作者:刘曼霞,闫秋女
来源:壁仞科技研究院
摘要
深度学习在图像分类、自然语言处理、自动驾驶等不同领域都取得了出色表现,但这些模型仍然面临着很多重大挑战和问题。由于深度学习只是从数据中捕捉简单的关联关系而缺乏因果性,造成模型产生错误的预测结果。比如,在进行图像分割时,由于图像中非目标物体、背景等混淆因子的存在,可能会产生像素与目标物体之间的伪相关关系。因此,如何让深度学习模型避免这种伪相关以提高模型的普适性和鲁棒性是一个重要的研究方向。
结构因果图是表达系统相互关联因子的数学模型,也是描述数据产生机制的有利工具。本文旨在探讨结构因果模型在深度学习的最新应用研究,并以文[4]的图像分类为例深入分析结构因果模型在深度学习中的具体实现思路。
基于结构因果图的图像生成
结构因果图是用于描述系统因果机制的概念模型,通过提供清晰的规则来决定系统决策所需要考虑的相关因素,有助于从统计数据中推断因果关系,常常以概率形式描述关系。Judea Pearl中的Hierarchy Causality Ladder更是描述了人工智能从低到高的三个演绎阶梯,结合结构因果图和统计学的关联性, 进一步提出了干预和反事实操作,使得基于反事实推理变得可能。
近年来,深度学习模型在很多应用领域突飞猛进,比如计算机视觉。然而,为了训练百亿级的深度学习模型,要求大量训练样本,这在很多应用场景并不是可行的。为了解决该问题,一种可行的方案是通过现有样本训练得到未曾在现有数据中出现的新样本,比如产生新的人脸图像。目前一种研究思路是借助结构因果图的结构化特征,从全局的角度描述人脸的主要构成元素,可以按照人脸的相关属性之间的结构关系生成图像,如年龄、性别、发型、眼睛等,其关系可用图1的因果图表示。
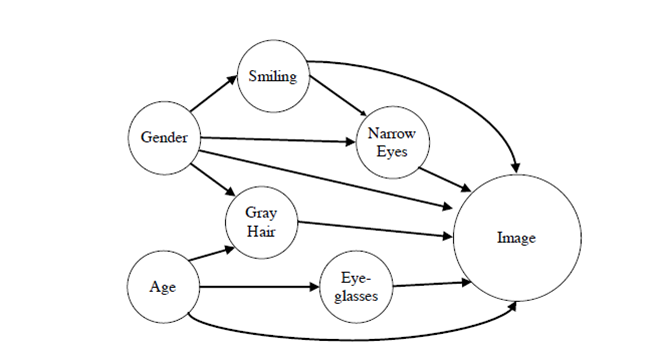
因果推断用于图像分类
基于上述因果图产生图像的思想,文[1]进一步引入了因果推断中的独立机制(Independent Mechanisms,IM)。独立机制是指存在独立自治而不相互干扰的模块。在文[4]的图像分类任务中,图像生成过程可以拆解成多个独立机制,也就是控制物体形状、纹理、背景的机制。这三个机制构成了图像生成的三个主要要素。文[4]提出了基于这种思想的反事实图像流程,如图2所示。

其中, 为第一个独立机制,其中0表示前景1表示物体,这个机制实现了前景分割。 负责产生前景物体的外貌,但不捕捉任何物体形状和背景信息; 捕捉背景的全局结构,三个独立机制中产生的形状 、前景 和背景 通过一个组合器函数生成一张反事实图像,并与真实的图像定义相应的loss函数,以使得生成的图像与真实图像最相近。这种方法的特点是能生成未曾在训练集中出现的图像,然后将这些图像用于训练一个图像分类器,可以使分类器更加鲁棒,并具备更强的迁移性。同时,可以将决定分类结果的多个分类器进行整合,从而使得分类结果对整张图像进行解耦,如图3、4所示,从而有助于解决训练样本与测试样本来自不同分布问题。


在图像分类任务上,文[4]假定因果结构图已知,并只考虑图像形状、纹理、背景三个独立机制。考虑到不同数据集的差异性,因果结构图在MNIST和ImageNet上表示略微不同,主要表现在背景机制上,如图4所示。在MNIST数据集上,可以通过包含第二层的纹理结构来取代背景机制。
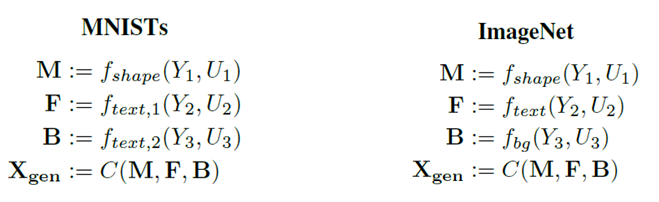
思考
深度学习通过堆叠流行的深度模块来解决各类问题,往往只捕捉到关联性而产生错误的预测结果。文[4]采用对因果推理的第三阶梯的反事实推理来解决模型的鲁棒性问题,主要是利用了反事实来生成未曾在训练数据中出现的样本,这种方法在很多深度学习模型领域得到了的诸多的应用。深度学习模型的鲁棒性和移植性是一个重要的研究方向,而结构因果图能系统地解释现实世界的数据生成/产生过程,这在图像应用能帮助避免获得伪关系。当然,因果科学也有很多其他的应用,如采用干预操作来达到类似目的[3]。
由于水平有限,文中存在不足的地方,请各位读者批评指正,也欢迎大家参与我们的讨论。
[1] Austin Derrow-Pinion, Jennifer She, David Wong, et al. ETA Predictionwith Graph Neural Networks in Google Maps. 2021
[2] Suter, Raphael, et al. "Robustly disentangled causal mechanisms: Validating deep representations for interventional robustness."ICML, 2019.
[3] Goyal, Yash, et al. "Explaining classifiers with causal concept effect (cace)." arXiv preprint arXiv:1907.07165 (2019).
[4] Kocaoglu, Murat, et al. "Causalgan: Learning causal implicit generative models with adversarial training." ICLR, 2018.
[5] Sauer, Axel, and Andreas Geiger. "Counterfactual generative networks." ICLR, 2021.
[6] Zhang, Dong, et al. "Causal intervention for weakly-supervised semantic segmentation." NeurIPS ,2020.
本文转自:壁仞科技研究院,转载此文目的在于传递更多信息,版权归原作者所有。如不支持转载,请联系小编demi@eetrend.com删除。





