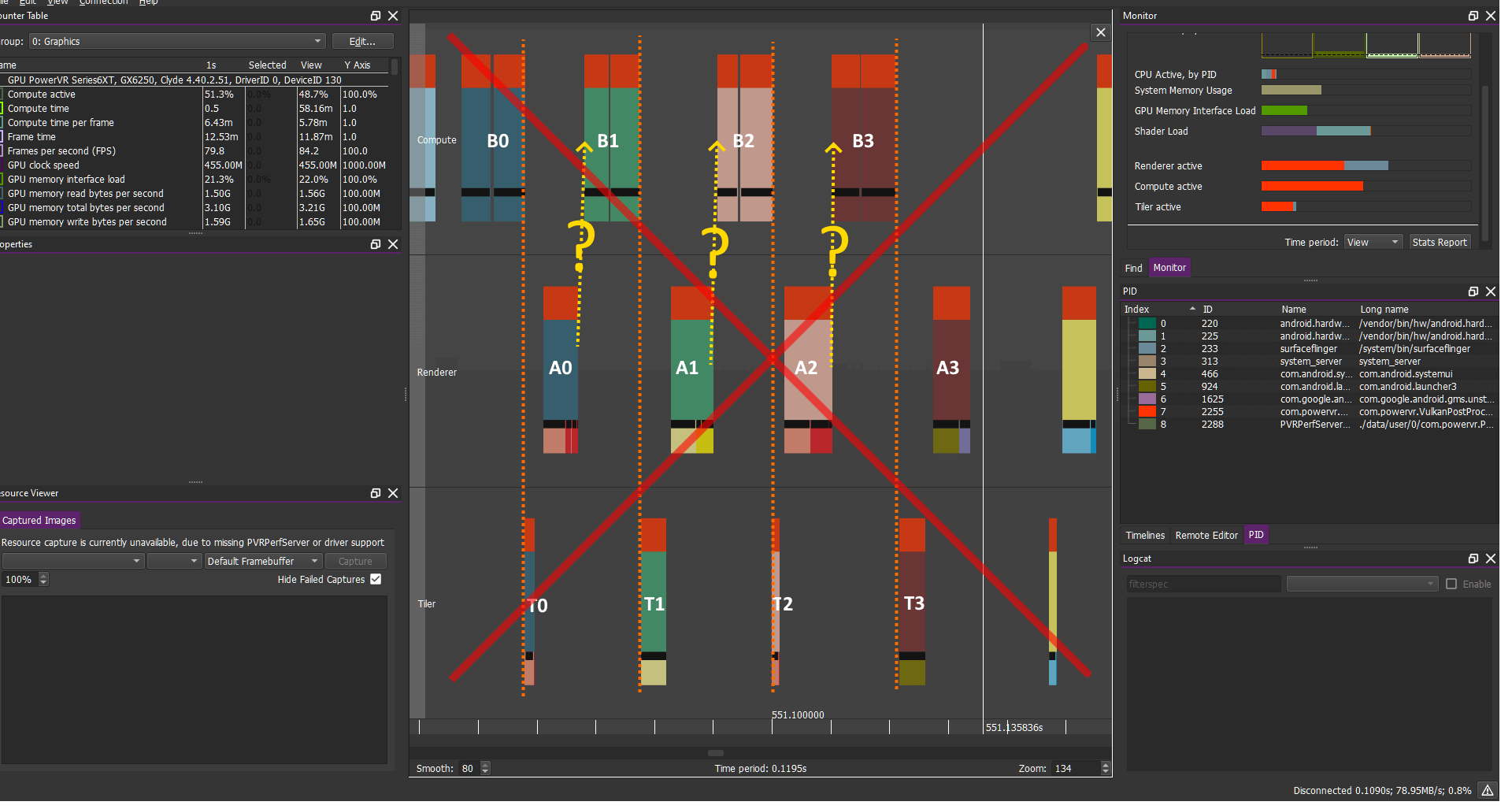
注:此图只是理论上的,假设满足以下条件:
- 我们正在使用三重缓冲
- 未启用Vsync或我们尚未达到硬件平台的最大FPS
如果我们正确同步并以最大Vsync fps(通常为60fps)进行同步,则这种情况变得完全有效:如果没有足够的负载要执行,GPU将更加省力甚至处于空闲状态,从而节省功耗,并且任务会像这样自然的序列化执行。在这些情况下这是有效且可取的。此处的转折点是对于低于最大FPS运行的应用程序不应该发生这种情况。
在这种情况下我们期望的重叠要好得多,如果我们使用三重缓冲并且不过度同步通常会发生什么。GPU应该能够通过下一帧(N+1)的计算操作来调度这一帧(N),因为通常不会存在Barrier来阻止这种情况的发生。如前文所述我们需要这种并行性来实现最佳性能。
————————
计算负载:B0 B1 B2 B3...
图形负载:A0 A1 A2 A3....
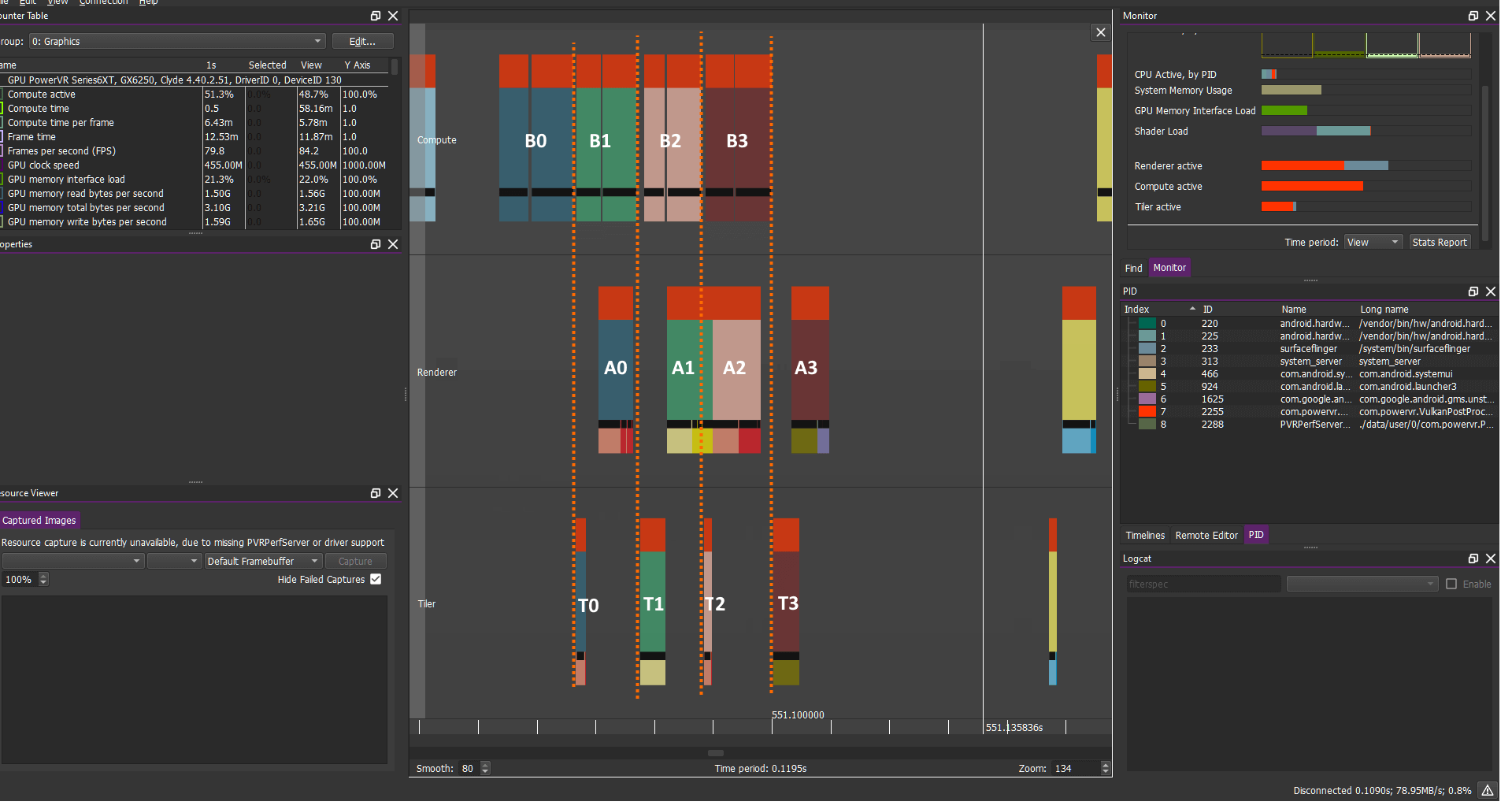
在绘制对象之前我们需要准备好它们,不过在很多情况下我们不需要前一帧的渲染即可渲染后一帧,因此在这种情况下GPU可以自由的允许BN+1/AN 重叠并很好的进行封装以提高性能。
更加复杂难缠的情况
像往常一样事情并非如此简单,当你转向高级多通道流水线时,我们的渲染操作往往比这复杂得多。即使正确的对操作进行了排序也很可能会在图形操作之间插入一个计算调度的操作而使整个任务中断,例如在使用片段着色器对屏幕画面进行进一步的后处理和UI合成之前,我们可能会在帧的中间插入计算操作来计算一些优化的Blur值。
鸟瞰图绘制过程的简单版本如下所示:
绘制->Barrier(源:图形/片段,目标:计算)->计算调度->Barrier(源:计算,目标:图形/顶点)->绘制->展示
这些情况可能会很成问题,原因很快就会显现出来。
在这种情况下单个帧的任务操作如下所示:
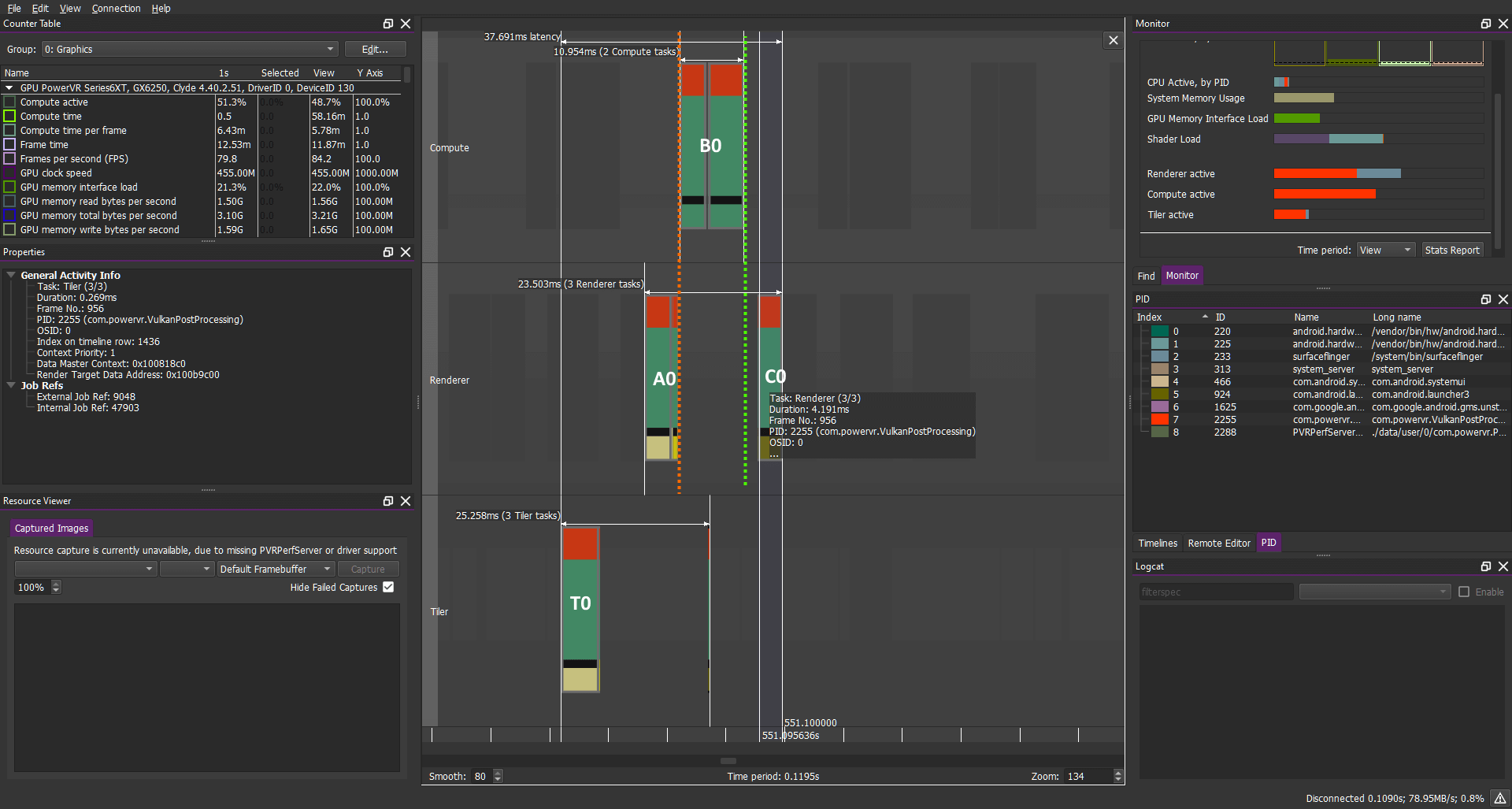
在前面的示例中你应该希望此时A1应该在A0和C0之间并与B0重叠
不幸的是如果“正确的”与上述Barrier进行基本同步,那将不是你所能获取的,你得到的信息如下:
计算负载:B1 B2 B3 B4 B5
图形负载:A1 C1 A2 C2 A3 C3 A4 C4 A5 C5...
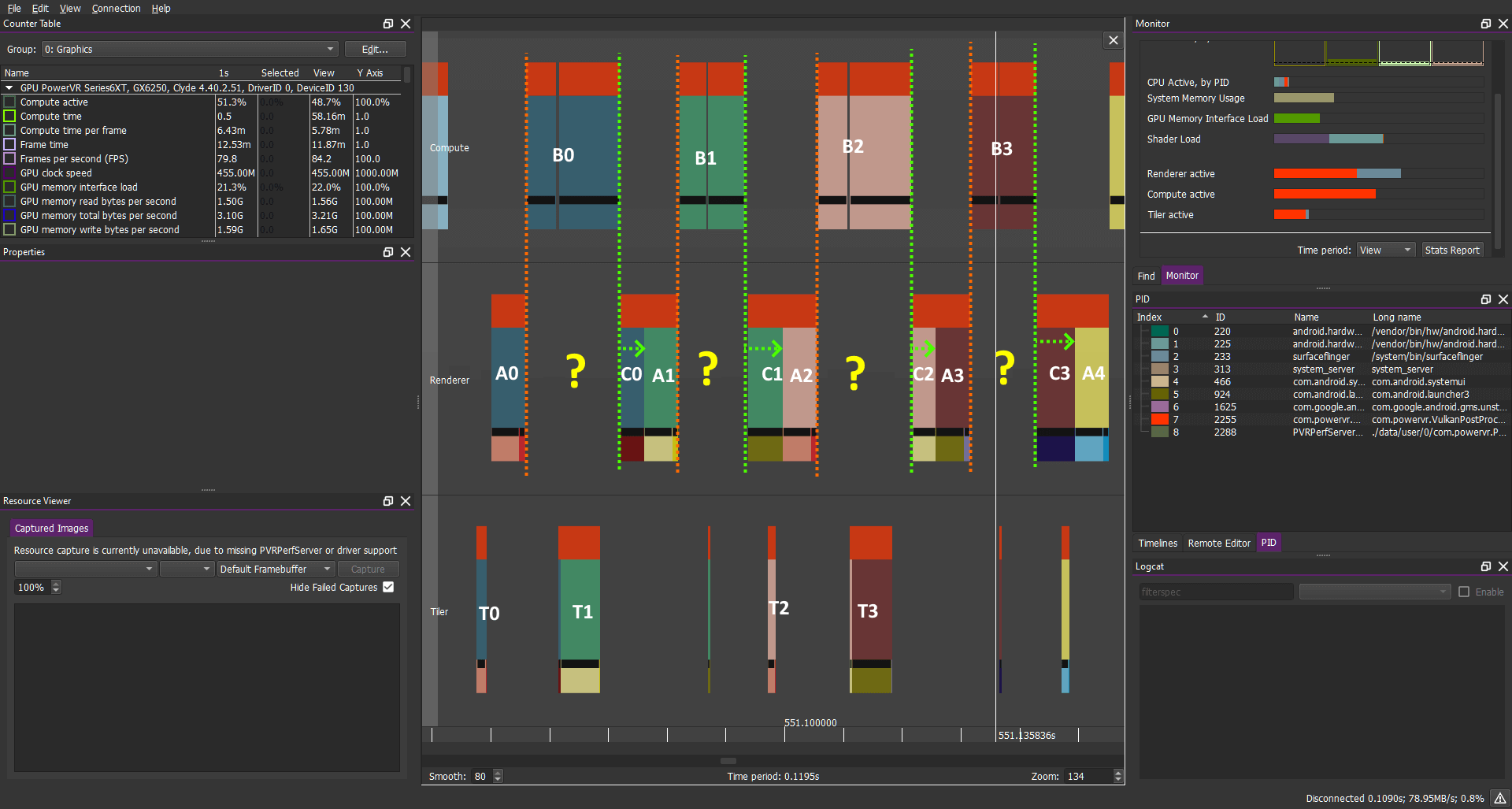
因此我们看到一帧最开始的片段任务实际上在整个前一帧之后被完全替换。
但这是为什么呢?
看看上面的工作负载以及Barrier,答案变得相当明显:
A和B之间的(橙色标识部分)Barrier可以用英文解读为:“无计算任务,在安排好AN 之后进行调度,然后在AN 完成执行之前开始执行”,嗯...这看起来很合理。
B和C之间的(绿色部分)Barrier显示为:“无图形任务,在安排好BN之后进行调度,在BN完成执行之前允许开始执行”,这个Barrier也很有意义,因为我们需要CN在BN完成后才能启动。
但是我们还希望尽快调度AN+1(也就是图形任务),最好在CN启动后立即开始。但是BN/CN之间的Barrier不允许这样做导致一些级联:AN+1在BN之后被置换但是由于CN已经被调度,它甚至进一步置换了AN+1(不同的像素任务不能彼此重叠)从而导致所有任务的完整序列化。
简而言之计算/图形Barrier不允许下一帧的早期图形任务与计算任务同时执行(绿色箭头)
这是坏消息,在这种情况下USC(统一阴影集群,所有数学和计算都在其中发生,是PowerVR GPU的核心)极有可能未被充分利用,并且在这些任务之间的通信至少必须有一定的开销。可计划的任务负载越少,好的利用机会就越少。此外计算和图形任务的组成通常不同,其中一项是受内存和纹理限制,另一项是ALU/数学限制,并且非常适合同时调度。此外如果所有任务都是串行的,则通常也可能在它们之间引入微小的间隔(管道间隙),最后v-sync将进一步加剧该问题,所有这些因素加起来会导致巨大的性能差异,我们已经看到了这一方面的很多差异,虽然你遇到的可能会有所不同,但20%左右的概率并不常见。通过更好的重叠设计潜在的提升可达5%,而在实际应用中我们的性能提升高达30%。
综上所述:我们希望能够将下一帧(AN+1)开始的图形操作放在第N帧(CN)的后面进行调度以便它们与当前帧(BN)的计算能够并行执行以实现更好的GPU利用率。
这是你在Vulkan中处理同步问题时可能遇到的想法,潜在的解决方案我们将在后续的文章中进行检验。
相关主题的后续文章将很快发布,敬请关注!
英文链接:https://www.imgtec.com/blog/vulkan-synchronisation-and-graphics-compute-...
声明:本文为原创文章,转载需注明作者、出处及原文链接,否则,本网站将保留追究其法律责任的权利。





