可视化是一种强大的工具,用于以直观和可理解的方式传达复杂的数据模式和关系。它们在数据分析中发挥着至关重要的作用,提供了通常难以从原始数据或传统数字表示中辨别出来的见解。
可视化对于理解复杂的数据模式和关系至关重要,我们将介绍11个最重要和必须知道的图表,这些图表有助于揭示数据中的信息,使复杂数据更加可理解和有意义。
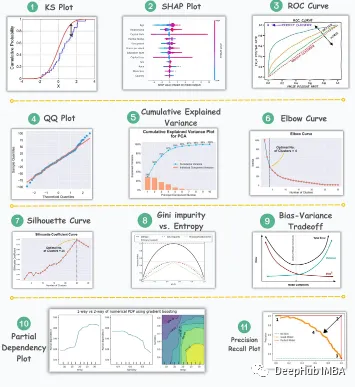
1、KS Plot
KS Plot用来评估分布差异。其核心思想是测量两个分布的累积分布函数(CDF)之间的最大距离。最大距离越小,它们越有可能属于同一分布。所以它主要被解释为确定分布差异的“统计检验”,而不是“图”。
2、SHAP Plot

SHAP Plot通过考虑特征之间的相互作用/依赖关系来总结特征对模型预测的重要性。在确定一个特征的不同值(低或高)如何影响总体输出时很有用。
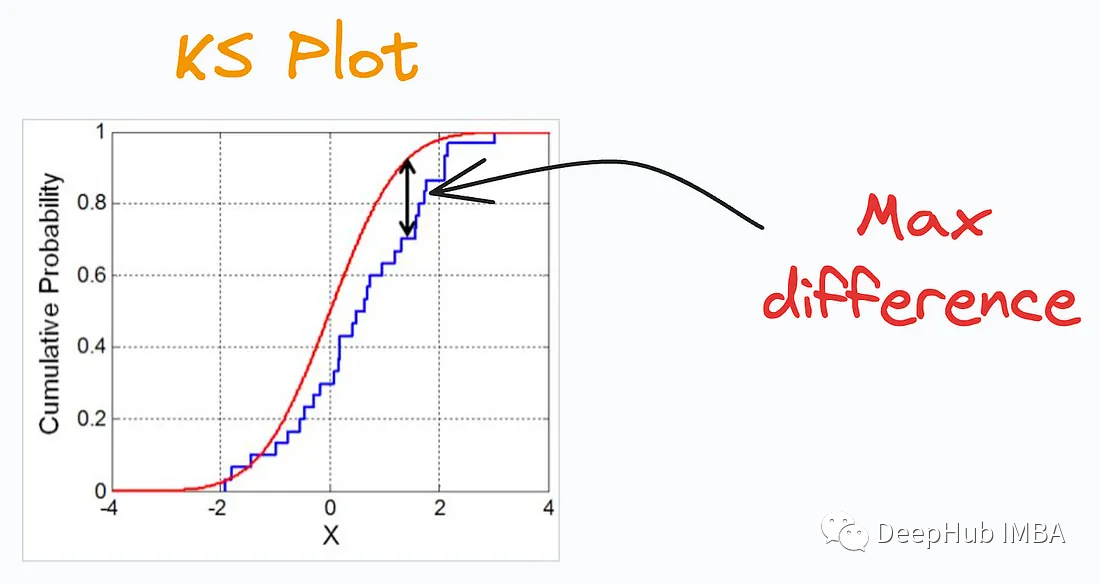
3、ROC Curve
ROC曲线描述了跨不同分类阈值的真阳性率(良好的性能)和假阳性率(糟糕的性能)之间的权衡。它展示了分类器在不同阈值下的灵敏度(True Positive Rate,TPR)和特异度(True Negative Rate,TNR)之间的权衡关系。
ROC曲线是一种常用的工具,特别适用于评估医学诊断测试、机器学习分类器、风险模型等领域的性能。通过分析ROC曲线和计算AUC,可以更好地理解分类器的性能,选择适当的阈值,以及比较不同模型之间的性能。
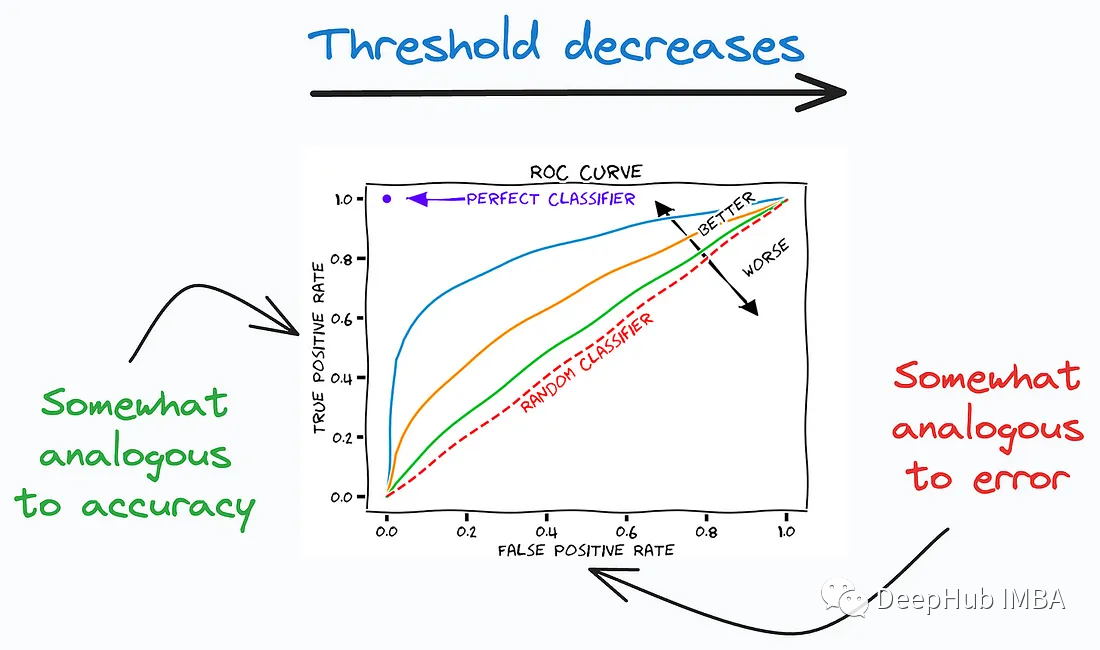
4、Precision-Recall Curve
Precision-Recall(精确度-召回率)曲线是用于评估分类模型性能的另一种重要工具,特别适用于不平衡类别分布的问题,其中正类别和负类别样本数量差异较大。这个曲线关注模型在正类别的预测准确性和能够找出所有真正正例的能力。它描述了不同分类阈值之间的精确率和召回率之间的权衡。
5、QQ Plot
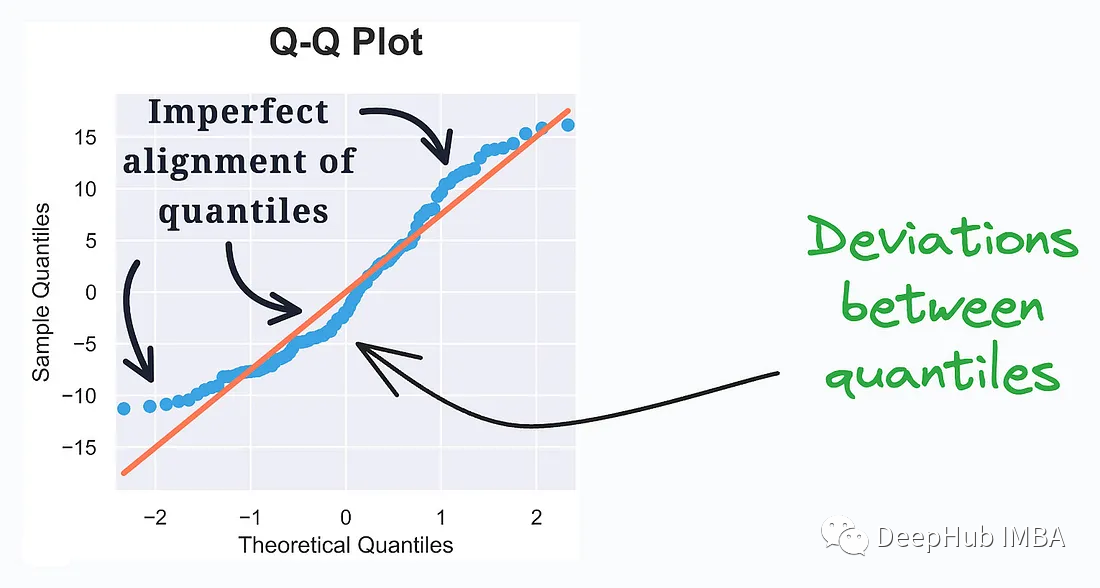
QQ Plot(Quantile-Quantile Plot,分位数-分位数图)是一种用于比较两个数据集的分位数分布是否相似的数据可视化工具。它通常用于检查一个数据集是否符合某种特定的理论分布,如正态分布。
它评估观测数据与理论分布之间的分布相似性。绘制了两个分布的分位数。偏离直线表示偏离假定的分布。
QQ Plot是一种直观的工具,可用于检查数据的分布情况,尤其是在统计建模和数据分析中。通过观察QQ Plot上的点的位置,你可以了解数据是否符合某种理论分布,或者是否存在异常值或偏差。
6、Cumulative Explained Variance Plot
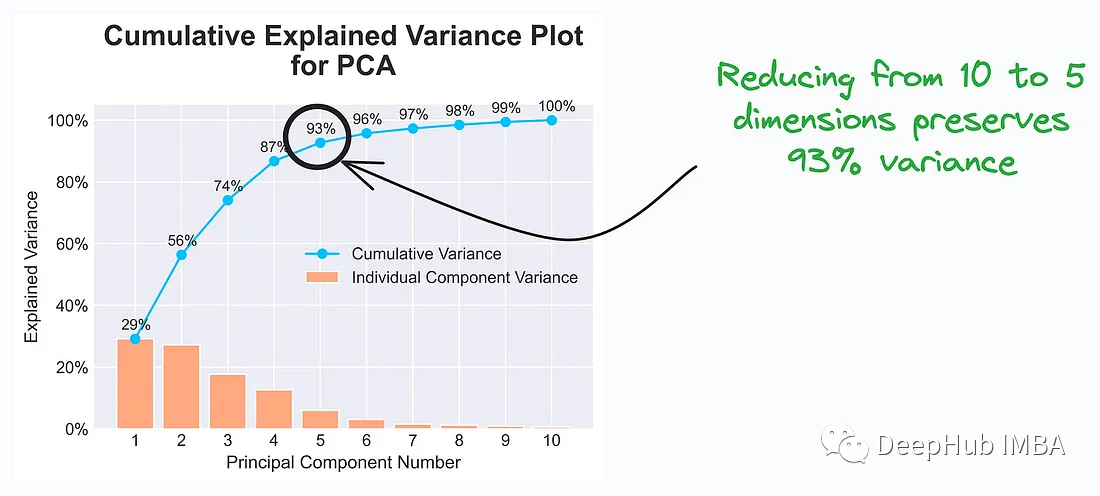
Cumulative Explained Variance Plot(累积解释方差图)是在主成分分析(PCA)等降维技术中常用的图表,用于帮助解释数据中包含的方差信息以及选择合适的维度来表示数据。
数据科学家和分析师会根据Cumulative Explained Variance Plot中的信息来选择适当数量的主成分,以便在降维后仍能够有效地表示数据的特征。这有助于减少数据维度,提高模型训练效率,并保留足够的信息来支持任务的成功完成。
7、Elbow Curve
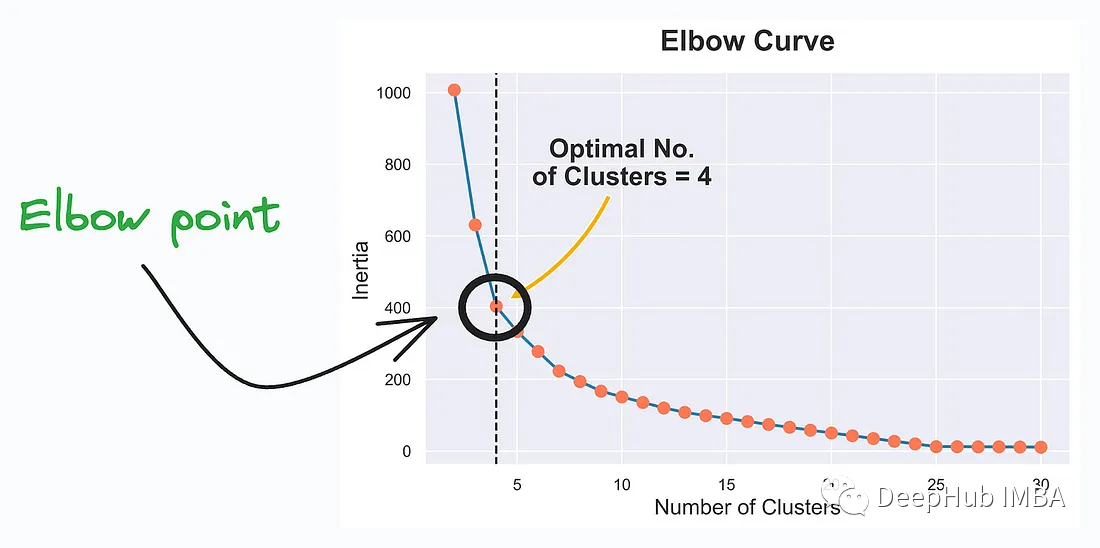
Elbow Curve(肘部曲线)是一种用于帮助确定K-Means聚类中最佳簇数(聚类数目)的可视化工具。K-Means是一种常用的无监督学习算法,用于将数据点分为不同的簇或群组。Elbow Curve有助于找到合适的簇数,以最好地表示数据的结构。
Elbow Curve是一种常用的工具,用于帮助选择K-Means聚类中的最佳簇数,肘部的点表示理想的簇数。这样可以更好地捕获数据的内在结构和模式。
8、Silhouette Curve
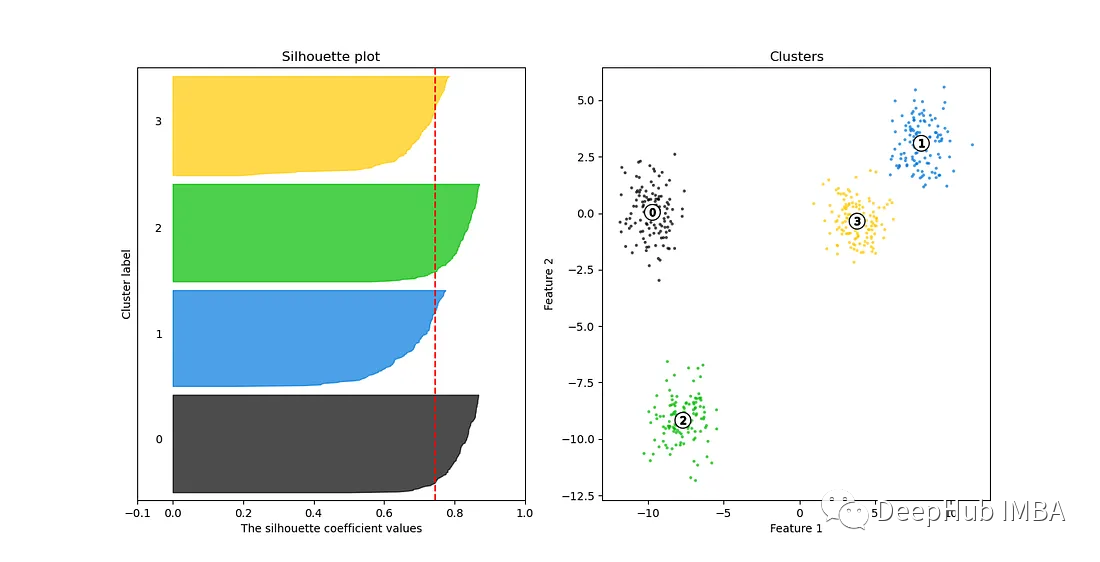
Silhouette Curve(轮廓系数曲线)是一种用于评估聚类质量的可视化工具,通常用于帮助选择最佳聚类数。轮廓系数是一种度量,用于衡量聚类中簇内数据点的相似性和簇间数据点的分离程度。
Silhouette Curve是一种有力的工具,用于帮助选择最佳的聚类数,以确保聚类模型能够有效地捕获数据的内在结构和模式。在有很多簇时,肘部曲线通常是无效的。Silhouette Curve是一个更好的选择。
9、Gini-Impurity and Entropy

Gini Impurity(基尼不纯度)和Entropy(熵)是两种常用于决策树和随机森林等机器学习算法中的指标,用于评估数据的不纯度和选择最佳分裂属性。它们都用于衡量数据集中的混乱度,以帮助决策树选择如何划分数据。
它们用于测量决策树中节点或分裂的杂质或无序。上图比较了基尼不纯和熵在不同的分裂,这可以提供了对这些度量之间权衡的见解。
两者都是有效的指标,用于决策树等机器学习算法中的节点分裂选择,但选择哪个取决于具体的问题和数据特征。
10、Bias-Variance Tradeoff
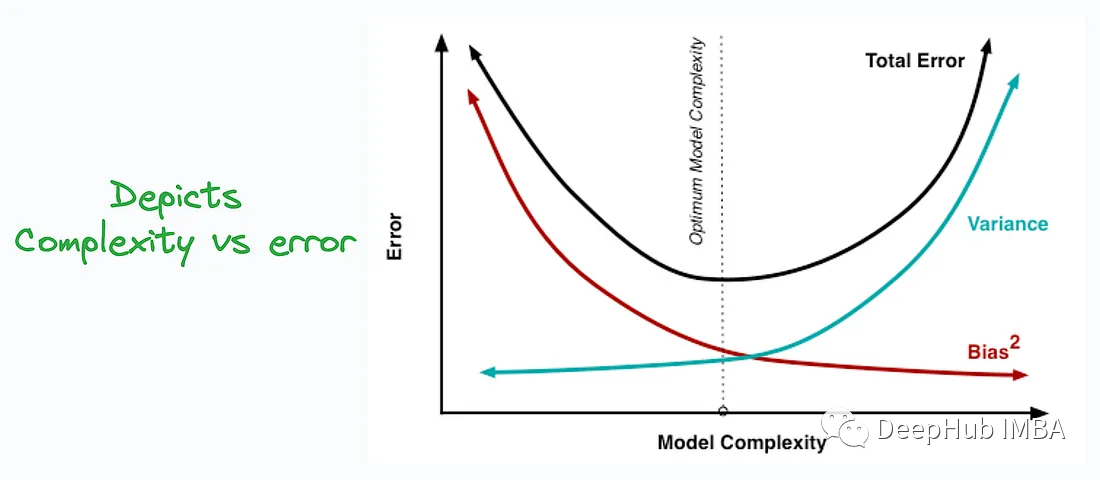
Bias-Variance Tradeoff(偏差-方差权衡)是机器学习中一个重要的概念,用于解释模型的预测性能和泛化能力之间的平衡。
偏差和方差之间存在权衡关系。在训练机器学习模型时,增加模型的复杂性通常会降低偏差但增加方差,而降低模型复杂性则会降低方差但增加偏差。因此,存在一个权衡点,其中模型既能够捕获数据的模式(降低偏差),又能够对不同数据表现出稳定的预测(降低方差)。
理解偏差-方差权衡有助于机器学习从业者更好地构建和调整模型,以实现更好的性能和泛化能力。它强调了模型的复杂性和数据集大小之间的关系,以及如何避免欠拟合和过拟合。
11、Partial Dependency Plots:
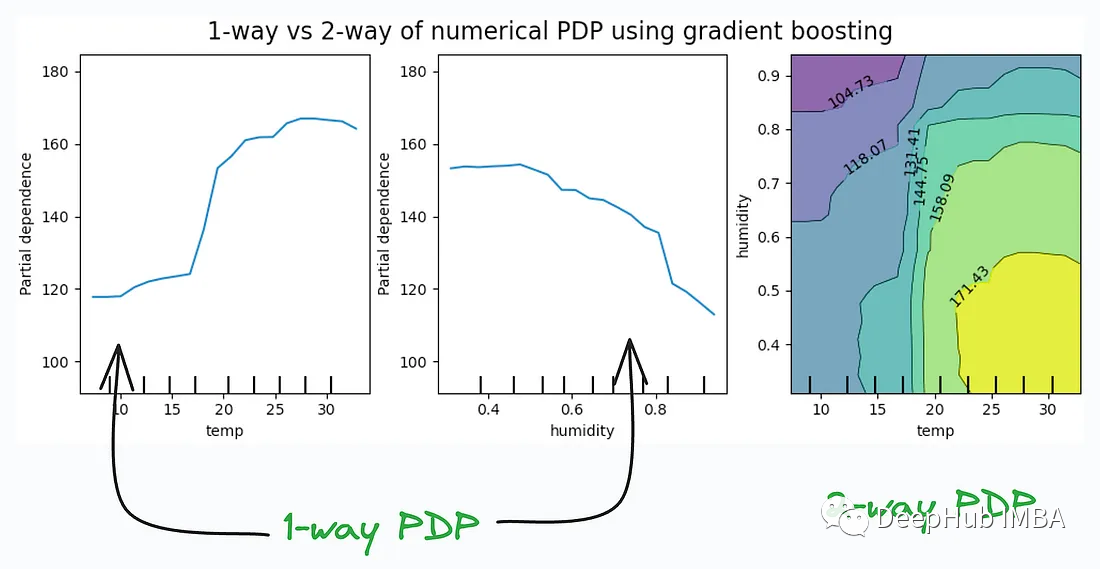
Partial Dependency Plots(部分依赖图)是一种用于可视化和解释机器学习模型的工具,特别适用于了解单个特征对模型预测的影响。这些图形有助于揭示特征与目标变量之间的关系,以便更好地理解模型的行为和决策。
Partial Dependency Plots通常与解释性工具和技术一起使用,如SHAP值、LIME等,以帮助解释黑盒机器学习模型的预测。它们提供了一种可视化方式,使数据科学家和分析师更容易理解模型的决策和特征之间的关系。
总结
这些图表涉及了数据分析和机器学习领域中常用的可视化工具和概念,这些工具和概念有助于评估和解释模型性能、理解数据分布、选择最佳参数和模型复杂性,以及洞察特征对预测的影响。
本文转自:DeepHub IMBA,转载此文目的在于传递更多信息,版权归原作者所有。如不支持转载,请联系小编demi@eetrend.com删除。





