模型训练

模型训练是通过不断训练、验证和调优,让模型达到最优的一个过程。
决策边界是判断一个算法是线性还是非线性最重要的标准。
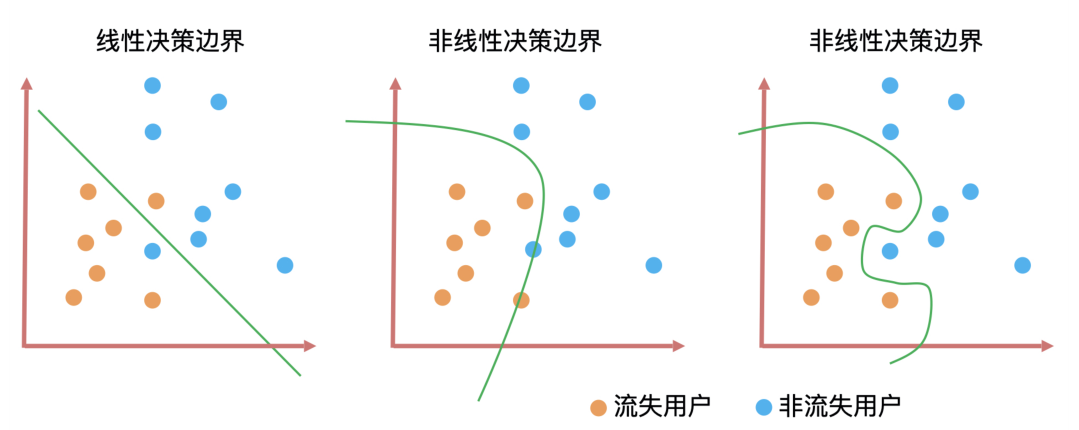
上图就是三种算法的决策边界。决策边界的形式无非就是直线和曲线两种,并且这些曲线的复杂度(曲线的平滑程度)和算法训练出来的模型能力息息相关。一般来说决策边界曲线越陡峭,模型在训练集上的准确率越高,但陡峭的决策边界可能会让模型对未知数据的预测结果不稳定。
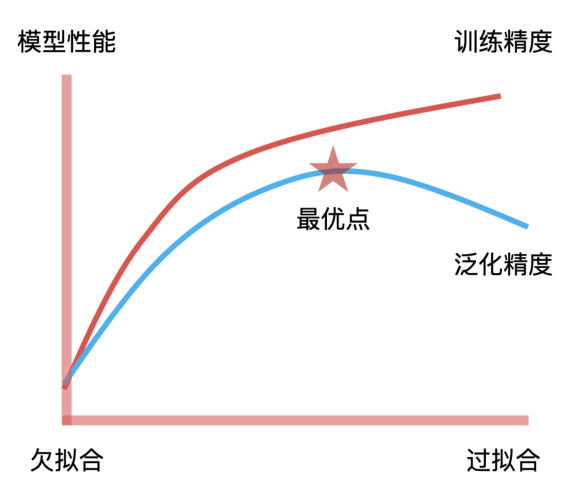
模型训练的目标就是找到拟合能力与泛化能力的平衡点。拟合能力代表模型在已知数据上表现得好坏,泛化能力代表模型在未知数据上表现得好坏。它们之间的平衡点,就是我们通过不断地训练和验证找到的模型参数的最优解,因此,这个最优解绘制出来的决策边界就具有最好的拟合和泛化能力。这是模型训练中“最优”的意思,也是模型训练的核心目标。
一般情况下,算法工程师会通过交叉验证(Cross Validation)的方式,找到模型参数的最优解。
模型验证
模型验证主要是对待验证数据上的表现效果进行验证,一般是通过模型的性能指标和稳定性指标来评估。
模型性能
可以理解为模型预测的效果,你可以简单理解为“预测结果准不准”,它的评估方式可以分为两大类:分类模型评估和回归模型评估 。
分类模型评估
分类模型解决的是将一个人或者物体进行分类,例如在风控场景下,区分用户是不是“好人”,或者在图像识别场景下,识别某张图片是不是包含人脸。对于分类模型的性能评估,我们会用到包括召回率、F1、KS、AUC 这些评估指标。
回归模型评估
回归模型解决的是预测连续值的问题,如预测房产或者股票的价格,所以我们会用到方差和 MSE 这些指标对回归模型评估。
对于产品经理来说,我们除了要知道可以对模型性能进行评估的指标都有什么,还要知道这些指标值到底在什么范围是合理的。虽然,不同业务的合理值范围不一样,我们要根据自己的业务场景来确定指标预期,但我们至少要知道什么情况是不合理的。
模型稳定性
我们可以使用 PSI 指标来判断模型的稳定性,如果一个模型的 PSI > 0.2,那它的稳定性就太差了,这就说明算法同学的工作交付不达标。
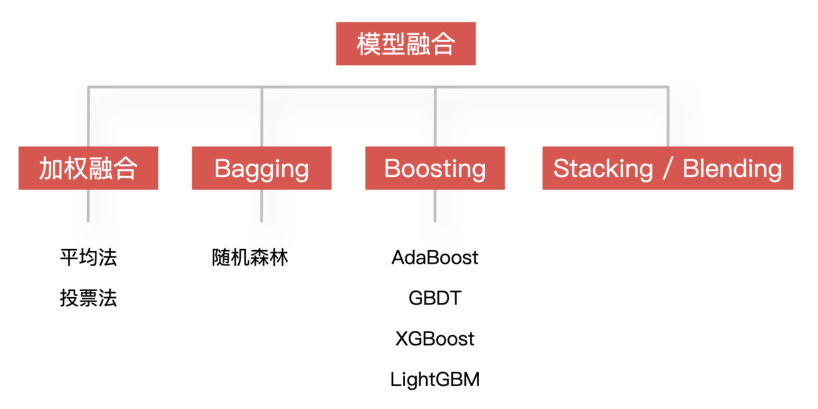
模型融合
同时训练多个模型,再通过模型集成的方式把这些模型合并在一起,从而提升模型的准确率。简单来说,就是用多个模型的组合来改善整体的表现。
模型部署
一般情况下,因为算法团队和工程团队是分开的两个组织架构,所以算法模型基本也是部署成独立的服务,然后暴露一个 HTTP API 给工程团队进行调用,这样可以解耦相互之间的工作依赖,简单的机器学习模型一般通过 Flask 来实现模型的部署,深度学习模型一般会选 TensorFlow Serving 来实现模型部署。
本文转自: 小牛机器人 - RobotBull,转载此文目的在于传递更多信息,版权归原作者所有。如不支持转载,请联系小编demi@eetrend.com删除。





