随着科技的发展,具有超高分辨率视觉吸引力的图像变得越来越普遍。人们不再需要学习如何使用Photoshop和CorelDRAW等工具来增强和修改图像,因为AI可以在这些方面产生最佳效果的图像。然而,最新提出的想法实际上是综合使用AI来生成图像。
以往我们所看到的所有图像,其生成过程肯定都或多或少有“人”的参与。但是试想一下,一个计算机程序可以从零开始绘制你想要它绘制的任何内容,在不久的将来,你只需要给它一些指令,例如“我想要一张站在埃菲尔铁塔旁边的照片”,然后图像就生成了。

生成这种合成图像的基础就是生成对抗网络(GAN)。
那今天就带大家了解一下什么是GAN。
GAN的介绍
1. GAN(Generative Advrtsarial Networks)是一种无监督的深度学习模型,提出于2014年,被誉为“今年来复杂分布上无监督学习最具前景的方法之一”
2. GAN的模型主要组成
模型通过框架中(至少)两个模块:生成模型(Generative Model)和判别模型(Discriminative Model)的互相博弈学习产生相当好的输出。原始 GAN 理论中,并不要求 G 和 D 都是神经网络,只需要是能拟合相应生成和判别的函数即可。但实用中一般均使用深度神经网络作为 G 和 D 。一个优秀的GAN应用需要有良好的训练方法,否则可能由于神经网络模型的自由性而导致输出不理想。
{生成器G(generator)}
{判别器D(discriminator)}
3. GAN训练的目的
就是希望生成器G,能够学习到样本的分布Pdata(x),那么G就能生成之前不存在的但是却有很真实的样本。
GAN的发展历史
Ian J. Goodfellow等人于2014年10月在Generative Adversarial Networks中提出了一个通过对抗过程估计生成模型的新框架。框架中同时训练两个模型:捕获数据分布的生成模型G,和估计样本来自训练数据的概率的判别模型D。G的训练程序是将D错误的概率最大化。这个框架对应一个最大值集下限的双方对抗游戏。可以证明在任意函数G和D的空间中,存在唯一的解决方案,使得G重现训练数据分布,而D=0.5。在G和D由多层感知器定义的情况下,整个系统可以用反向传播进行训练。在训练或生成样本期间,不需要任何马尔可夫链或展开的近似推理网络。实验通过对生成的样品的定性和定量评估证明了本框架的潜力。
GAN的发展历史
机器学习的模型可大体分为两类,生成模型(Generative Model)和判别模型(Discriminative Model)。判别模型需要输入变量 ,通过某种模型来预测 。生成模型是给定某种隐含信息,来随机产生观测数据。
举个简单的例子:

判别模型:给定一张图,判断这张图里的动物是猫还是狗

生成模型:给一系列猫的图片,生成一张新的猫咪(不在数据集里)
对于判别模型,损失函数是容易定义的,因为输出的目标相对简单。但对于生成模型,损失函数的定义就不是那么容易。我们对于生成结果的期望,往往是一个暧昧不清,难以数学公理化定义的范式。所以不妨把生成模型的回馈部分,交给判别模型处理。这就是Goodfellow他将机器学习中的两大类模型,Generative和Discrimitive给紧密地联合在了一起 。
GAN的基本原理其实非常简单,这里以生成图片为例进行说明。假设我们有两个网络,G(Generator)和D(Discriminator)。正如它的名字所暗示的那样,它们的功能分别是:
G是一个生成图片的网络,它接收一个随机的噪声z,通过这个噪声生成图片,记做G(z)。
D是一个判别网络,判别一张图片是不是“真实的”。它的输入参数是x,x代表一张图片,输出D(x)代表x为真实图片的概率,如果为1,就代表100%是真实的图片,而输出为0,就代表不可能是真实的图片。
在训练过程中,生成网络G的目标就是尽量生成真实的图片去欺骗判别网络D。而D的目标就是尽量把G生成的图片和真实的图片分别开来。这样,G和D构成了一个动态的“博弈过程”。
最后博弈的结果是什么?在最理想的状态下,G可以生成足以“以假乱真”的图片G(z)。对于D来说,它难以判定G生成的图片究竟是不是真实的,因此D(G(z)) = 0.5。
这样我们的目的就达成了:我们得到了一个生成式的模型G,它可以用来生成图片。
Goodfellow从理论上证明了该算法的收敛性 ,以及在模型收敛时,生成数据具有和真实数据相同的分布(保证了模型效果)。
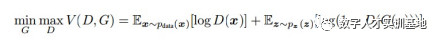
公式中x表示真实图片,z表示输入G网络的噪声,G(z)表示G网络生成的图片,D(·)表示D网络判断图片是否真实的概率。
GAN的应用
GAN最常使用的地方就是图像生成,如超分辨率任务(如果对该话题感兴趣,可看之前发表过的(超分辨率文章)),语义分割等等,在上文中我们也提到过。
1. 生成图像数据集案例
2014年,Ian Goodfellow等人发表论文《对抗式生成网络》,提出了生成新案例这一应用。文中指出,GAN可为MNIST手写数码数据集、CIFAR-10小件图片数据集、多伦多人像数据集生成新案例。

2015年,Alec Radford等人在一篇重要论文《使用深度回旋生成对抗网络进行无监督表示学习》,也表达了类似观点。论文指出,深度回旋生成对抗网络展示了大规模培养稳定GAN的方法。论文展示了生成卧室新案例的模型。

2. 生成人脸照片
Tero Karras等人在2017年发表的论文《GAN质量、稳定性及变化性的提高》展示了生成人脸照片的案例,照片十分逼真。因此,论文引起了媒体的广泛关注。生成照片时以名人的脸作为输入,导致生成的案例具有名人的脸部特征,让人感觉很熟悉,却并不认识。

3. 生成现实照片
Andrew Brock等人在2018年发表了题为《用于高保真自然图像合成的GAN规模化训练》的论文。论文展现了用BigGAN技术生成合成照片的案例。案例照片几乎与真实照片无异。

4. 生成动画角色
金杨华(音译)等人于2017年发表了题为《用GAN生成动画角色》的论文。论文展示了如何训练及应用GAN来生成动画头像(如日本动漫人物)。

5. 图像转换
GAN在这方面几乎无所不能,因为相关论文显示GAN可以执行许多图像转换任务。
Phillip Isola等人于2016年发表题为《使用GAN技术进行图像转换》的论文。论文特别介绍了如何使用GAN的pix2pix技术进行图像转换。

6. 文字-图片转化
Han Zhang等人于2016年发表题为《StackGAN:使用堆叠GAN技术进行文字-图片转化及合成》的论文。论文特别介绍了如何运用StackGAN将对于简单物体(如花鸟)的文字描述转化为现实图片。

7. 语义图像-图片转化
Ting-Chun Wang等人于2017年发表了题为《使用条件性GAN进行高清图片合成及语义操纵》的论文。文中介绍了使用条件性GAN根据语义图像或素描生成现实图片的方法。

8. 图片修复
Deepak Pathak等人于2016年发表了题为《文本编码器:通过图片修复学习特征》的论文。论文特别介绍了如何使用GAN的文本编码器进行图片修复或填充空缺,即填补图片中某块缺失的部分。

本文转自:数字人才实训基地,转载此文目的在于传递更多信息,版权归原作者所有。如不支持转载,请联系小编demi@eetrend.com删除。





