导语
CPU和GPU是共享一份内存的吗?腾讯游戏学院专家Donald将在本文尝试以一张贴图纹理的虚拟内存占用为例,解答一些内存方面的问题。本篇主要分析iOS系统。
开发手机游戏时,常听到身边的人传授经验:“CPU和GPU是共享一份内存的”,但这句经验到底具体指的是什么,仿佛总得不到细节精确的回答。
因此,本文尝试以一张贴图纹理的虚拟内存占用为例,就以下问题进行分析和解答:
1)是否的确主存显存共享一份贴图虚拟内存?
2)如果问题1证实的确只有一份,纹理虚拟内存的完整流程是怎样?Unity将该纹理文件在主存加载好纹理数据后,是直接调用图形API传递该主存指针,从而GPU能直接访问该主存中的纹理数据?还是需要调用图形API将该主存中的纹理数据拷贝到另一份虚拟内存中,以供GPU访问?拷贝完成后纹理主存部分如何处置?
术语
为清晰表达避免概念混淆,本文采取以下术语:
物理内存(Physical Memory):具体的存储硬件,各种SDRAM,比如LPDDR是移动设备常用的一种低功耗SDRAM。
虚拟内存(Virtual Memory):对物理内存的一种逻辑映射。
主存(Main Memory/Primary Memory):CPU能读写的虚拟内存。
显存(Graphics Memory):GPU能读写的虚拟内存。
另外,外存(External storage):外部存储,“硬盘”,在移动设备一般是Flash。
iOS篇
2.1 硬件
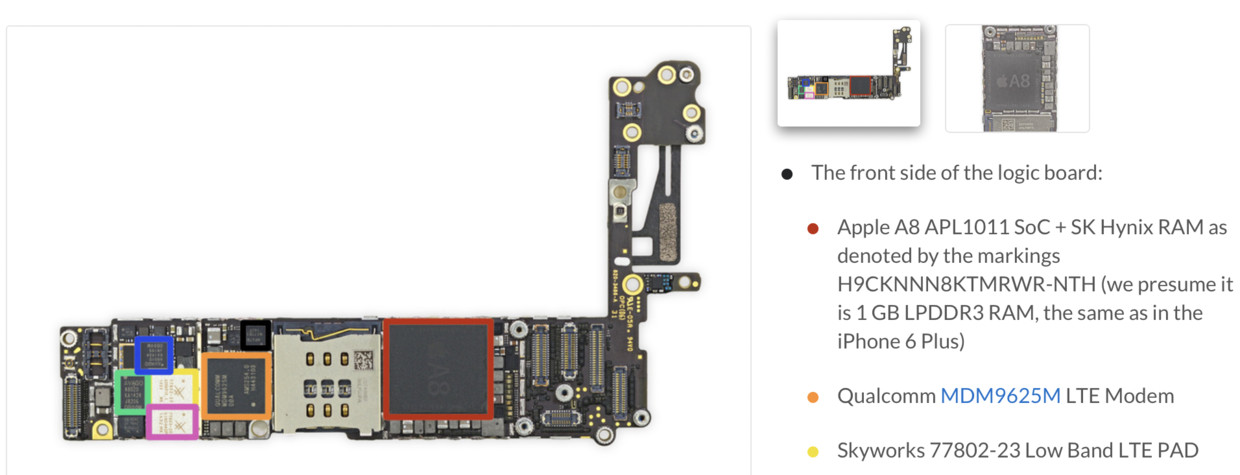
如下4图[1][2]所示,iPhone6只有A8里拥有一块物理内存(1GB LPDDR3 RAM),且CPU/GPU晶片中并无物理内存(SDRAM),只有物理内存的接口(SDRAM Interface)。
且A8采取PoP封装(Package on Package),即将CPU/GPU晶片和物理内存竖直排列于A8芯片中,将CPU/GPU晶片移除后,在下一层露出了它俩共用的一块物理内存。
注:晶片中有高速Cache缓存,类型为SRAM。


其他iOS设备,iPhone、iPad等,亦如此,硬件层面,它们的物理内存都为统一内存(Unified Memory)架构,即主存和显存都位于同样的物理内存硬件中。
而桌面电脑一般是分离物理内存(Discrete Memory)架构。
2.2 图形API
自2013年的AppleA7(iPhone 5s)起iOS设备便支持Metal[3],考虑当下(2018)的市场份额,故只讨论支持Metal的情况,而不讨论iOS上OpenGLES的情况。
系统层面,Metal支持主存显存同时访问同一块虚拟内存,即MTLBuffer的options为MTLStorageModeShared[4,5,6],此情况已无主存显存之分,Shared模式是Buffer(比如顶点缓存、索引缓存)的默认创建模式,在iOS中Shared也是纹理缓存的默认创建模式。
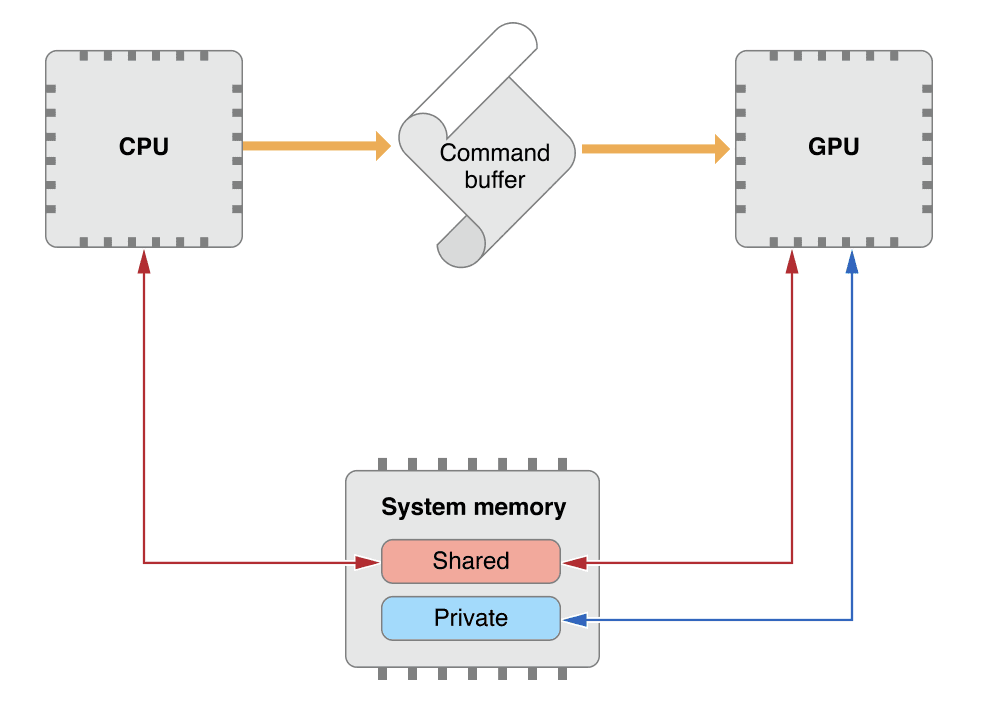
此时对该虚拟内存的修改,会同时反馈到CPU和GPU上,除非CPU准备好Buffer的内容后不再修改,但一旦CPU对Buffer进行了二次修改,为避免和GPU的访问冲突,需要有一定的同步机制,比如三重缓冲(Tripple Buffering)[7]。
Pirvate模式为GPU单独访问的虚拟内存,主要用于RenderTexture等情况[9],并非当前重点。
2.3 分析Unity在iOS的实现
虽然图形API机制如此,但引擎内部实现大相径庭,保守起见,具体结论应以引擎具体逻辑为准。
先以纹理为例,Unity在iOS+Metal上从纹理文件存储到最终纹理显存,其二进制流的完整流程是怎样的?
人肉阅读分析Unity源码是耗时且可能不准确的。结合Profiler等工具进行分析,会省时精确,事半功倍。这样也可顺带对Profile工具的综合应用进行介绍。所以下面,先假设我们不知道Metal的机制,试从现象推断出原因。
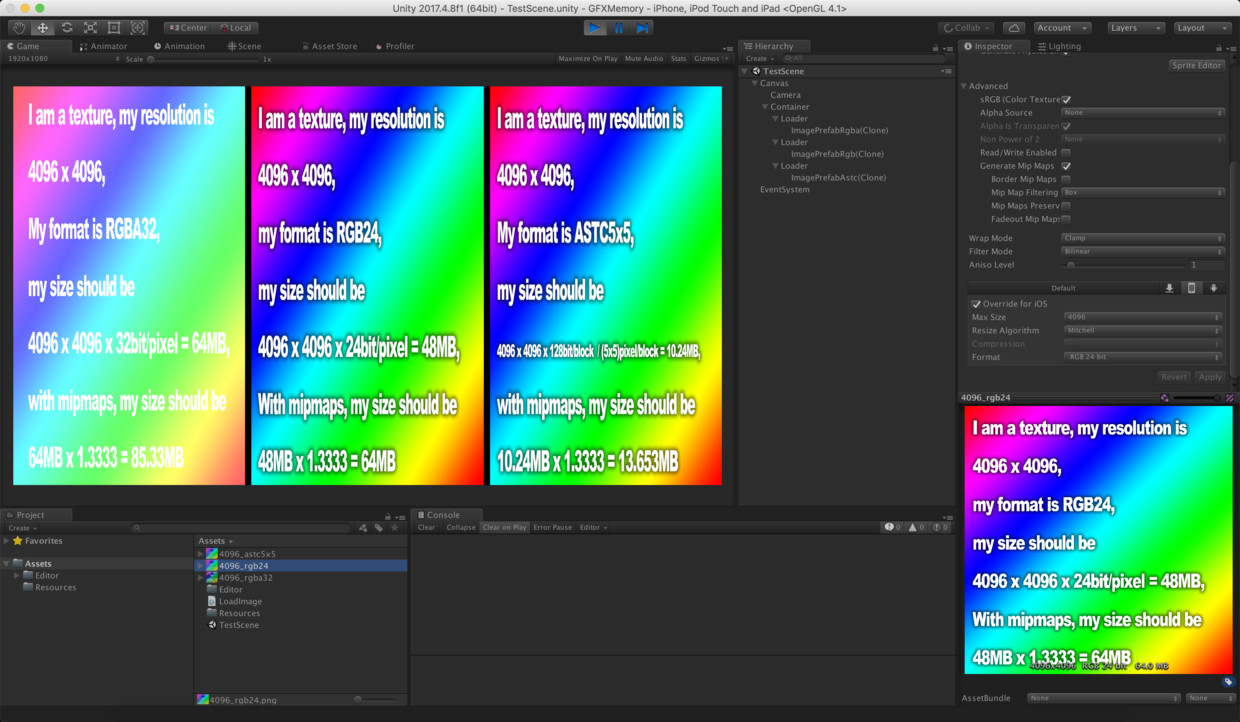
先创建一个名为GFXMemory的测试demo,分别有3张分辨率足够大的4096x4096的纹理贴图,格式分别设为RGBA32、RGB24、ASTC5x5,通过运行时点击对应的区域,才单独加载对应贴图,显示在屏幕中。
准备做Profile测试先查证以下问题:
由于3张纹理分辨率非常大且开启Mipmaps,其内存占用理应是期待纹理虚拟内存 = 85.33MB + 64.00MB + 13.65MB = 162.98MB,如果最终内存稳定后,本进程的虚拟内存占用约为进程内存 ~= 启动内存 + 已加载纹理内存,即可证实纹理虚拟内存占用的确只有一份,否则如果进程虚拟内存约为进程内存 ~= 启动内存 + 2*已加载纹理内存,即可证实主存、显存各持一份纹理贴图。
Unity版本为2017.4.8f1、XCode版本为10.1、运行设备为iPhone6s。
先用Unity以Development Build进行XCode工程导出,Development Build仅仅是为了能用Unity Memory Profiler进行Profile。
XCode中对Unity-iPhone工程进行Edit Scheme,并如下图开启Malloc Stack,是为了在命令行对memorygraph使用malloc_history命令查看内存创建的堆栈。
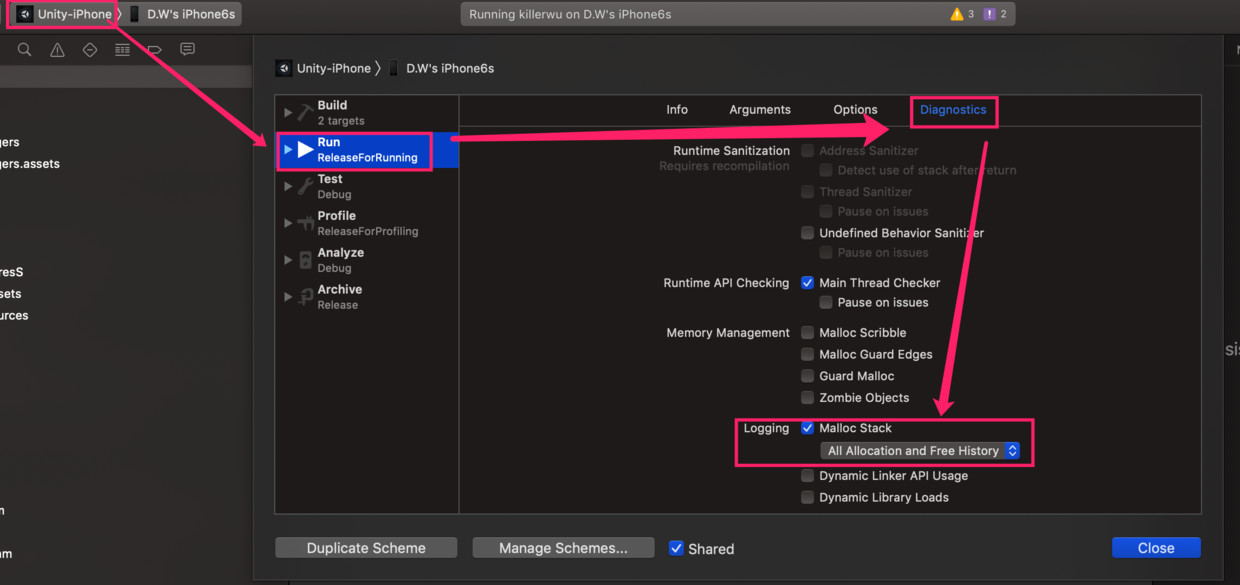
XCode中构建版本,USB连接iPhone6s并在其上运行,等待几秒钟待内存稳定后:
- 在XCode点击“Debug Memory Graph”,截取得出XCode的内存统计,并且Export为xcode_empty.memorygraph文件
点击UI加载上面3张纹理后,等待几秒钟待内存稳定后:
- 在Unity用Memory Profiler点击Take Snapshot,截取得出Unity的内存统计,并另存为unity.memsnap3文件
- 在XCode点击“Capture GPU Frame”,截取得到当前帧的GPU快照,并另存为xcode.gputrace文件
- 在XCode点击“Debug Memory Graph”,截取得出XCode的内存统计,并且Export为xcode.memorygraph文件
注意上述操作都确保游戏是一次运行针对同一进程的4次抓取结果,从而确保内存地址稳定。
我们在命令行执行命令vmmap --summary ./xcode_empty.memgraph,得到加载纹理前的虚拟内存占用约为111.3MB,如下图:
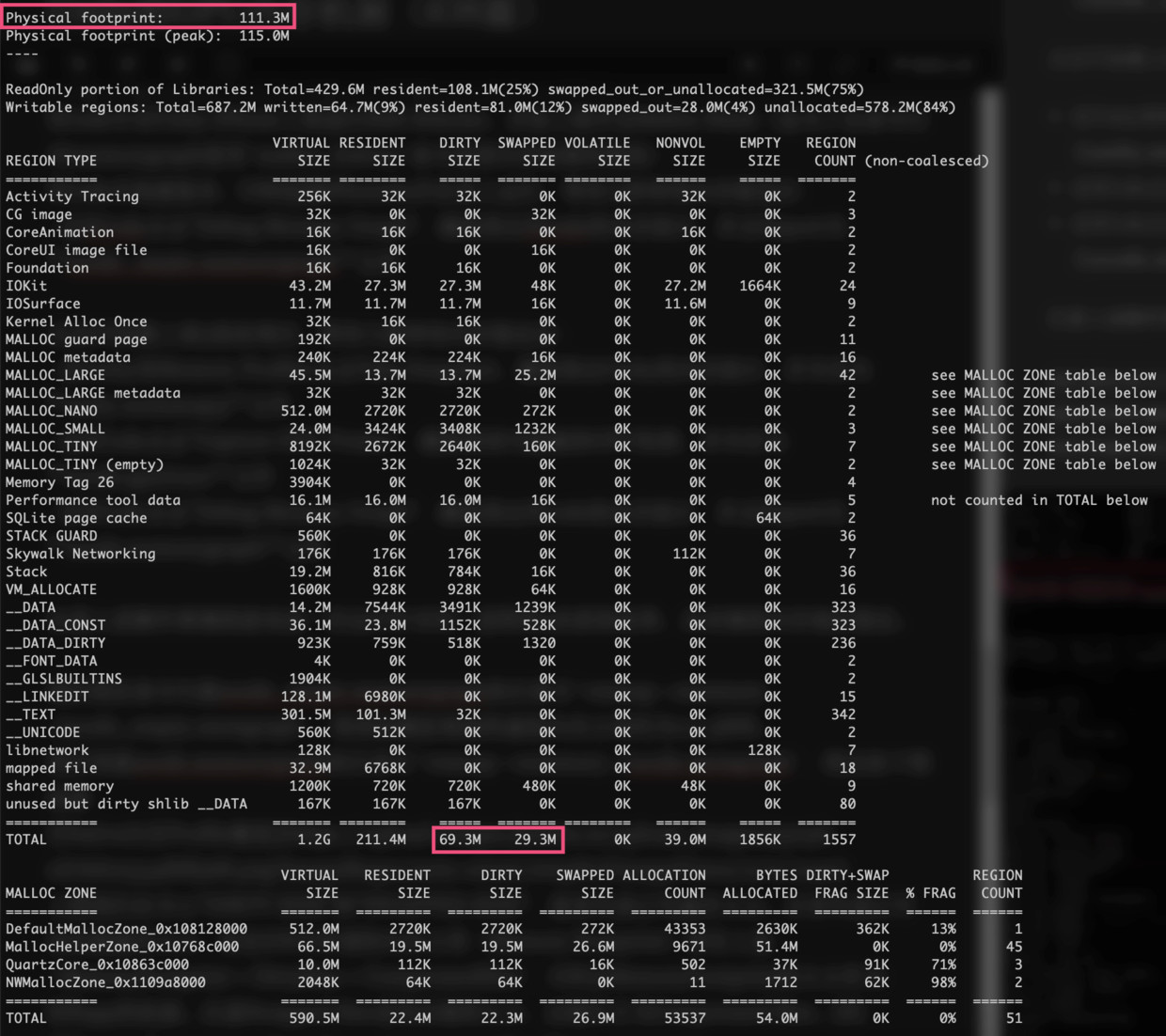
上图我们应关心“DIRTY SIZE”和“SWAPPED SIZE”,前者代表已写虚存大小、后者代表已写待压缩虚存大小。iOS和一般OS不一样,不采取虚存切页(Paging)的机制,而是采取压缩内存的机制。而在iOS中所谓的内存占用(Memory Footprint)事实上是MemoryFootprint = DirtySize + CompressedSize,iOS以MemoryFootprint的大小作为Killapp的依据。注意Swapped Size是待压缩的大小,压缩后方为Compressed Size。[8]

我们再执行命令vmmap --summary ./xcode.memgraph,得到加载纹理后的虚拟内存占用约为297.8MB,如下图:
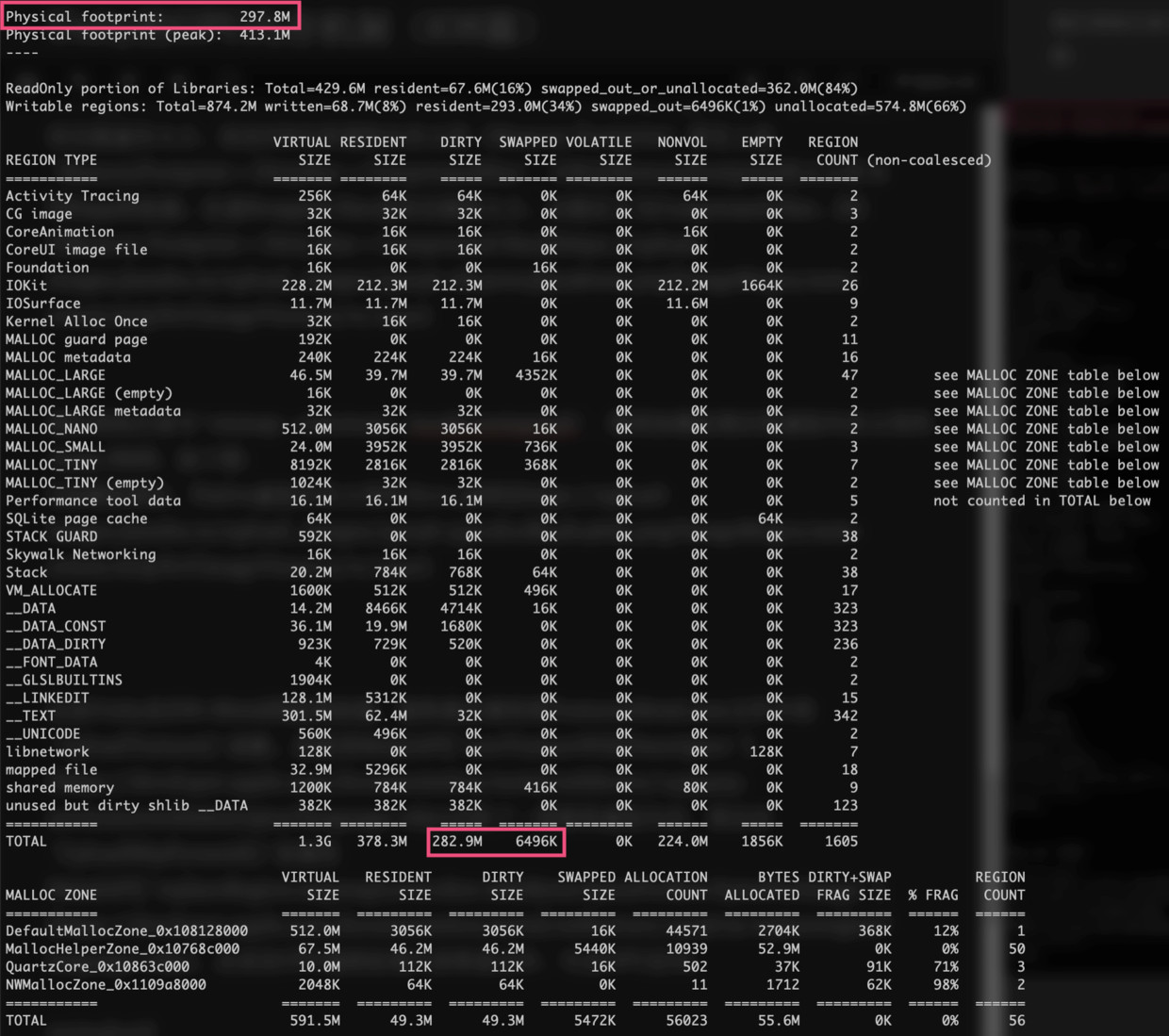
从而,加载纹理额外虚拟内存占用 = 297.9MB - 111.3MB = 186.6MB ~= 期待纹理虚拟内存占用162.98MB,而186.6MB << 325.96MB,从而几乎已经证实问题1,的确主存显存共享一份贴图虚拟内存。至于为何会多出186.6MB - 162.98MB ~= 23.62MB,我们会在后面证实到。
但仅仅从内存增幅来认定内存共享一份,显得还不够精确。
这时有个貌似合理的猜想:“如果GPU里用到的纹理虚拟内存地址,刚好等于MemoryGraph中对应的纹理虚拟地址,就说明它们必然是共享一份内存了”。
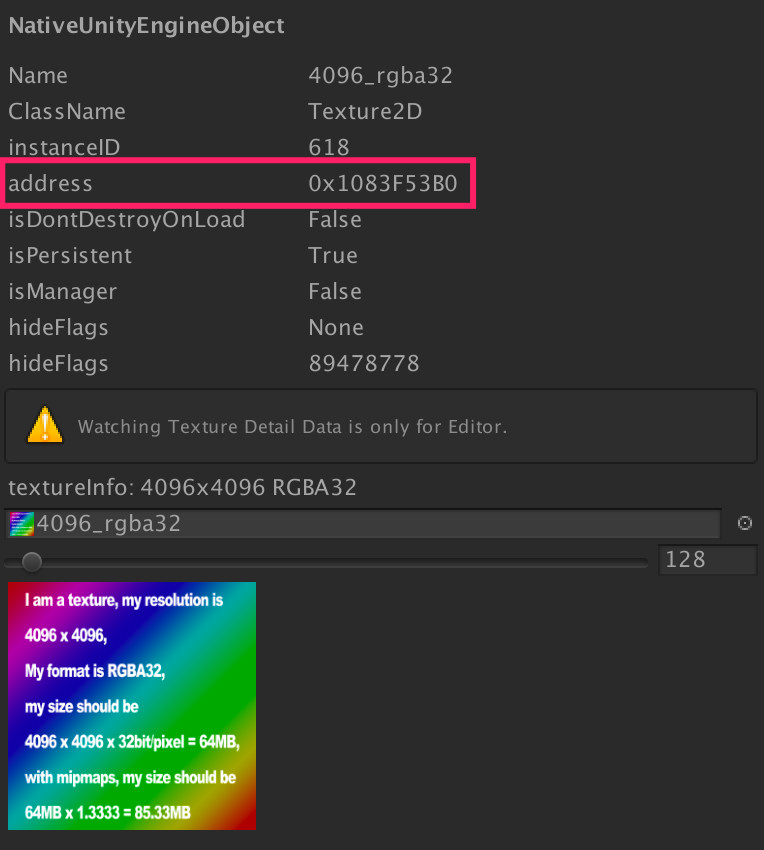
怀着这个想法,我们用XCode打开xcode.gputrace文件,搜索得出4096_rgba32的虚拟内存地址为0x1083f5b80,如下图:
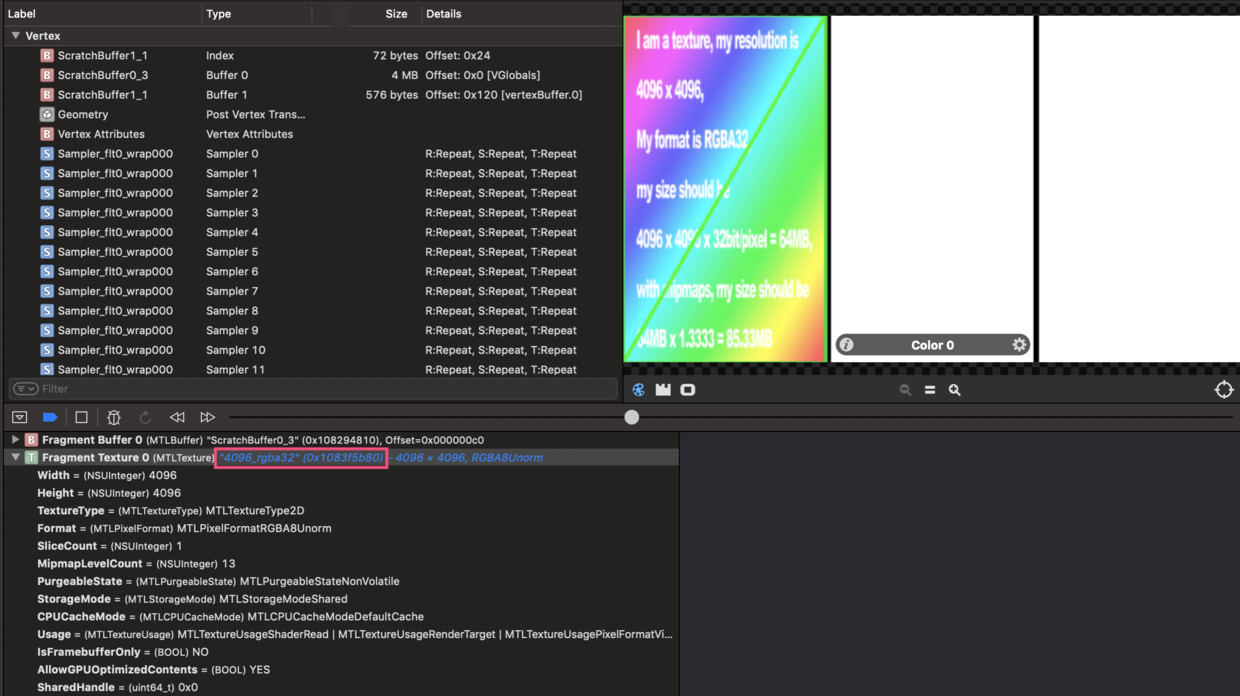
Unity Memory Profiler Editor本不支持显示对象的Native虚拟内存地址,简单修改其源码,让其在面板上显示Unity Native Object的虚拟内存地址,4096_rgba32纹理的虚拟内存地址为0x1083f53b0纹理,如下图:
“CPU/GPU访问的纹理地址不一样,这证实这张纹理不是CPU/GPU共享的!”但可惜,不能因此得出这个结论。
我们控制台针对GPUTrace的地址使用命令malloc_history ./xcode.memgraph -fullStacks 0x1083f5b80,有下图输出:
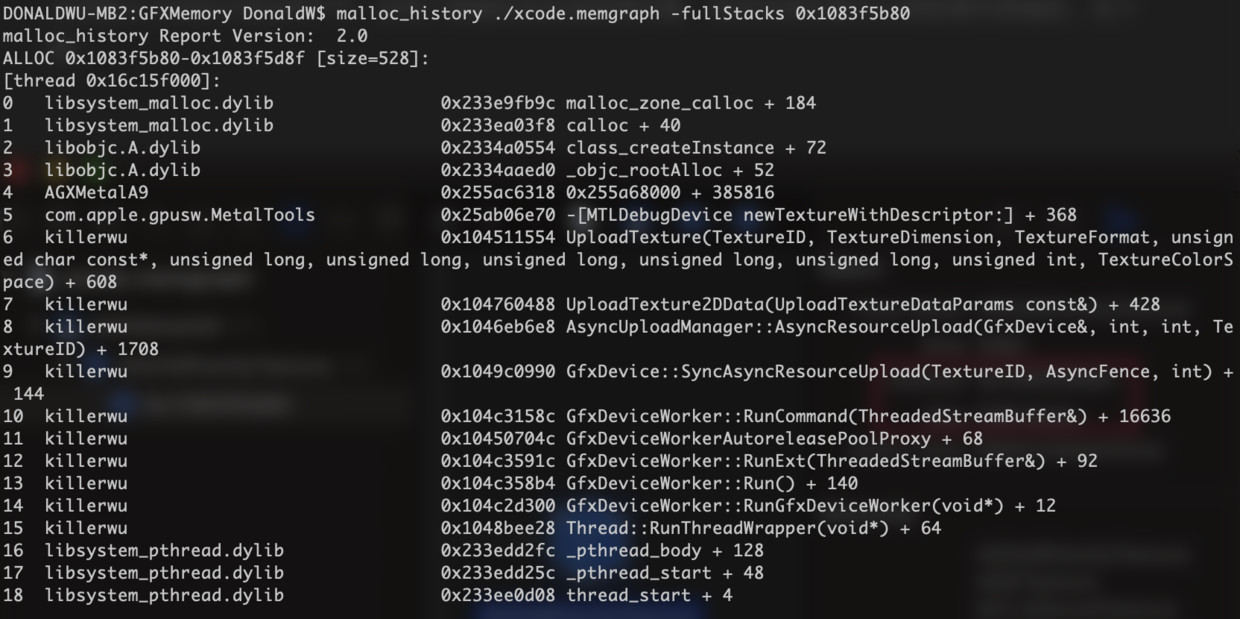
针对Unity Memory Profiler的地址使用命令malloc_history ./xcode.memgraph -fullStacks 0x1083f53b0,有下图输出:
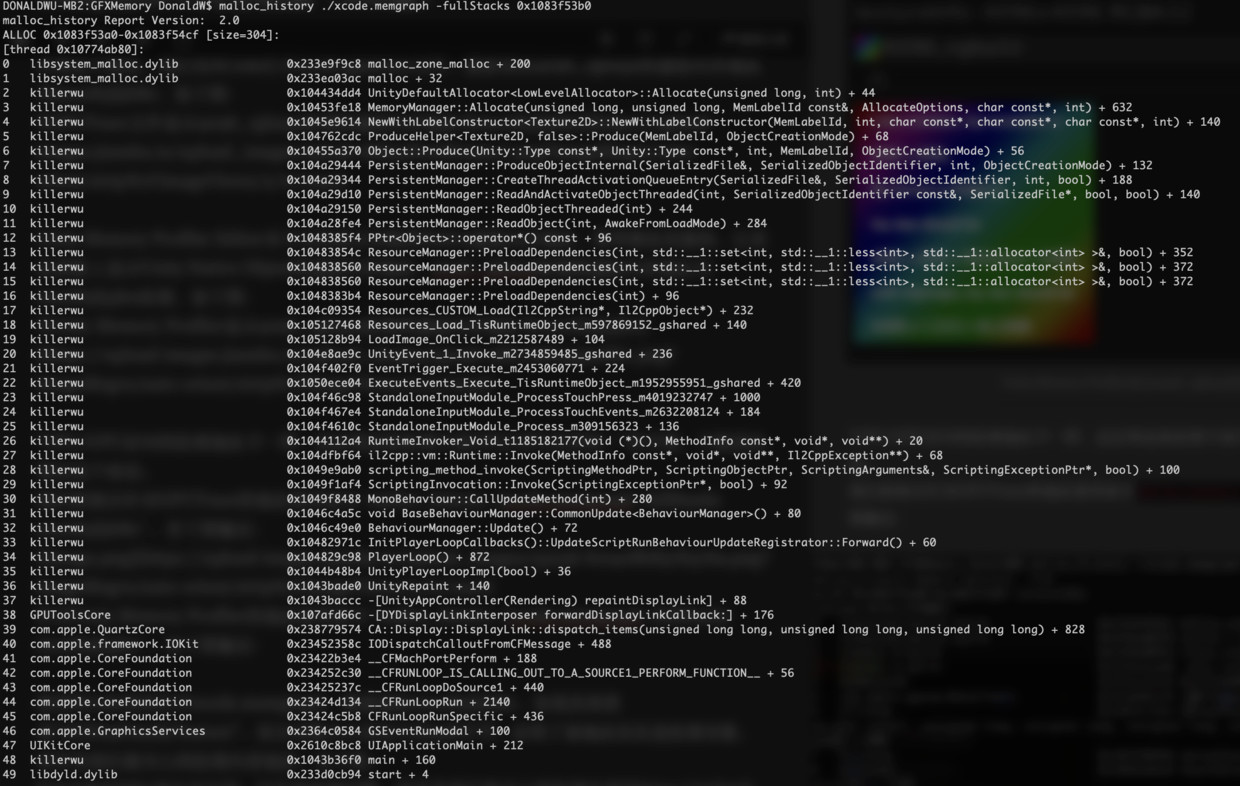
使用XCode再次打开xcode.memgraph,搜索地址0x1083f5b80,发现其类型是“AGXA9FamilyTexture”,而且对象大小仅仅只有528字节,见下图:
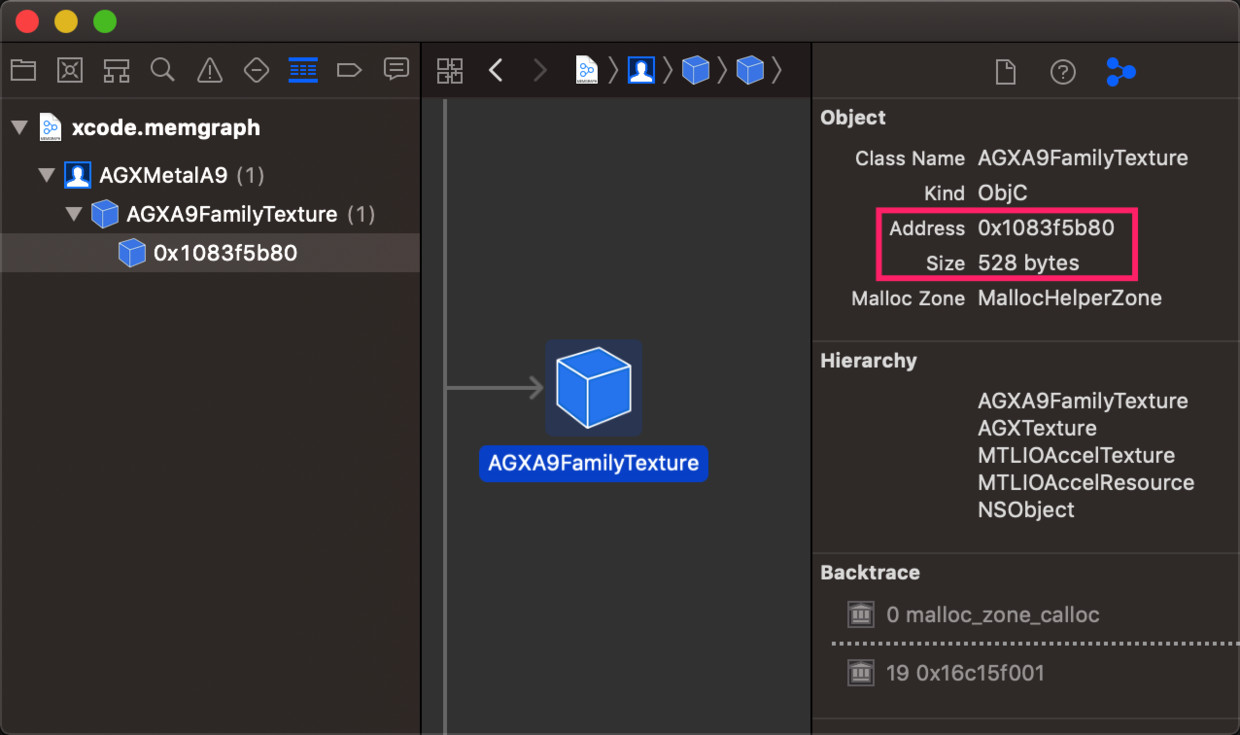
上面3图,证实了上面的地址仅仅是纹理对象,而并非我们最关心的纹理内容地址。比如AGXA9FamilyTexture是Metal的纹理对象,Texture2D是Unity的纹理对象,纹理对象内部有指针指向了纹理内容。
如果我们不修改Unity源码,我们无法得知Texture2D中纹理内容的地址。如何得知纹理内容到底在哪呢?
留意上面vmmap --summary命令显示加载纹理前后的内存占用,增幅最大的内存区域(Region)是“IOKit”,我们不妨看看里面到底是啥,通过vmmap --verbose ./xcode.memgraph | grep "IOKit",有以下结果:

上面非常像我们3张纹理贴图内容的内存占用大小(下面才解释为什么64.0MB变为85.3MB),而左边就是它们的虚拟内存地址。
我们尝试用malloc_history ./xcode.memgraph --fullStacks “上述3个地址”,发现都不能打印出分配它们的栈,说明它们并非使用传统malloc在堆(Heap)上分配,如下图。事实上IOKit是iOS的驱动框架,该区域内存是驱动相关的虚拟内存区域,通过额外的实验可以知道,Metal最重要的MTLBuffer分配,不管Dirty与否,都是在IOKit这个驱动区域进行内存分配。
但是!当我们在XCode打开xcode.memgraph后,如下图,搜索地址“0x11c3e0000”得出该85.3MB的IOKit内存,而引用它的,恰好就是我们上面发现的地址为0x1083f5b80的Metal的纹理对象!
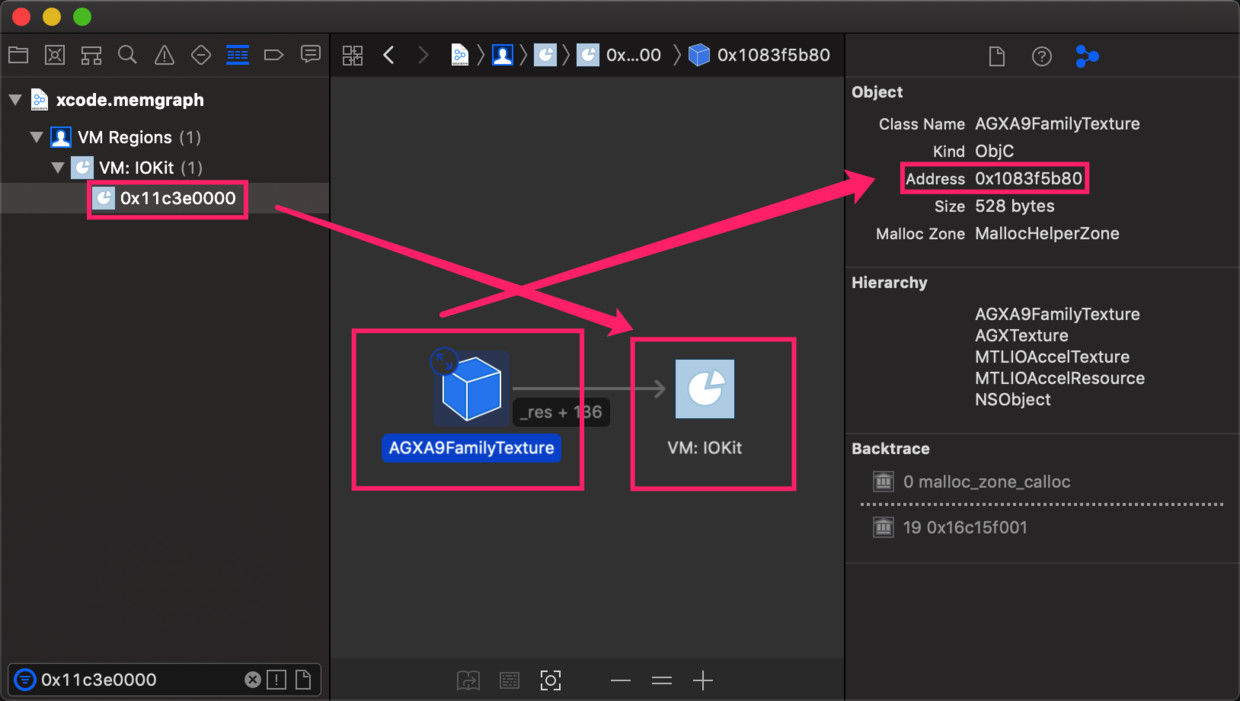
至此,我们通过硬件分析、图形API分析和虚拟内存Profile分析,比较折腾,终于得出以下结论:
iOS设备中只有一块物理内存硬件。
主存地址和显存地址在同一个地址空间(Address Space)中,即虚存地址空间(Virtual Address Space)。
虚拟内存中的确只有一份纹理内容,而且该纹理内容的确就是被GPU所用的纹理。
我们接着讨论问题2。由于问题2需要回答的是贴图内存走向,不能通过分析某一时刻的虚拟内存得出结论,而要使用带有Timeline的Profiler,这里使用Instruments。
我们进行3种Profiler:Timer Profiler以观察CPU耗时情况及捕捉函数调用栈,Allocations以观察堆内存分配释放情况,VM Tracker以观察所有虚拟内存的分配释放情况。
针对Time Profiler,我们可以打开其High Frequency选项,以采样到更精细的函数调用栈。
Profile结果如下图。其中3个红框左到右分别表示加载RGBA32、RGB24、ASTC5x5时的情况。
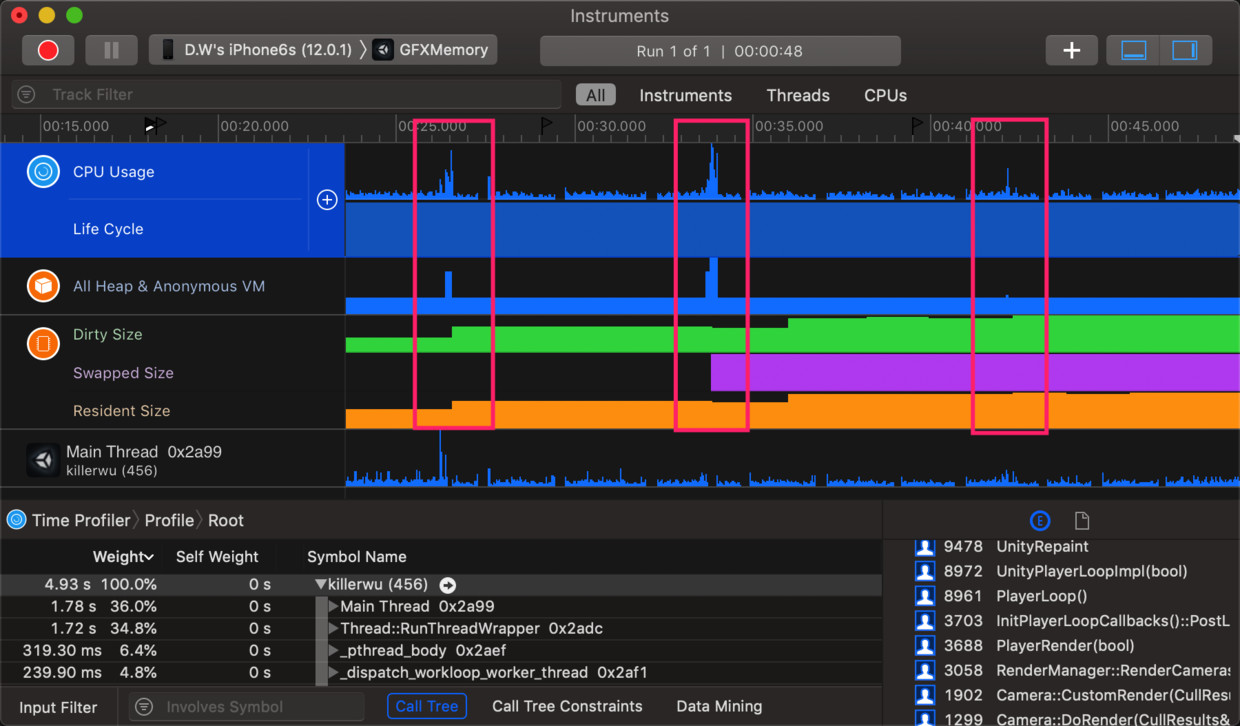
大致观察上图可以发现:
CPU消耗尖刺(Spike):RGB24 > RGBA32 >> ASTC5x5
堆内存消耗尖刺:RGB24 > RGB32 >> ASTC5x5
虚拟内存消耗则整体呈现持续增长
我们先看最左边RGBA32的CPU消耗情况,如下两图,分别为加载RGB24纹理时CPU消耗Spike的前期和后期。
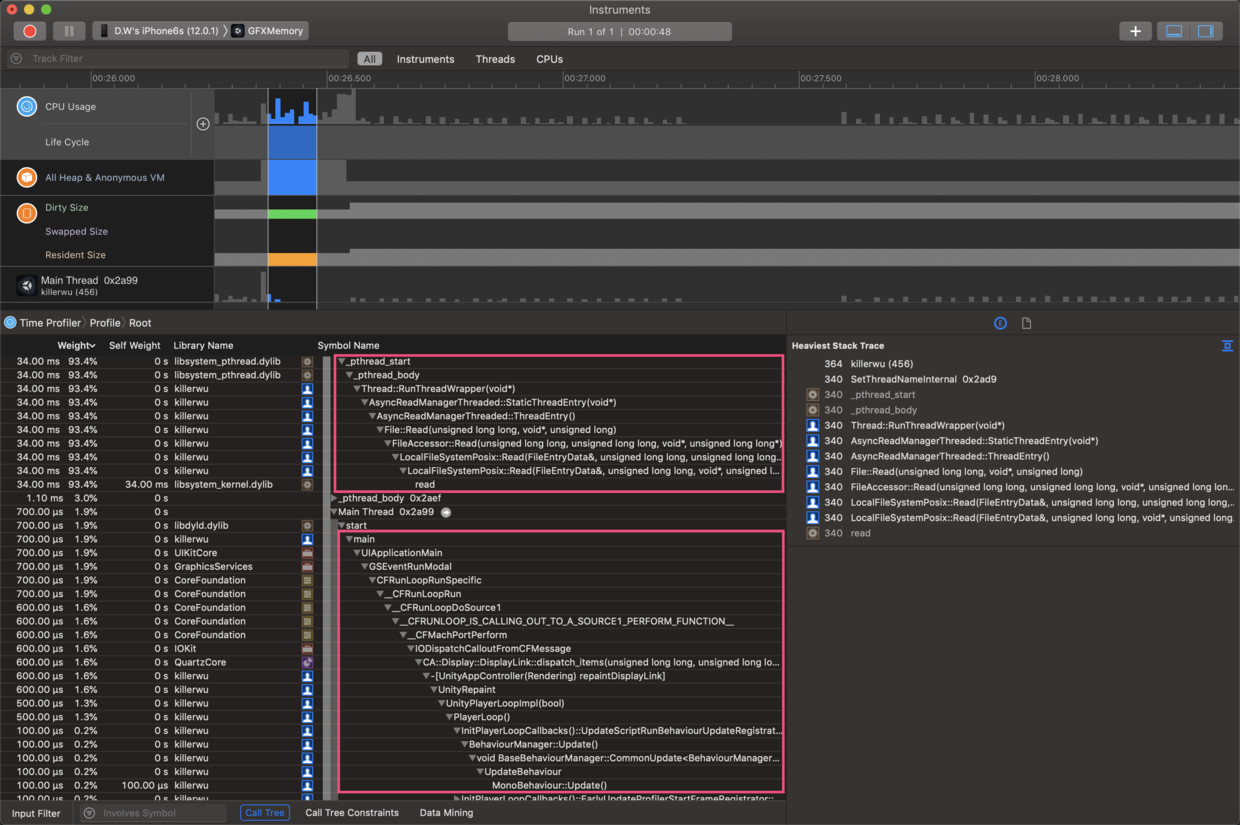
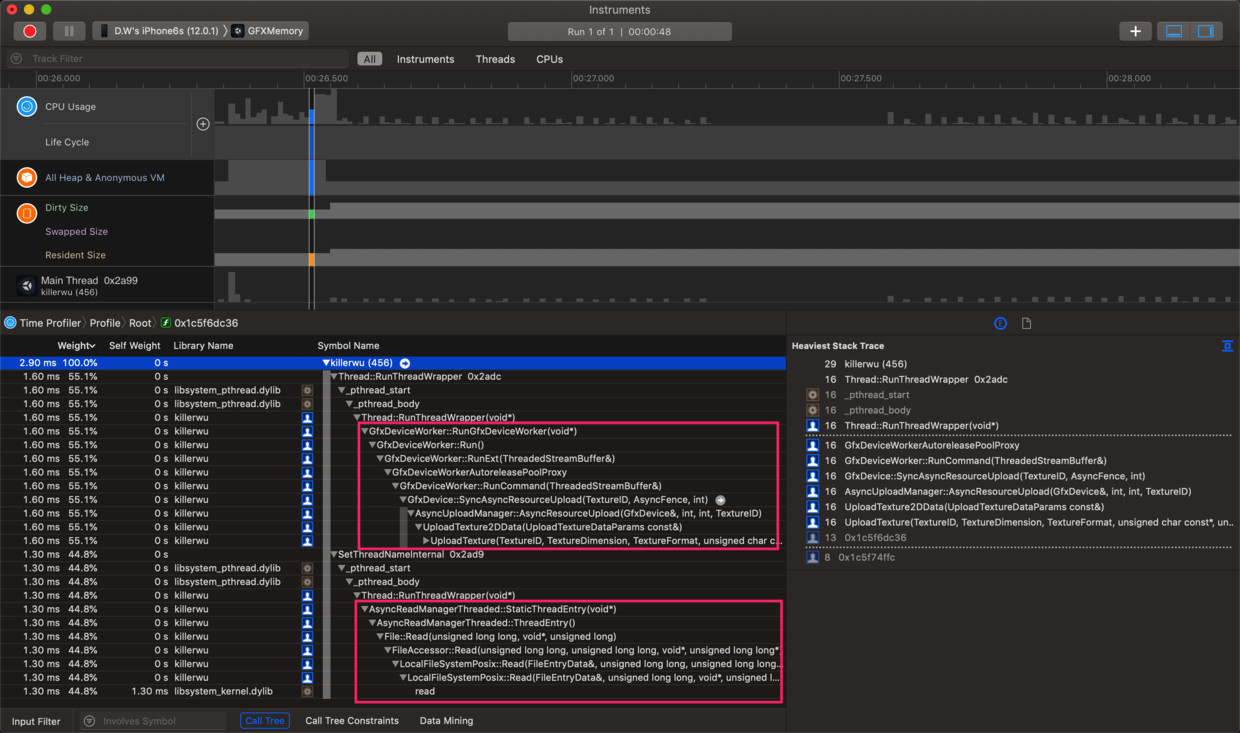
不需无头绪地辛苦阅读海量引擎代码,有的放矢,立刻可精确看出Unity在加载纹理时主要工作分两部分:文件加载(File::Read())和纹理上传(UploadTexture2DData())。
而且发现将时间线在前后期中间不管如何细分,都只出现了上面2个主要消耗,说明了只有这两个工作线程在工作,我们只需分析它们相信已足够找出纹理加载的流程。我们也发现在整个纹理加载过程中,主线程只有非常少的Update空转占用,证实纹理加载几乎是脱离主线程工作的。
文件加载函数栈看起来比较通用,先从纹理上传的函数栈看起应该会更快解决问题。
阅读源码,发现其关键流程如下:
AsyncUploadManager.cpp中,AsyncUploadManager.AsyncResourceUpload()从m_UploadQueue不断Dequeue出FileAssetUploadInstruction类型的对象ftuInstr,其非常重要,描述了这次纹理上传的所有关键数据。根据纹理类型,调用了2D纹理函数static Upload2DTexture()。
AsyncUploadManager.cpp中,static Upload2DTexture()将ftuInstr->buffer直接赋值给UInt8* uploadBuffer,至此,首次显式出现了纹理内容的指针,可以看出,非常关键的问题是,到底FileAssetUploadInstruction::buffer是从哪来的?但先不急,先把这个栈看完。接着把uploadBuffer和ftuInstr里几乎所有关于纹理的数据,传递给Texture.cpp的static UploadTexture2DData()。
Texture.cpp文件中,static UploadTexture2DData()调用gfxDevice.UploadTexture2D(),通知GfxDeviceMetal进行纹理上传。
TextureMetal.mm文件中,static UploadTexture()通过[MTLDevice newTextureWithDescriptor]创建Metal的纹理对象,指定了纹理分辨率、格式、mipmap层数等,并且在IOKit区域里已为该对象分配了用于存放纹理内容的内存区域。
TextureMetal.mm文件中,static UploadMipPyramid()为各个mipmap层算出分辨率,最终调用了Metal API[MTLTexture replaceRegion],将对应的纹理数据最终拷贝到了MTLTexture对象中。注本接口名叫“替换replace”,事实上是进行了纹理内容数据进行了“拷贝copy”操作。
通过以上比较啰嗦的分析,可以看出就算是在Metal进行纹理上传,也难免有纹理内容拷贝的过程。用[MTLDevice newTextureWithDescriptor]创建纹理对象及其指向的纹理内容空间,把FileAssetUploadInstruction的buffer数据,加以一定处理(Crunch、纹理格式转换等),最终通过[MTLTexture replaceRegion]将纹理内容数据拷贝到了驱动虚拟内存IOKit区域里。
那到底这个buffer数据到底从哪来的?当然,从上文和类名包含“File”,已经可以猜出是从外存读取得来,但不精确证实不服气,我们将注意力回到上面的文件加载调用栈。堆栈协助代码阅读,发现很简单:
在AsyncReadManagerThreaded.cpp里,
AsyncReadManagerThreaded::ThreadEntry()不断从m_Requests里拿出AsyncReadCommand类型的实例command,
并且打开纹理文件对象指针:File* file = m_OpenFilesCache.OpenCached(command->fileName);
将file的内容,全都读取到command->buffer里:bool readOk = file->Read(command->offset, command->buffer, command->size) == command->size;,说明command->buffer指向的内存已经分配好了内存以供纹理文件读入。
那么command->buffer的内存哪里分配而来呢?
由于内存分配的CPU消耗可能很小,就算是高精度的Sampler也可能在Time Profiler里找不到,这里我们明显要求救于Allocation,如下图,我们选择“Call Trees”分类,框选在加载纹理时,内存飙升时的时段,发现132.03MB内存是在AsyncUploadManager::ManageTextureUploadRingBufferMemory()中分配给m_DataRingBuffer。
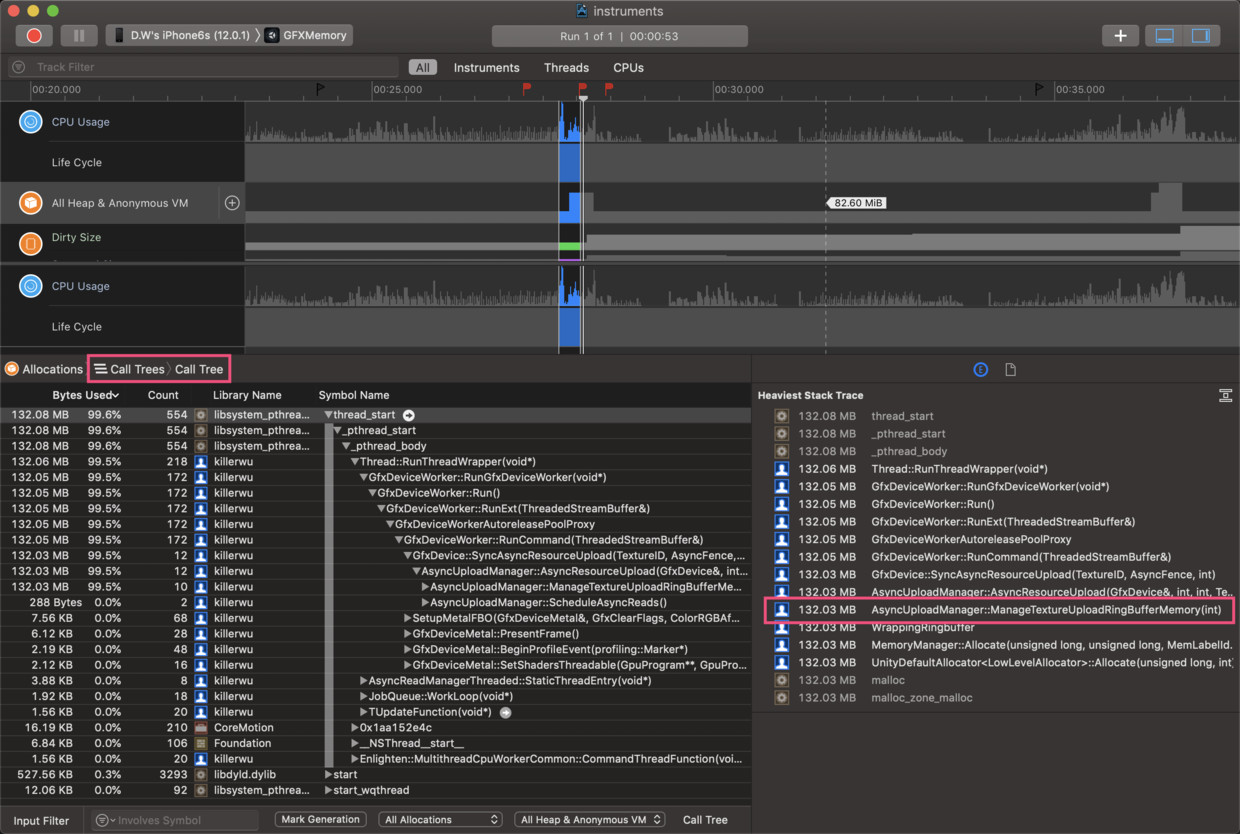
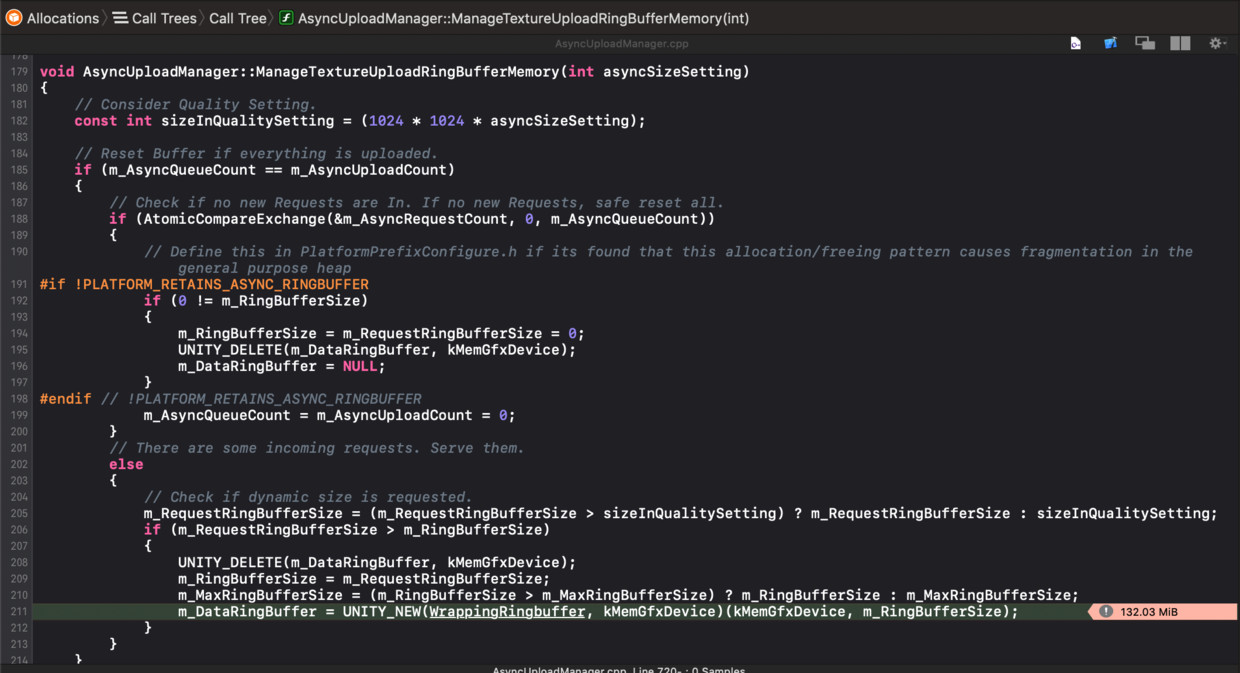
通过以上种种分析,已经掌握了不少信息和关键字,找出答案已是临门一脚了:
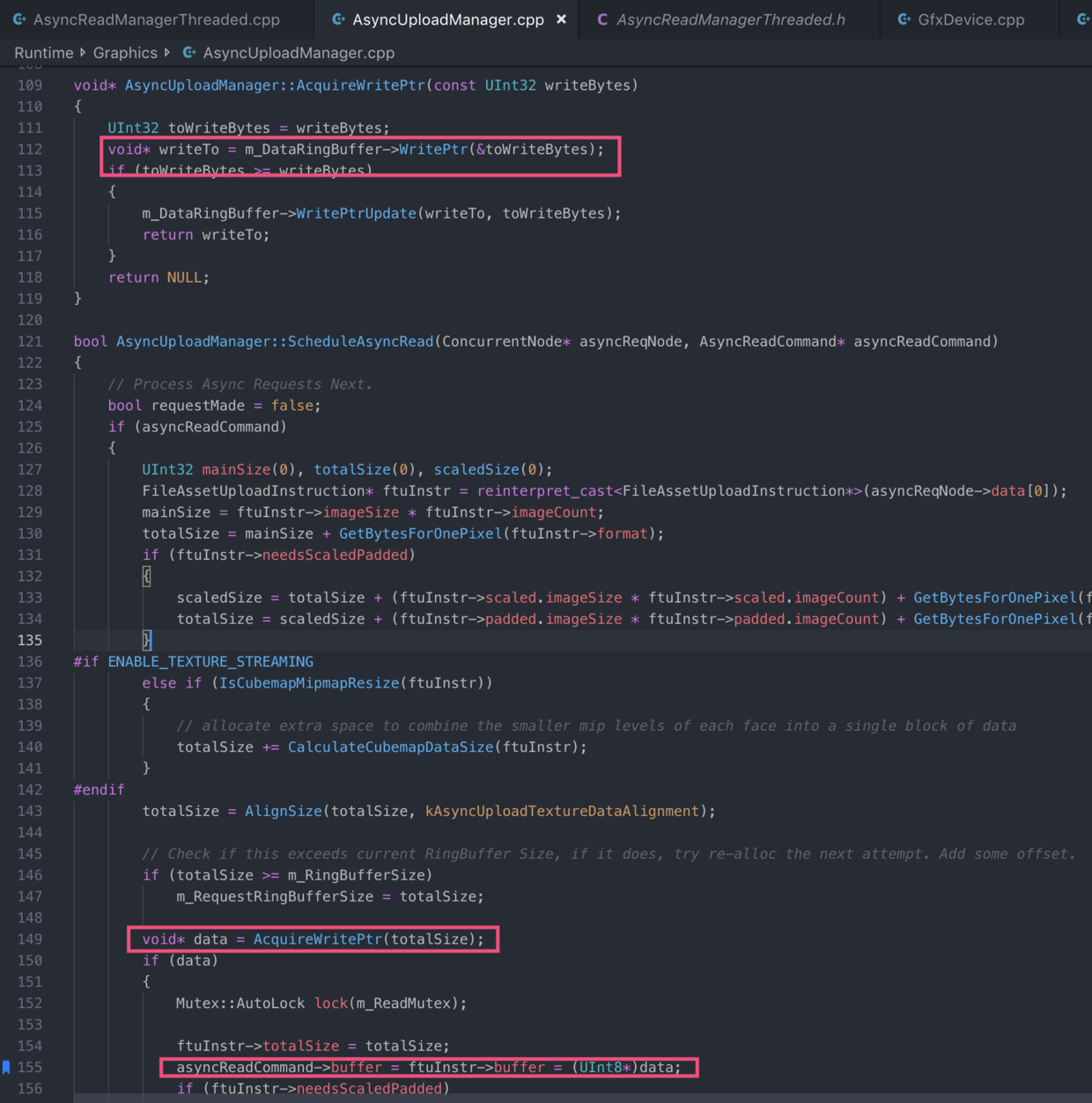
AsyncUploadManager::ScheduleAsyncRead()从m_DataRingBuffer申请纹理内容大小的内存空间,同时将指针赋值给asyncReadCommand->buffer和ftuInstr->buffer,从而文件读取线程将纹理文件内容写到asyncReadCommand->buffer指向的堆内存,渲染线程在通过ftuInstr->buffer将纹理内容从同一堆内存获取到。
至此,回答了问题2。
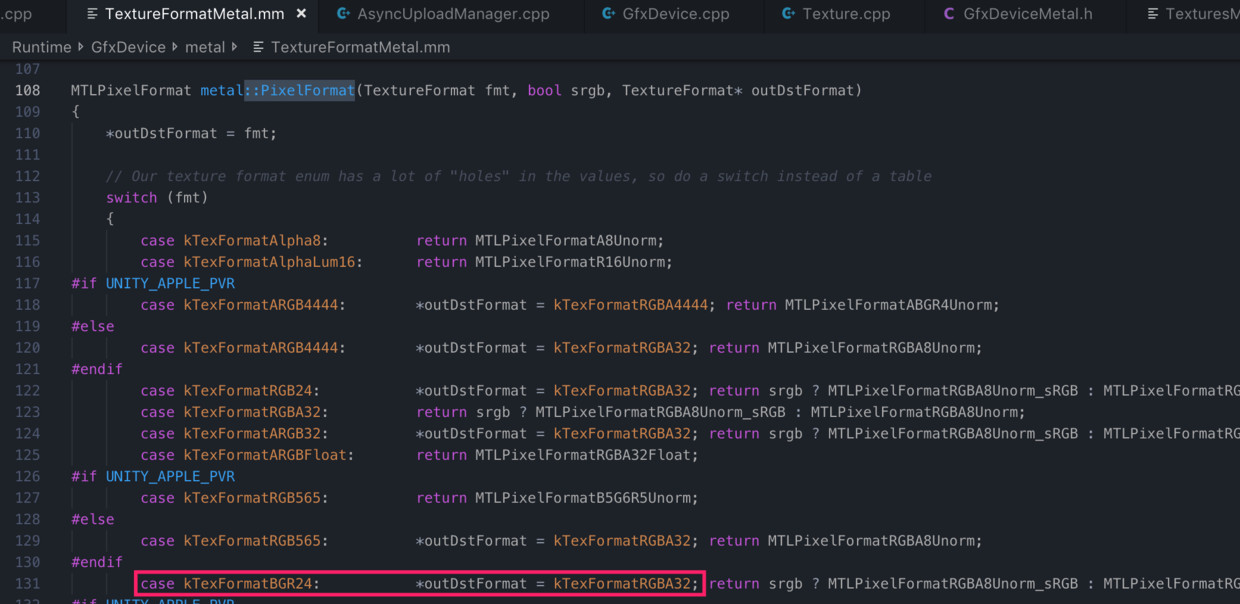
最后的最后,上面提到的RGB24纹理的特殊情况,为什么其虚拟内存占用大小不是64MB,而是和RGBA32一样,都是85.3MB?结合上面已知流程,分析可知,原因是Metal并不支持RGB24,在运行时都会转为RGBA32,如下:
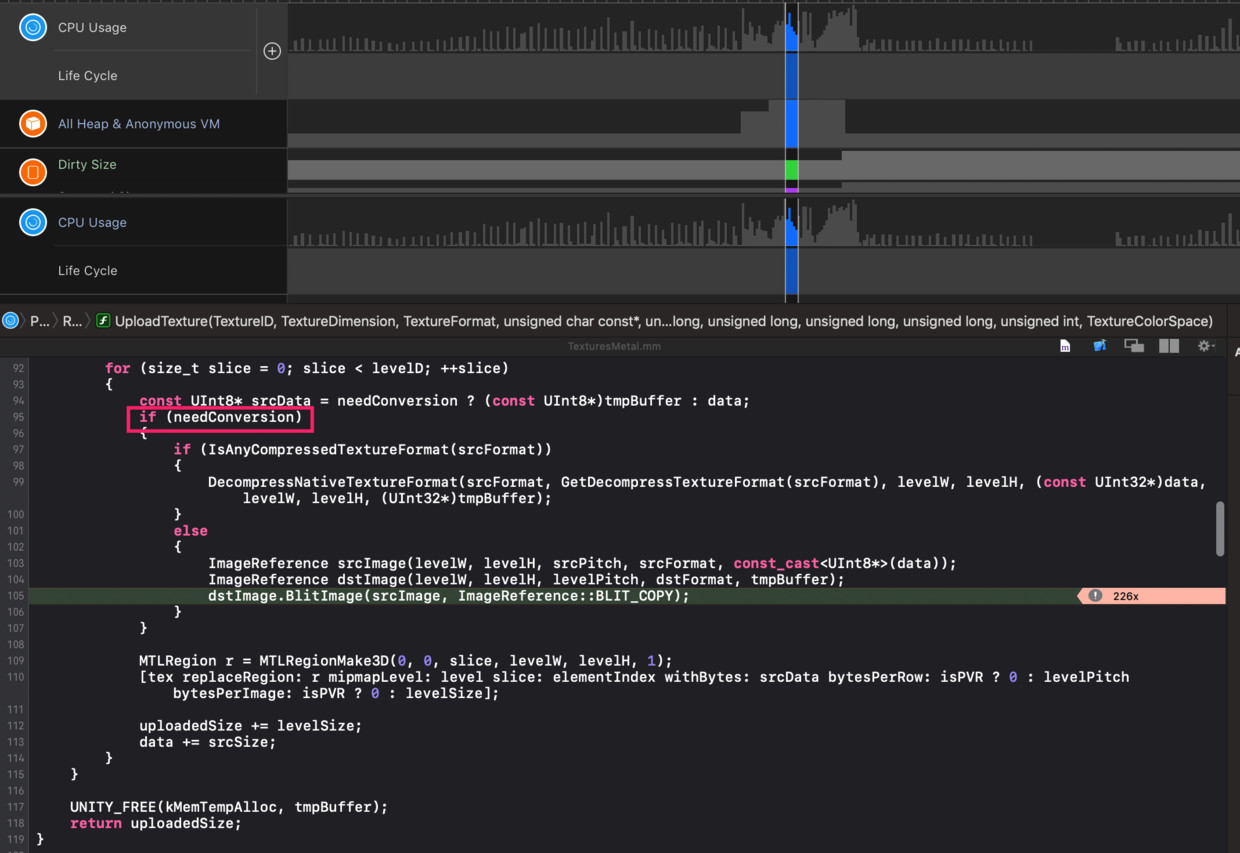
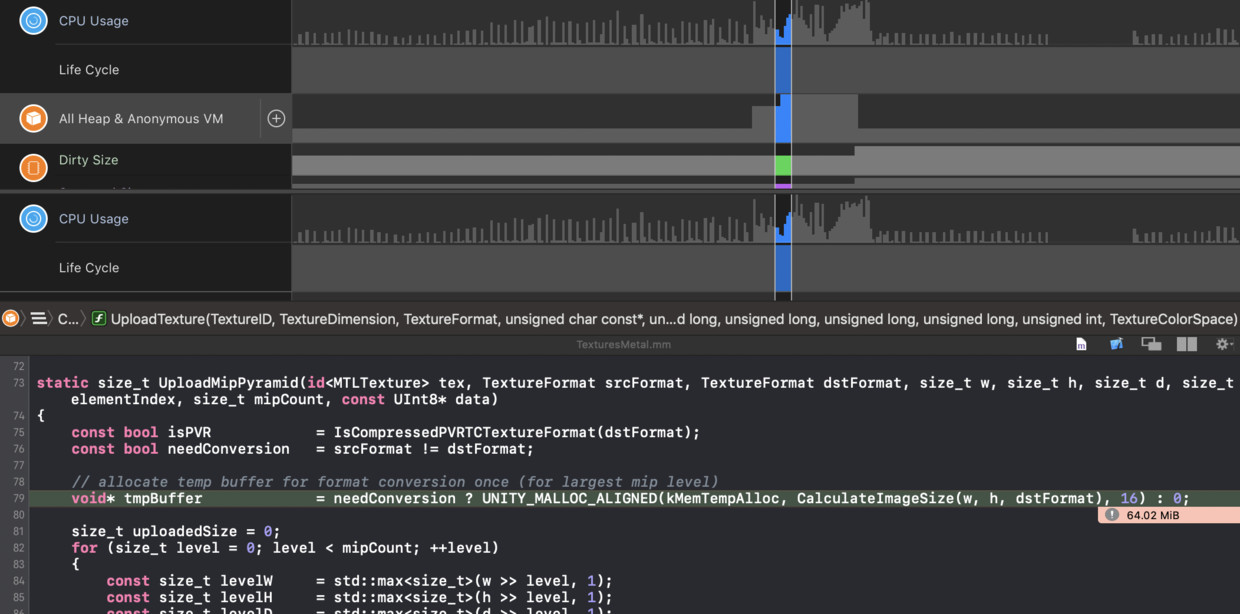
这能从以下Time Profiler以及Allocation栈轻易证实:
2.4 结论
通过Profile结果和源码,我们证实了:iOS设备中只有一块物理内存硬件,主存地址和显存地址在同一块虚存地址空间中,虚存最终的确只有一份纹理内容位于IOKit区域中,而且该纹理内容的确就是被GPU所用的纹理。
在纹理上传过程中,Unity先在堆内存申请缓存,然后将纹理文件内容读进缓存里,然后调用图形API将该该纹理内容数据拷贝到IOKit虚存中,供GPU访问。拷贝完成后缓存视乎情况从堆内存释放。
过程中,我们展示了在iOS中各种Profile工具的实际使用方法。
也介绍了一些基础的内存知识和概念。
引用
[1]ifixit - iPhone 6 Teardown
[2]Chipworks Disassembles Apple’s A8 SoC
[3]Metal_(API)#Supported_GPUs#Supported_GPUs)
[4]Metal Best Practices Guide - Resource Options
[5]Metal - Resource Storage Mode
[6]MTLBuffer
[7]Triple Buffering
[8]iOS Memory Deep Dive
[9]Choosing a Resource Storage Mode in iOS and tvOS
[10]MTLBuffer makeTexture
关于腾讯游戏学院专家团
如果你的游戏也富有想法充满创意,如果你的团队现在也遇到了一些开发瓶颈,那么欢迎你来联系我们。腾讯游戏学院聚集了腾讯及行业内策划、美术、程序等领域的游戏专家,我们将为全世界的创意游戏团队提供专业的技术指导和游戏调优建议,解决团队在开发过程中遇到的一系列问题。
项目指导合作请联系微信:18698874612
本文转自:腾讯GWB游戏无界,转载此文目的在于传递更多信息,版权归原作者所有。





