2023年是大语言模型和稳定扩散的一年,时间序列领域虽然没有那么大的成就,但是却有缓慢而稳定的进展。Neurips、ICML和AAAI等会议都有transformer 结构(BasisFormer、Crossformer、Inverted transformer和Patch transformer)的改进,还出现了将数值时间序列数据与文本和图像合成的新体系结构(CrossVIVIT), 也出现了直接应用于时间序列的可能性的LLM,以及新形式的时间序列正则化/规范化技术(san)。
我们这篇文章就来总结下2023年深度学习在时间序列预测中的发展和2024年未来方向分析
Neurips 2023
在今年的NIPs上,有一些关于transformer 、归一化、平稳性和多模态学习的有趣的新论文。但是在时间序列领域没有任何重大突破,只有一些实际的,渐进的性能改进和有趣的概念证明。
1、Adaptive Normalization for Non-stationary Time Series
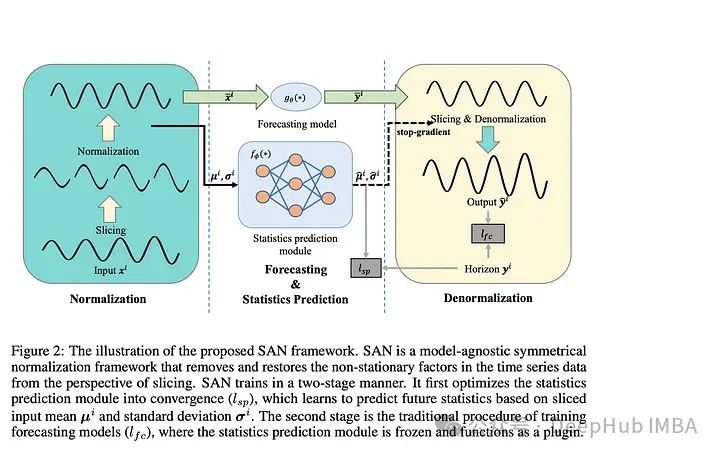
论文介绍了一种“模型不可知的归一化框架”来简化非平稳时间序列数据的预测。作者让SAN分两步操作:训练一个统计预测模型(通常是ARIMA),然后训练实际的深度时间序列基础模型(使用统计模型对TS数据进行切片、归一化和反归一化)。统计模型对输入时间序列进行切片,以便学习更健壮的时间序列表示并去除非平稳属性。作者指出:“通过对切片级特性进行建模,SAN能够消除局部区域的非平稳性。”SAN还显式地预测目标窗口的统计信息(标准差/平均值)。这使得它在处理非平稳数据时,与普通模型相比,能够更好地适应随时间的变化。
采用transformer 模型作为基本预测模型,对典型的时间序列预测基准(如电力、交换、交通等)进行指标验证。作者发现SAN在这些基准数据集上持续提高了基本模型的性能(尽管他们没有测试Inverted Transformer,因为这篇论文是在Inverted Transformer之前发布的)。
由于该模型结合了一个统计模型(通常是ARIMA)和一个普通的transformer ,我认为调优和调试(特别是在新的数据集上)可能会很棘手和麻烦。因为几乎所有的时间序列模型都将序列输入长度作为超参数。另外就是“切片”的切片与普通的序列窗口有何不同?作者还是没有说清楚。总的来说,我认为这仍然是一个相当强大的贡献,因为它的实验结果和即插即用属性。
2、BasisFormer
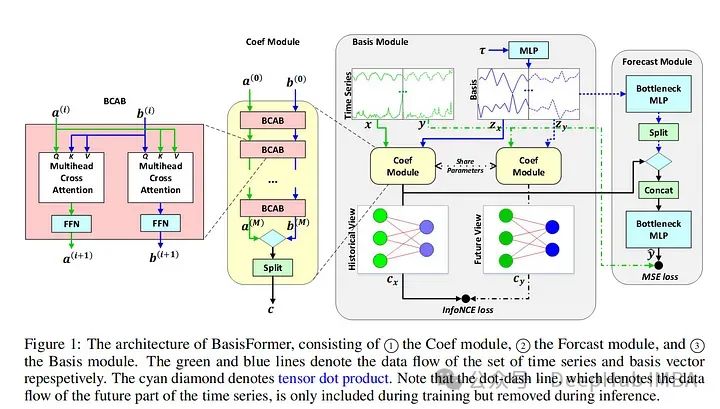
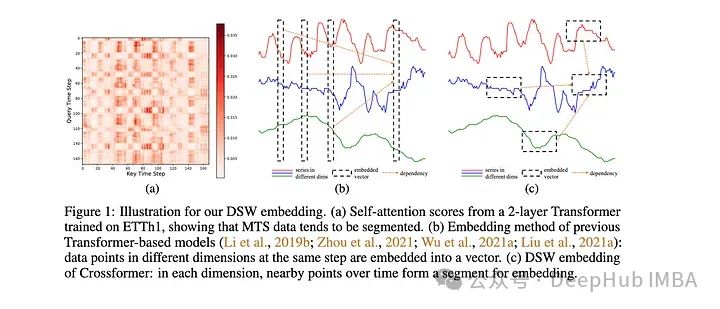
该模型是专门为多元时间序列预测(MTS)开发的。该模型采用维度分段嵌入(DSW)机制。DSW嵌入与传统嵌入的不同之处在于它采用二维格式的数据。并且跨变量和时间维度显式地从MTS数据生成段。
该模型在标准MTS数据集(ETH, exchange等)上进行了评估:在发布时时优于大多数其他模型,例如Informer和DLinear。作者还对dSW进行了消融研究。
这篇来自ICLR的关于的论文在预测河流流量时表现不错,但是是在一次预测多个目标时,性能似乎会下降很多。也就是说,它的表现肯定比Informer和相关的Transformers 模型要好。
2、Learning Perturbations to Explain Time Series Predictions
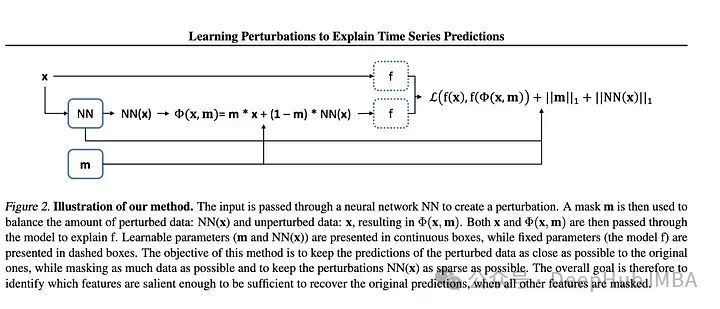
大多数用于深度学习解释的扰动技术都是面向静态数据(图像和文本)的。但是对于时间序列特别是多元TS需要更大范围的扰动来学习随机影响。作者提出了一种基于深度学习的方法,可以学习数据的掩码和相关的扰动,更好地解释特征的重要性。然后将掩码和扰动的输入传递给模型,并将输出与未扰动数据的输出进行比较。据两个输出之间的差值计算损失。
越来越多的研究人员正在深入研究解释深度学习模型这是件好事。本文概述了现有的方法及其不足,并提出了一种改进的方法。我认为使用额外的神经网络来学习扰动的想法增加了不必要的复杂性,因为每当我们增加更多的层和额外的网络时,就会增加发生问题的概率,特别是在已经很大的网络上。别忘了奥卡姆剃刀定律如无必要,勿增实体
3、Learning Deep Time Index Models
本文通过光流和元学习来讨论预测,描述了学习如何预测非平稳时间序列。对于那些不熟悉的人来说,元学习通常被应用在计算机视觉数据集上,像MAML这样的论文可以对新的图像类进行少量的学习。MAML和其他模型都有一个内部循环和一个外部循环,其中外部循环教模型如何学习,内部循环对其进行微调以适应特定的任务。论文的作者采用了这一思想,并将其应用于几乎将每个非平稳性视为一个新的学习任务。新的“任务”是长时间序列序列的块。
作者在ETH,temperature和exchange 数据集上测试了他们的模型。尽管他们的模型没有达到SOTA的结果,但它与当前的SOTA体系结构具有竞争力。
这篇论文为时间序列预测提供了一个有趣的角度,相对于常规方法有了一个新的突破,我想就是他虽然没有超过SOTA但是还是被录用的原因之一吧。
4、Inverted Transformers are Effective for Time Series Forecasting

《Inverted Transformers》是2024年发表的一篇论文。这也是目前时间序列预测数据集上的SOTA。基本上,Inverted Transformers采用时间序列的Transformers架构并进行了翻转。整个时间序列序列用于创建令牌。然后,时间序列彼此独立进行嵌入表示。注意力对多个时间序列嵌入进行操作。它有点类似于Crossformer,但它的不同之处在于,它遵循标准Transformers架构。
作者在标准时间序列数据集上评估模型目前优于所有其他模型,包括Informer, Reformer, Crossformer等。
这是一篇强大的论文,因为模型的表现优于现有的模型。但是在某些情况下,它优于模型的数值并不是那么显著。所以可以优先看看这篇论文并且进行测试。
TimeGPT
最后说说TimeGPT,它没有在任何主要会议上被接受,而且它的评估方法也优点可疑,由于它不幸地在互联网上获得了相当多的介绍,所以我们要再提一下:
1、作者没有将他们的结果与其他SOTA类型模型进行比较,只是引用“测试集包括来自多个领域的30多万个时间序列,包括金融、网络流量、物联网、天气、需求和电力。”并且没有提供测试集的链接,也没有在他们的论文中说明这些数据集是什么。
2、论文中架构图和模型体系结构的描述非常糟糕。这看起来就像是作者复制了其他论文的图表,强加上注意力的定义和LLM相关的流行词汇。
3、作者的Nixtla公司非常小,可能是一家小型初创公司,它是否有足够的计算资源来完全训练一个“成功的时间序列基础模型”。虽然这样说法优点歧视,但是如果我说我一个人用一周训练了一个LLM,那估计都没人相信,对吧。
OpenAI、谷歌、亚马逊、Meta等公司提供足够的计算资源来创建庞大的模型。如果TimeGPT真的是一个简单的Transformers 模型,并在大量的时间序列数据上训练它,为什么其他机构,甚至个人不能用它的大量gpu做到这一点呢?答案是,事情肯定没那么简单。
时间序列创建“基础模型”的能力目前还不够完善。多元时间序列预测的一个重要组成部分是学习协变量之间的依赖关系。MTS的维度在不同的数据集之间差异很大。对于具有文本数据的Transformers ,我们总是将一个单词映射到一个数字id,然后创建一个特定维度的嵌入。
对于MTS,不仅值可以更改,而且在一个数据集上可能有100个变量,而在另一个数据集上只有10个变量。这使得几乎不可能设计所有用途的映射层来将不同大小的MTS数据集映射到公共嵌入维度。所以还记得我们前几天发的Lag-Llama,也只是单变量的预测。
在其他时间序列(即使是那些具有相同数量变量的时间序列)上预训模型不会产生改进的结果(至少在当前架构下不会)。
总结及未来方向分析
在2023年,我们看到了Transformers 在时间序列预测中的一些持续改进,以及llm和多模态学习的新方法。随着2024年的进展,我们将继续看到在时间序列中使用Transformers 架构的进步和改进。可能会看到在多模态时间序列预测和分类领域的进一步发展。
作者:Isaac Godfried
本文转自:DeepHub IMBA,转载此文目的在于传递更多信息,版权归原作者所有。如不支持转载,请联系小编demi@eetrend.com删除。





