作者:leonwei
本文接着之前的文章《基于移动端tbdr特性gpu的渲染优化》,继续补充一些移动端渲染优化的点。
尽量使用direct rendering 模式,很多游戏使用了很多的后期处理,所以需要先渲染到贴图上,然后再一遍遍的blit 到屏幕上,blit操作是一个昂贵的操作,它涉及到对当前framelist data 的立即绘制(理论上framelist data越晚绘制越好,越利于延迟渲染),然后额外的framebuffer又增加了显存带宽的读取和写入。
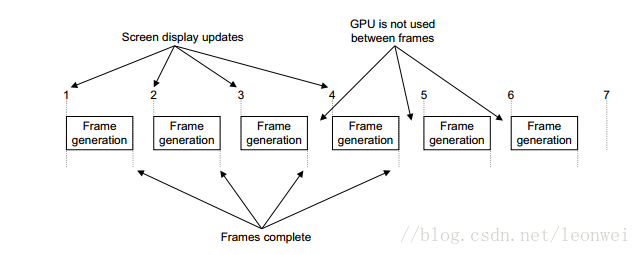
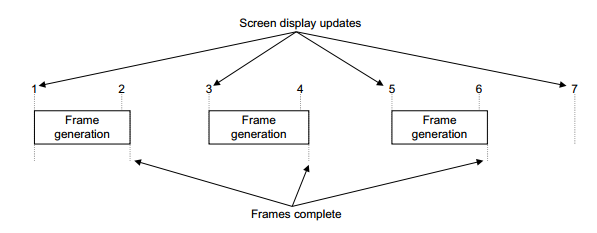
关于垂直同步,垂直同步首先有好处,例如在mali 的gpu上,设置垂直同步,同步帧率是30fps,显卡最多在两次同步间隔内绘制一次,这可以节省显卡的功耗,不过如果你的游戏帧率不够稳定,容易出现频繁的帧率低下,那么垂直同步有可能让情况变得更糟,例如一次较长的渲染结束后刚好遇到一次垂直同步刚开始,那么显卡又不得不等待下一次垂直同步过后才渲染,那么这次渲染就变得更长。
下面1是良好的垂直同步节省gpu功率的情况,2是一种不良好的情况
关于depth buffer, depth 的深度一般有16位 24位 32位,非32位的深度在gpu的cache性能不好,尽量考虑32bit
关于mipmapping,mipmap会增大内存,但是在之前我们更多的关注它的好处是增强了远处物体的渲染效果,不会因为小像素采样大贴图导致的闪烁,但是对于移动端带宽功耗严重的情况下,mipmap还可以极大的增强的cache的命中率,减少对显卡内存的直接访问,减少带宽资源
带宽,在移动端,bandwith是一个多种设备(cpu gpu audio等)共享的资源,而且处理器通过带宽对存储的访问是一个很耗电的操作,所以,尽可能的提高在gpu内部cache上访问的到的可能性,减少对内存访问。无论是对代码的cache,贴图的压缩,mimapmap都是在做这种努力
profile性能的时候尽量使用frametime而不用fps去统计,首先从profile上来讲能直接量化一帧性能的是帧时间,而帧率是帧时间的倒数,fps跟帧时间不是一个线性关系,例如从在每秒10fps的情况下,帧时间减少2ms,帧率只提高到10.2fps,而在25fps下,帧时间减少2ms,帧率确可以提高到26.3,所以可以看到在同样减少了时间消耗的情况下,在高帧率区间,减少相同的瓶颈,帧率会越来越快,而在低帧率区间,减少相同的瓶颈,确不能得到更大的进步,直观上说帧率是越优化越快的。结论就是我们通过fps的增长来衡量优化的好坏是不科学的,因为从30fps优化到35fps比从10fps优化到15fps要简单的多。
为什么drawcall这么慢?很多人讲我们要优化drawcall,并且说drawcall是优化了cpu瓶颈,而不是gpu瓶颈,为什么?drawcall字面上说不就是渲染次数么,那怎么就不是减少gpu瓶颈了?严格来说,这句话应该说是在几何数据量不变的情况下,分多个drawcall提交和少个drawcall提交对于cpu的性能损耗更大,首先从渲染上cpu和gpu是串联在前后的流水线上的两环,而gpu的运算能力要比cpu强很多,形象上可以看到gpu是一根粗水管,而cpu是一条细水管,在通常情况下,cpu提供过来的数据,对于gpu来说都是要更快处理完毕的,即cpu喂不饱gpu,也就是说对于相同量的数据,cpu连续的喂给gpu多次和一次喂多一点对于gpu来说区别不是很大,但是对于cpu就不一样的。一个drawcall涉及到渲染状态的设置和绘制数据的提交,在这个渲染状态的设置中,cpu端极有可能要发生(内存分配(api在cpu一侧的分配),数据拷贝(把数据从cpu一侧拷贝到gpu一侧,尽管移动端的显存和主存公用,但是数据存储的格式(如贴图)是不一样的,至少还要设计到格式的转换),组装command buffer,然后才能发送给gpu,这个过程中可能还要设计到同步和等待,例如一个vbo正在gpu被处理而我现在又要改变它重新告诉gpu怎么办,那是不是要等gpu处理完?如果不等待那是不是要复制一个新的?)。此外对同样一段大小的数据,分割成多个drawcall,导致了给gpu的数据流从多量少次变成了少量多次,使得gpu处于一种喂不饱状态,没有利用gpu的并行处理能力。 所以我们说drawcall是开销,不是说绘制次数多了成瓶颈,而是伴随着drawcall带来的cpu一侧的内存分配,数据拷贝,api调用,等待,同步,以及对gpu供给数据的低效造成的。
渲染是一个流水线,在这个流水线上先后发生的会影响性能的依次可以分为cpu api(drawcall), 几何处理(vertex geometry shader), 原语汇编,三角形建立,像素处理,带宽这6大块。性能瓶颈可能同时存在几块上,有时候我们需要屏蔽其中几块去定位性能瓶颈,例如通过profile工具把framebuffer设置到极小可以屏蔽pixel的处理,采样一个虚假的极小的贴图可以屏蔽带宽的因素等等。
版权声明:本文为CSDN博主「leonwei」的原创文章,
遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/leonwei/article/details/79616972





