要想理解神经网络参数初始化的方法,那就得从问题源头说起。
首先要说两个概念:确定性算法和非确定性算法,如果要对同一个数组排序,无论是冒泡排序还是快排,最终的排序结果和每次排序所用的时间和内存是固定的,也就是时间复杂度和空间复杂度不变,这就是确定性算法。非确定性算法在执行过程中存在随机过程,也就是即使针对同一个数据,使用同一个算法,每次执行也会有不同的执行步骤和结果。
神经网络的优化算法就是非确定性算法,不信你可以亲自尝试一下,同一个训练数据,训练多次,看看每一次模型的精度是否一样。
这里的神经网络指的是带有多层隐藏层的神经网络,多个隐藏层的累加,以及激活函数的作用,整个网络就相当于一个非常复杂的复合函数,此时的目标函数往往是非凸的,对于非凸的函数无法直接进行求解,一般使用迭代法,既然是迭代法,就需要在算法开始执行前对参数设置一个初始值,然后向梯度的反方向按照步长进行参数更新,直到满足迭代停止条件。
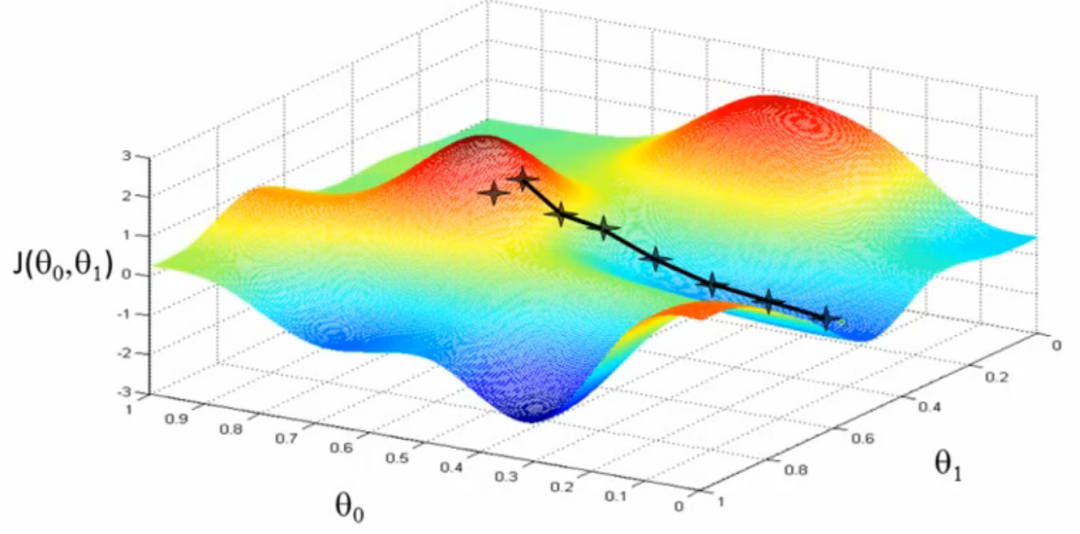
当然,但并不是所有模型的目标函数都是这样,例如,机器学习中的线性回归模型,其目标是拟合一条直线,使用最小二乘进行参数求解时,目标函数就是一个凸函数,对于凸函数的求解,可以使用直接法对其进行求导,导数等于0的参数值就是要求的最优解。即使使用梯度下降法,无论参数起始位置在哪,最终都会找到全局最优解。
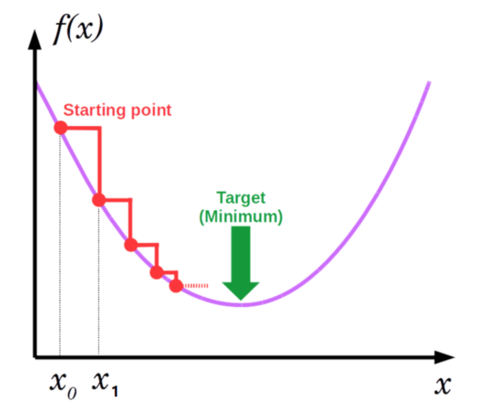
我们还是回到神经网络的话题上,既然需要对参数设置一个初始值 ,那这个初始值该怎么设置?不同的初始值又有什么影响呢?
参数的初始化方法很多,如下图所示,Keras中的参数初始化方法。

这里主要讨论比较受关注的两种情况。
第一,能否将参数全部或者部分初始化为0?
对于逻辑回归来说,把参数初始化为0是很ok的。但是对于一个神经网络,如果我们将权重或者是所有参数初始化为0,梯度下降算法将不会起到任何作用。
1. 为什么逻辑回归参数初始化为0是ok的?
下图所示,是logistic回归的图解:
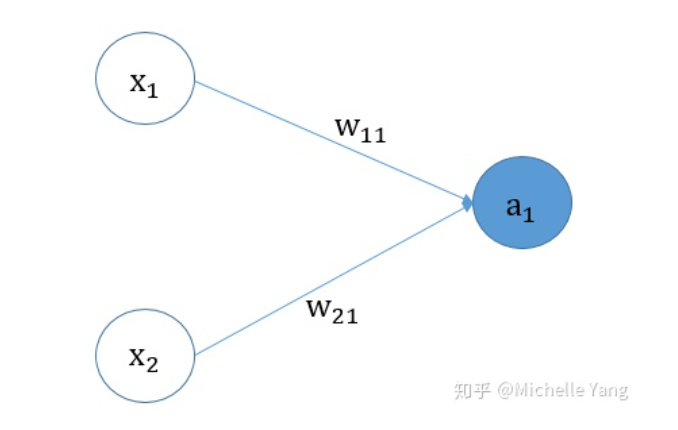
假设我们用梯度下降法来更新我们的模型参数。
logistic回归模型的前向传播:
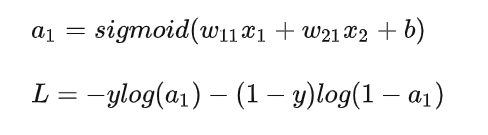
logistic回归模型的反向传播:
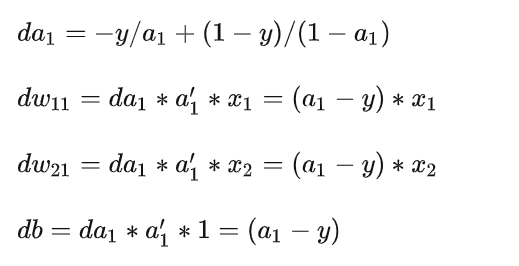
参数更新公式:
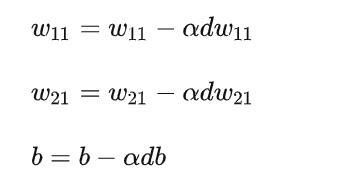
假设在logistic回归模型中,当我们把w11w21初始化为0的时候, dw11和dw12会因为输入x1和x2的不同,导致 dw11和dw12不同,且不为0,模型的权重能够得到更新。当b初始化也为0的时候, a1-y的值为0.5, db不为0,参数b也可以得到更新。
2. 为什么神经网络的权重或所有参数初始化为0,梯度下降不再work?
为了说明这个问题,我们以一个简单的神经网络为例,该神经网络只有1层隐藏层,包含2个神经元,其具体的神经网络的结构图如下图所示:
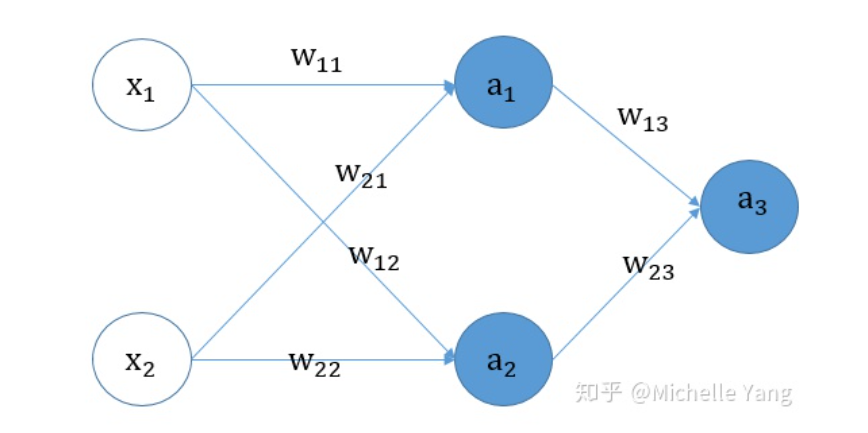
神经网络的前向传播
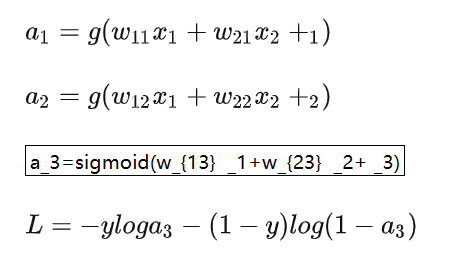
神经网络的反向传播所能用到的导数公式:
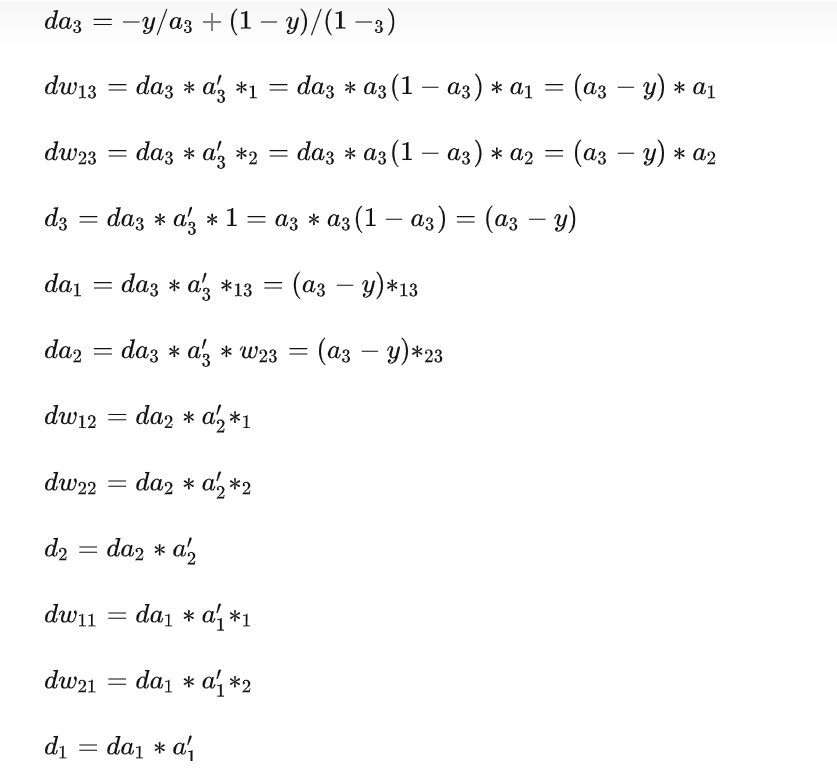
根据上述的详细公式,我们分析一下3种情况:
- 模型所有权重w初始化为0,所有偏置b初始化为0
- 模型所有权重w初始化为0,所有偏置b随机初始化
- 模型所有的权重w随机初始化,所有偏置b初始化为0
2.1 模型所有权重w初始化为0,所有偏置b初始化为0
在此情况下,前向传播计算过程中, a1=g(0),a2=g(0) ,a3=sigmoid(0),在反向传播进行参数更新的时候,会发现由于 a1和a2均相等,会导致 dw13 和 dw23相等,更新时 w13和 w23相等,出现权重的对称性。
由于所有权重初始化为0,这样在第一个batch反向传播的时候会导致 da1 和 da2相等且为0,这样导致的结果是什么呢?第一个batch反向传播除了w13和 w23以及 能够得到更新,其余权重均得不到更新。
当第二个batch传给神经网络之后,由于w13和 w23相等但不为0,会导致 da1 和 da2相等,这样会导致w11 和 w12相等,w21和 w22相等。
依次类推,无论训练多少次,无论我们隐藏层神经元有多少个,由于权重的对称性,我们的隐层的神经单元输出始终不变,出现隐藏神经元的对称性。我们希望不同神经元能够有不同的输出,这样的神经网络才有意义。
简单来说,就会出现同一隐藏层所有神经元的输出都一致,对于后期不同的batch,每一隐藏层的权重都能得到更新,但是存在每一隐藏层的隐藏神经元权重都是一致的,多个隐藏神经元的作用就如同1个神经元。
2.2 模型所有权重w初始化为0,所有偏置b随机初始化
在此情况下,第一个batch前向传播:a1=g(1),a2=g(2) ,a3=sigmoid(3),在反向传播的过程中,由于da1 和 da2均为0,导致 dw11 dw12 dw21 dw22均为0,则w11 w12 w21w22得不到更新,为0,模型参数能够得到更新的只有 w13 w23和 b3 。
同理,在第二个batch在反向传播的过程中,由于 w13和w23不为0,导致所有的参数都能够得到更新。这种方式存在更新较慢、梯度消失、梯度爆炸等问题,在实践中,通常不会选择此方式。
2.3 模型所有的权重w随机初始化,所有偏置b初始化为0
在此情况下,在前向传播计算过程中,
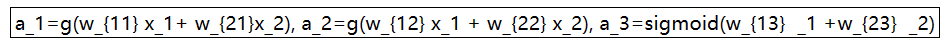
在反向传播的过程中所有权重的导数都不相同,所以权重和偏置b都能得到更新。
第二,每次训练能否将参数设置成相同的值?
神经网络的目标函数是非常复杂的非凸函数,有大量的局部最优点和鞍点,事实证明我们很难达到全局最优点,但能否足够幸运达到全局最优点或者能否达到比较好的局部最优点,具有很大的随机性,这种随机性主要来自于初始位置的选择,如果恰好选在了全局最优点的附近,那模型最终很大可能得到全局最优解,另一个随机性的来源是每一个batch的训练数据是随机挑选的,但它的影响力不如参数的初始值,所以,我们经常会训练多次,每一次都使用不同的参数值,然后挑选出性能最好的模型。
本文转自: 人工智能大讲堂,转载此文目的在于传递更多信息,版权归原作者所有。如不支持转载,请联系小编demi@eetrend.com删除。





