一、简述
我们现在一直使用的光照方式叫做正向渲染(Forward Rendering)或者正向着色法(Forward Shading),它是我们渲染物体的一种非常直接的方式,在场景中我们根据所有光源照亮一个物体,之后再渲染下一个物体,以此类推。它非常容易理解,也很容易实现,但是同时它对程序性能的影响也很大,因为对于每一个需要渲染的物体,程序都要对每一个光源每一个需要渲染的片段进行迭代,这是非常多的!因为大部分片段着色器的输出都会被之后的输出覆盖,正向渲染还会在场景中因为高深的复杂度(多个物体重合在一个像素上)浪费大量的片段着色器运行时间。
延迟着色法(Deferred Shading),或者说是延迟渲染(Deferred Rendering),为了解决上述问题而诞生了,它大幅度地改变了我们渲染物体的方式。这给我们优化拥有大量光源的场景提供了很多的选择,因为它能够在渲染上百甚至上千光源的同时还能够保持能让人接受的帧率。
下面这张对比图片包含了一共500个点光源,它是使用正向渲染与延迟渲染进行了对比:

二、原理
延迟着色法基于我们延迟(Defer)或推迟(Postpone)大部分计算量非常大的渲染(像是光照)到后期进行处理的想法。它包含两个处理阶段(Pass):
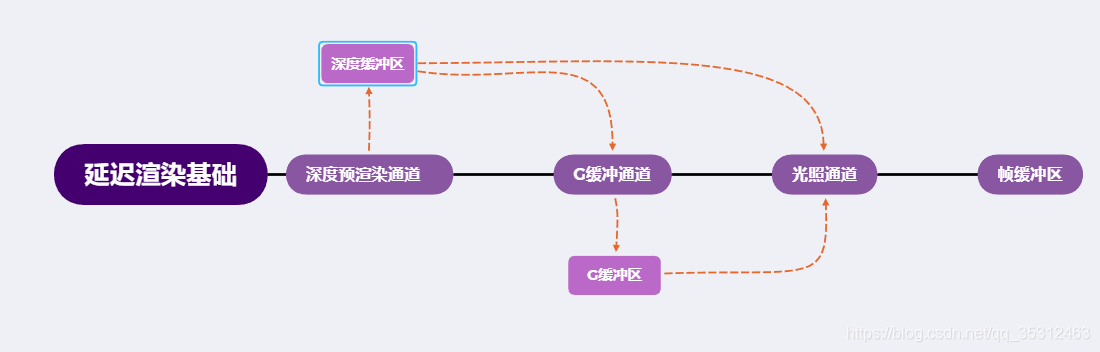
2.1 几何处理阶段(Geometry Pass)
在第一个几何处理阶段(Geometry Pass)中,我们先渲染场景一次,之后获取对象的各种几何信息,并储存在一系列叫做G缓冲(G-buffer)的纹理中;想想位置向量(Position Vector)、颜色向量(Color Vector)、法向量(Normal Vector)和/或镜面值(Specular Value)。场景中这些储存在G缓冲中的几何信息将会在之后用来做(更复杂的)光照计算。
下面是一帧中G缓冲的内容:

2.2 光照处理阶段(Lighting Pass)
我们会在第二个光照处理阶段(Lighting Pass)中使用G缓冲内的纹理数据。在光照处理阶段中,我们渲染一个屏幕大小的方形,并使用G缓冲中的几何数据对每一个片段计算场景的光照;在每个像素中我们都会对G缓冲进行迭代。我们对于渲染过程进行解耦,将它高级的片段处理挪到后期进行,而不是直接将每个对象从顶点着色器带到片段着色器。光照计算过程还是和我们以前一样,但是现在我们需要从对应的G缓冲而不是顶点着色器(和一些uniform变量)那里获取输入变量了。
这种渲染方法一个很大的好处就是能保证在G缓冲中的片段和在屏幕上呈现的像素所包含的片段信息是一样的,因为深度测试已经最终将这里的片段信息作为最顶层的片段。这样保证了对于在光照处理阶段中处理的每一个像素都只处理一次,所以我们能够省下很多无用的渲染调用。除此之外,延迟渲染还允许我们做更多的优化,从而渲染更多的光源。
当然这种方法也带来几个缺陷, 由于G缓冲要求我们在纹理颜色缓冲中存储相对比较大的场景数据,这会消耗比较多的显存,尤其是类似位置向量之类的需要高精度的场景数据。 另外一个缺点就是他不支持混色(因为我们只有最前面的片段信息), 因此也不能使用MSAA了。针对这几个问题我们可以做一些变通来克服这些缺点,这些我们留会在教程的最后讨论。
在几何处理阶段中填充G缓冲非常高效,因为我们直接储存像素位置,颜色或者是法线等对象信息到帧缓冲中,而这几乎不会消耗处理时间。在此基础上使用多渲染目标(Multiple Render Targets, MRT)技术,我们甚至可以在一个渲染处理之内完成这所有的工作。
2.3 vulkan流程图
三、代码应用
3.1 G缓冲
G缓冲(G-buffer)是对所有用来储存光照相关的数据,并在最后的光照处理阶段中使用的所有纹理的总称。趁此机会,让我们顺便复习一下在正向渲染中照亮一个片段所需要的所有数据:
- 一个3D位置向量来计算(插值)片段位置变量供lightDir和viewDir使用
- 一个RGB漫反射颜色向量,也就是反照率(Albedo)
- 一个3D法向量来判断平面的斜率
- 一个镜面强度(Specular Intensity)浮点值
- 所有光源的位置和颜色向量
- 玩家或者观察者的位置向量
有了这些(逐片段)变量的处置权,我们就能够计算我们很熟悉的布林-冯氏光照(Blinn-Phong Lighting)了。光源的位置,颜色,和玩家的观察位置可以通过uniform变量来设置,但是其它变量对于每个对象的片段都是不同的。如果我们能以某种方式传输完全相同的数据到最终的延迟光照处理阶段中,我们就能计算与之前相同的光照效果了,尽管我们只是在渲染一个2D方形的片段。
Vulkan并没有限制我们能在纹理中能存储的东西,所以现在你应该清楚在一个或多个屏幕大小的纹理中储存所有逐片段数据并在之后光照处理阶段中使用的可行性了。因为G缓冲纹理将会和光照处理阶段中的2D方形一样大,我们会获得和正向渲染设置完全一样的片段数据,但在光照处理阶段这里是一对一映射。
对于每一个片段我们需要储存的数据有:一个位置向量、一个法向量,一个颜色向量,一个镜面强度值。所以我们在几何处理阶段中需要渲染场景中所有的对象并储存这些数据分量到G缓冲中。我们可以再次使用多渲染目标(Multiple Render Targets)来在一个渲染处理之内渲染多个颜色缓冲。
对于几何渲染处理阶段,我们首先需要初始化一个帧缓冲对象,我们很直观的称它为gBuffer,它包含了多个颜色缓冲和一个单独的深度渲染缓冲对象(Depth Renderbuffer Object)。对于位置和法向量的纹理,我们希望使用高精度的纹理(每分量16或32位的浮点数),而对于反照率和镜面值,使用默认的纹理(每分量8位浮点数)就够了。
// Prepare a new framebuffer and attachments for offscreen rendering (G-Buffer)
void prepareOffscreenFramebuffer()
{
// Color attachments
...
// (World space) Positions
...
// (World space) Normals
...
// Albedo (color)
...
// Depth attachment
...
// Init attachment properties
...
vkCreateFramebuffer(device, &fbufCreateInfo, nullptr, &offScreenFrameBuf.frameBuffer);
}
由于我们使用了多渲染目标,我们需要显式告诉Vulkan我们需要使用vkCmdBindIndexBuffer渲染的是和GBuffer关联的哪个颜色缓冲。在vkCmdBindPipeline中使用的管线其对应的描述符局中,我们需要对其进行指明绑定,否则的话将会看不到任何图形。
void preparePipelines()
{
...
// Blend attachment states required for all color attachments
// This is important, as color write mask will otherwise be 0x0 and you
// won't see anything rendered to the attachment
std::array<VkPipelineColorBlendAttachmentState, 3> blendAttachmentStates = {
vks::initializers::pipelineColorBlendAttachmentState(0xf, VK_FALSE),
vks::initializers::pipelineColorBlendAttachmentState(0xf, VK_FALSE),
vks::initializers::pipelineColorBlendAttachmentState(0xf, VK_FALSE)
};
colorBlendState.attachmentCount = static_cast<uint32_t>(blendAttachmentStates.size());
colorBlendState.pAttachments = blendAttachmentStates.data();
VK_CHECK_RESULT(vkCreateGraphicsPipelines(device, pipelineCache, 1, &pipelineCreateInfo, nullptr, &pipelines.offscreen));
}
接下来我们需要渲染它们到G缓冲中。假设每个对象都有漫反射,一个法线和一个镜面强度纹理,我们会想使用一些像下面这个顶点和片段着色器的东西来渲染它们到G缓冲中去。
顶点着色器:
#version 450
layout (location = 0) in vec4 inPos;
layout (location = 1) in vec2 inUV;
layout (location = 2) in vec3 inColor;
layout (location = 3) in vec3 inNormal;
layout (location = 4) in vec3 inTangent;
layout (binding = 0) uniform UBO
{
mat4 projection;
mat4 model;
mat4 view;
vec4 instancePos[3];
} ubo;
layout (location = 0) out vec3 outNormal;
layout (location = 1) out vec2 outUV;
layout (location = 2) out vec3 outColor;
layout (location = 3) out vec3 outWorldPos;
layout (location = 4) out vec3 outTangent;
out gl_PerVertex
{
vec4 gl_Position;
};
void main()
{
vec4 tmpPos = inPos + ubo.instancePos[gl_InstanceIndex];
gl_Position = ubo.projection * ubo.view * ubo.model * tmpPos;
outUV = inUV;
outUV.t = 1.0 - outUV.t;
// 世界空间中的顶点位置
outWorldPos = vec3(ubo.model * tmpPos);
// OpenGL转Vulkan坐标系
outWorldPos.y = -outWorldPos.y;
// 世界空间中的法线
mat3 mNormal = transpose(inverse(mat3(ubo.model)));
outNormal = mNormal * normalize(inNormal);
outTangent = mNormal * normalize(inTangent);
// 当前仅顶点颜色
outColor = inColor;
}
片元着色器:
#version 450
layout (binding = 1) uniform sampler2D samplerColor;
layout (binding = 2) uniform sampler2D samplerNormalMap;
layout (location = 0) in vec3 inNormal;
layout (location = 1) in vec2 inUV;
layout (location = 2) in vec3 inColor;
layout (location = 3) in vec3 inWorldPos;
layout (location = 4) in vec3 inTangent;
layout (location = 0) out vec4 outPosition;
layout (location = 1) out vec4 outNormal;
layout (location = 2) out vec4 outAlbedo;
void main()
{
// 存储第一个G缓冲纹理中的片段位置向量
outPosition = vec4(inWorldPos, 1.0);
// 计算在切线空间中的法线
vec3 N = normalize(inNormal);
N.y = -N.y;
vec3 T = normalize(inTangent);
vec3 B = cross(N, T);
mat3 TBN = mat3(T, B, N);
// 同样存储对每个逐片段法线到G缓冲中
vec3 tnorm = TBN * normalize(texture(samplerNormalMap, inUV).xyz * 2.0 - vec3(1.0));
// 同样存储对每个逐片段法线到G缓冲中
outNormal = vec4(tnorm, 1.0);
// 存储镜面强度和漫反射对每个逐片段颜色
outAlbedo = texture(samplerColor, inUV);
}
因为我们使用了多渲染目标,这个布局指示符(Layout Specifier)告诉了Vulkan我们需要渲染到当前的活跃帧缓冲中的哪一个颜色缓冲。注意我们并没有储存镜面强度到一个单独的颜色缓冲纹理中,因为我们可以储存它单独的浮点值到其它颜色缓冲纹理的alpha分量中。
下一步,我们就该进入到:光照处理阶段了。
3.1 延迟光照处理阶段
现在我们已经有了一大堆的片段数据储存在G缓冲中供我们处置,我们可以选择通过一个像素一个像素地遍历各个G缓冲纹理,并将储存在它们里面的内容作为光照算法的输入,来完全计算场景最终的光照颜色。由于所有的G缓冲纹理都代表的是最终变换的片段值,我们只需要对每一个像素执行一次昂贵的光照运算就行了。这使得延迟光照非常高效,特别是在需要调用大量重型片段着色器的复杂场景中。
对于这个光照处理阶段,我们将会渲染一个2D全屏的方形(有一点像后期处理效果)并且在每个像素上运行一个昂贵的光照片段着色器。
在buildCommandBuffers绘制中我们使用vkCmdBindDescriptorSets绑定描述符布局之前,我们应在setupDescriptorSet函数中先绑定G缓冲中所有相关的纹理,并且发送光照相关的uniform变量到着色器中。
void setupDescriptorSet()
{
std::vector<VkWriteDescriptorSet> writeDescriptorSets;
// Textured quad descriptor set
VkDescriptorSetAllocateInfo allocInfo =
vks::initializers::descriptorSetAllocateInfo(
descriptorPool,
&descriptorSetLayout,
1);
VK_CHECK_RESULT(vkAllocateDescriptorSets(device, &allocInfo, &descriptorSet));
// Image descriptors for the offscreen color attachments
VkDescriptorImageInfo texDescriptorPosition =
vks::initializers::descriptorImageInfo(
colorSampler,
offScreenFrameBuf.position.view,
VK_IMAGE_LAYOUT_SHADER_READ_ONLY_OPTIMAL);
VkDescriptorImageInfo texDescriptorNormal =
vks::initializers::descriptorImageInfo(
colorSampler,
offScreenFrameBuf.normal.view,
VK_IMAGE_LAYOUT_SHADER_READ_ONLY_OPTIMAL);
VkDescriptorImageInfo texDescriptorAlbedo =
vks::initializers::descriptorImageInfo(
colorSampler,
offScreenFrameBuf.albedo.view,
VK_IMAGE_LAYOUT_SHADER_READ_ONLY_OPTIMAL);
writeDescriptorSets = {
// Binding 0 : Vertex shader uniform buffer
vks::initializers::writeDescriptorSet(
descriptorSet,
VK_DESCRIPTOR_TYPE_UNIFORM_BUFFER,
0,
&uniformBuffers.vsFullScreen.descriptor),
// Binding 1 : Position texture target
vks::initializers::writeDescriptorSet(
descriptorSet,
VK_DESCRIPTOR_TYPE_COMBINED_IMAGE_SAMPLER,
1,
&texDescriptorPosition),
// Binding 2 : Normals texture target
vks::initializers::writeDescriptorSet(
descriptorSet,
VK_DESCRIPTOR_TYPE_COMBINED_IMAGE_SAMPLER,
2,
&texDescriptorNormal),
// Binding 3 : Albedo texture target
vks::initializers::writeDescriptorSet(
descriptorSet,
VK_DESCRIPTOR_TYPE_COMBINED_IMAGE_SAMPLER,
3,
&texDescriptorAlbedo),
// Binding 4 : Fragment shader uniform buffer
vks::initializers::writeDescriptorSet(
descriptorSet,
VK_DESCRIPTOR_TYPE_UNIFORM_BUFFER,
4,
&uniformBuffers.fsLights.descriptor),
};
vkUpdateDescriptorSets(device, static_cast<uint32_t>(writeDescriptorSets.size()), writeDescriptorSets.data(), 0, NULL);
...
}
光照处理阶段的片段着色器和我们之前一直在用的光照教程着色器是非常相似的,除了我们添加了一个新的方法,从而使我们能够获取光照的输入变量,当然这些变量我们会从G缓冲中直接采样。
#version 450
layout (binding = 1) uniform sampler2D samplerposition;
layout (binding = 2) uniform sampler2D samplerNormal;
layout (binding = 3) uniform sampler2D samplerAlbedo;
layout (location = 0) in vec2 inUV;
layout (location = 0) out vec4 outFragcolor;
struct Light {
vec4 position;
vec3 color;
float radius;
};
layout (binding = 4) uniform UBO
{
Light lights[6];
vec4 viewPos;
} ubo;
void main()
{
// 从G缓冲中获取数据
vec3 fragPos = texture(samplerposition, inUV).rgb;
vec3 normal = texture(samplerNormal, inUV).rgb;
vec4 albedo = texture(samplerAlbedo, inUV);
#define lightCount 6
#define ambient 0.0
// 环境光部分
vec3 fragcolor = albedo.rgb * ambient;
for(int i = 0; i < lightCount; ++i)
{
// 像素点到光源方向
vec3 L = ubo.lights[i].position.xyz - fragPos;
// 光源到像素点距离
float dist = length(L);
// 像素点到相机方向
vec3 V = ubo.viewPos.xyz - fragPos;
V = normalize(V);
if(dist < ubo.lights[i].radius)
{
// 像素点到光源方向向量单位化
L = normalize(L);
// 衰减系数
float atten = ubo.lights[i].radius / (pow(dist, 2.0) + 1.0);
// 漫反射部分
vec3 N = normalize(normal);
float NdotL = max(0.0, dot(N, L));
vec3 diff = ubo.lights[i].color * albedo.rgb * NdotL * atten;
// 镜面反射部分
// Specular map values are stored in alpha of albedo mrt
vec3 R = reflect(-L, N);
float NdotR = max(0.0, dot(R, V));
vec3 spec = ubo.lights[i].color * albedo.a * pow(NdotR, 16.0) * atten;
fragcolor += diff + spec;
}
}
outFragcolor = vec4(fragcolor, 1.0);
}
光照处理阶段着色器接受三个uniform纹理,代表G缓冲,它们包含了我们在几何处理阶段储存的所有数据。如果我们现在再使用当前片段的纹理坐标采样这些数据,我们将会获得和之前完全一样的片段值,这就像我们在直接渲染几何体。在片段着色器的一开始,我们通过一个简单的纹理查找从G缓冲纹理中获取了光照相关的变量。注意我们从gAlbedoSpec纹理中同时获取了Albedo颜色和Spqcular强度。
因为我们现在已经有了必要的逐片段变量(和相关的uniform变量)来计算布林-冯氏光照(Blinn-Phong Lighting),我们不需要对光照代码做任何修改了。我们在延迟着色法中唯一需要改的就是获取光照输入变量的方法。
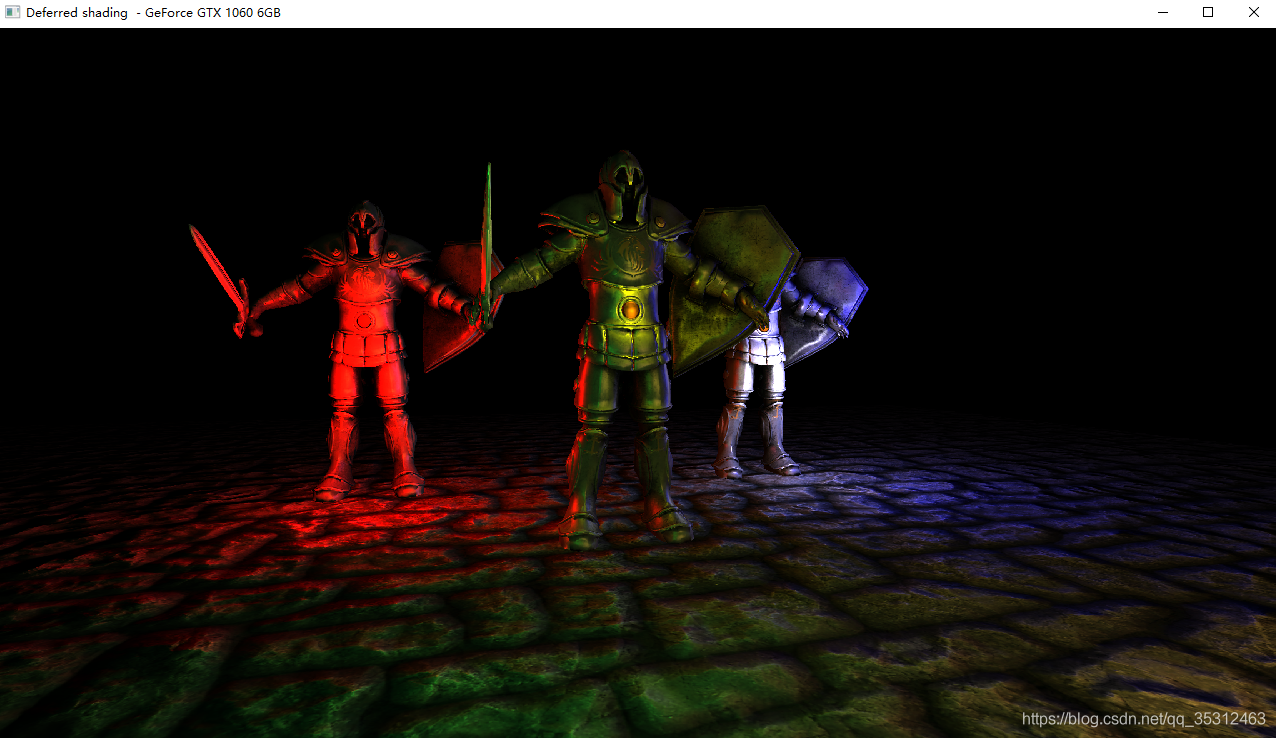
运行一个包含6个小光源的简单Demo会是像这样子的:
四、延迟渲染小结
延迟渲染的其中一个缺点就是它不能进行混合(Blending),因为G缓冲中所有的数据都是从一个单独的片段中来的,而混合需要对多个片段的组合进行操作。延迟着色法另外一个缺点就是它迫使你对大部分场景的光照使用相同的光照算法,你可以通过包含更多关于材质的数据到G缓冲中来减轻这一缺点。
为了克服这些缺点(特别是混合),我们通常分割我们的渲染器为两个部分:一个是延迟渲染的部分,另一个是专门为了混合或者其他不适合延迟渲染管线的着色器效果而设计的的正向渲染的部分。
版权声明:本文为博主 沉默的舞台剧 原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/qq_35312463/article/details/105878760





