来源:开源中国
从语言结构化理论基础,到 1750 亿参数的 GPT-3。一部 NLP 的百年发展史。
语言的结构化
20 世纪初,在瑞士的日内瓦大学,一位名叫费迪南德·德·索绪尔( Ferdinand de Saussure) 的语言学教授发明了一种将语言描述为“系统”的方法。

索绪尔教授认为,意义是在语言内部、语言各部分之间的关系和差异中创造的,“在词里,重要的不是声音本身,而是使这个词区别于其他一切词的声音上的区别,因为带有意义的也正是这些差别。" 他提出,“意义”产生于语言之间的关系和对比,而共享语言系统则使交流成为可能。
索绪尔将社会视为一个“共享”的规范体系,为合理的、可扩展的思想提供了条件,从而导致个人产生不同的决定和行动。
遗憾的是,索绪尔教授的理论还未发表,就于 1913 年去世。而他的两个学生阿尔伯特·薛施霭(Albert Sechehaye)和沙尔·巴利(Charles Bally)意识到了这项研究的重要性,收集了教授生前留下的手稿以及其他同学的笔记,编辑整理出了《通用语言学》一书,并于 1916 年出版。
该书奠定了后来的基础结构主义的方法论,成为现代语言学以及结构主义语言学的开山之作,索绪尔教授也因此被后人称为现代语言学之父。而他留下的结构化理论,对语言学以外的领域同样影响深远,也为几十年后出现的结构化编程语言与人工智能技术打下了理论基础。
人工智能的兴起
1950 年,计算机科学之父阿兰·图灵(Alan Turing)发表了一篇划时代的论文,文中预言了创造出具有真正智能的机器的可能性。
由于注意到“智能”这一概念难以确切定义,他提出了著名的 “图灵测试”:如果一台机器能够与人类展开对话(通过电传设备),且不能被参与测试的 30% 以上的人类裁判辨别出其机器身份,那么则称这台机器具有人类智能。
紧接着在 1952 年,生物学家阿兰·霍奇金(Alan Hodgkin)和安德鲁·赫克斯利(Andrew Huxley)开发了一个数学模型来解释章鱼巨型轴突中神经细胞的行为,霍奇金-赫克斯利模型展示了人类的大脑如何利用神经元形成网络,首次将人类大脑的工作原理具象化地展示在世人面前。
这一系列颠覆性的研究成果在学术界引发轰动,激发了人工智能(AI)的思潮,同时也催生了自然语言处理(NLP)和计算机技术的发展。
NLP 的早期理论基础
人们最早对 NLP 的探索始于对机器翻译的研究。1947年,美国科学家韦弗(W. Weaver)博士和英国工程师布斯(A. D. Booth)提出了利用计算机进行语言自动翻译的设想,机器翻译(Machine Translation)从此步入历史舞台。
1957 年,麻省理工学院的语言学教授诺姆·乔姆斯基(Noam Chomsky)在他出版的《句法结构》一书中,革新了语言的概念,提出 “要使计算机理解语言,就必须更改句子的结构。”
以此为目标,乔姆斯基创建了一种语法,称为“阶段结构语法”,该语法能够有条不紊地将自然语言句子翻译为计算机可以使用的格式。
1958 年夏天,同样来自麻省理工学院的人工智能研究先驱约翰·麦卡锡(John McCarthy)参与 IBM 资讯研究部的工作,研究符号运算及应用需求。但 IBM 旗下的 Fortran 表处理语言却未能支持符号运算的递归、条件表达式、动态存储分配及隐式回收等功能。
于是麦卡锡带领由 MIT 学生组成的团队开发了一门全新的表处理语言 LISP,赋予了编程语言更强的数学计算能力。LISP 语言后来也被称为人工智能的“母语”,成为早期人工智能研究人员的编程语言。
1964 年,首个自然语言对话程序 ELIZA 诞生,该程序是由麻省理工学院人工智能实验室的德裔计算机科学家约瑟夫·维岑鲍姆 (Joseph Weizenbaum)使用一种名为 MAD-SLIP 的类 LISP 语言编写,运行在 MIT 实验室中 36 位的分时系统 IBM 7094 (早期的晶体管大型计算机)上。
由于当时的计算能力有限,ELIZA 只是通过重新排列句子并遵循相对简单的语法规则来实现与人类的简单交流。
用户通过电动打字机和打印机与程序进行远程交互,当用户键入一个句子并按 Enter 键时,消息被发送到服务端系统,ELIZA 扫描邮件中是否存在关键字,并在新句子中使用该关键字以形成响应,返回打印给用户。
这种对话方式,给人的印象是计算机可以理解对话,又不必为对话提供任何新内容,仅用 200 行代码就产生了理解和参与的错觉。

在这一时期,虽然有了一定的理论基础以及像 Eliza 这样的初级产品,但在历时近 12 年并耗资近 2000 万美元后,机器翻译的成本还是远高于人工翻译,并且仍然没有任何计算机能够真正实现基本的对话。
于是在 1966 年,美国国家研究委员会(NRC)和自动语言处理咨询委员会(ALPAC)停止了对自然语言处理和机器翻译相关项目的资金支持, AI 和 NLP 的发展因此陷入停滞。
此时,许多学者认为人工智能和自然语言处理的研究进入了死胡同。人类早期结合语言学与统计学对 AI/NLP 的初步探索以失败告终。
NLP 的回归
直到 1980 年,在美国的卡内基梅隆大学召开了第一届机器学习国际研讨会,标志着机器学习研究在全世界的重新兴起。
在某种程度上来说,长达 14 年的真空期也让 NLP 界有时间冷静下来寻求新的突破。于是,早期的机器翻译概念被推翻,新的思想促进了新的研究。
早期的自然语言处理研究中,很流行语言学和统计学的混合,大多数 NLP 系统都使用复杂的“手写”逻辑规则。而现在,这一理念被纯粹的统计学所取代。
20 世纪 80 年代,得益于计算能力的稳定增长以及机器学习的发展,研究人员开始对 AI 和 NLP 进行根本性的重新定位,用简单的近似法取代了深入的分析法,评估过程也变得更加量化。
经过一些挫折后,一种前馈神经网络模型 MLP 由伟博斯在 1981 年的神经网络反向传播(BP)算法中具体提出。当然 BP 仍然是今天神经网络架构的关键因素。
有了这些新思想,神经网络的研究又加快了。1985 -1986 年,一些神经网络研究学者先后提出了 MLP 与 BP 训练相结合的理念。
随后,一个非常著名的 ML 算法由罗斯·昆兰(Ross Quinlan) 在 1986 年提出,我们称之为决策树算法,更准确的说是 ID3 算法。这是另一个主流机器学习的重要里程碑。
与黑盒神经网络模型截然不同的是,决策树 ID3 算法也被作为一个软件,通过使用简单的规则和清晰的参考可以找到更多的现实生活中的使用情况。
决策树是一个预测模型,他代表的是对象属性与对象值之间的一种映射关系。树中每个节点表示某个对象,而每个分叉路径则代表的某个可能的属性值,而每个叶结点则对应从根节点到该叶节点所经历的路径所表示的对象的值。
决策树仅有单一输出,若欲有复数输出,可以建立独立的决策树以处理不同输出。中决策树是一种经常要用到的技术,可以用于分析数据,同样也可以用来作预测。
在 90 年代,随着互联网的出现,用于自然语言过程分析的统计模型迅速普及。纯粹的统计学 NLP 方法在线上文本的巨大流量方面已变得非常有价值。n 元模型(n-gram)在数字识别和跟踪大量的语言数据方面也已经变得非常有用。
语言模型简单来说就是一串词序列的概率分布。具体来说,语言模型的作用是为一个长度为m的文本确定一个概率分布P,表示这段文本存在的可能性。在实践中,如果文本的长度较长,P(wi | w1, w2, . . . , wi−1)的估算会非常困难。
因此,研究者们提出使用一个简化模型:n元模型(n-gram model)。在 n 元模型中估算条件概率时,只需要对当前词的前 n-1 个词进行计算。
在 n 元模型中,传统的方法一般采用频率计数的比例来估算 n 元条件概率。当 n 较大时,机会存在数据稀疏问题,导致估算结果不准确。因此,在百万词级别的语料中,一般也就用到三元模型。
为了缓解 n 元模型估算概率时遇到的数据稀疏问题,研究者们提出了神经网络语言模型。1997 年,LSTM 递归神经网络(RNN)模型被引入,并在 2007 年找到了语音和文本处理的利基市场。目前,神经网络模型被认为是 NLP 对文本和语音生成理解的最前沿研究。
2001年,法国 AI 专家约书亚·本吉奥(Yoshio Bengio)发表了一篇论文,提出了一种全新的语言神经网络模型。该模型使用前馈神经网络描述了一种不使用连接来形成循环的人工神经网络。
在这种类型的网络中,数据仅在一个方向上移动,从输入节点到任何隐藏节点,再到输出节点。前馈神经网络没有循环,与递归神经网络有很大不同。
本吉奥带来的全新思路启发了之后的很多基于神经网络的 NLP 学术研究,在工业界也得到了广泛使用,助力了 NLP 的应用在未来几年的加速落地。
此外,还有梯度消失(gradient vanishing)的细致分析,word2vec 的雏形,以及如今实现的机器翻译技术都有本吉奥的贡献。
当代 NLP 的研究
经过长期的发展,自然语言处理(NLP)被人们系统地定义为人工智能中的一门分支学科。除了机器翻译与人机交互意外,NLP 还包含以下高级功能的研究:
- 内容分类:语言文档摘要,包括内容警报,重复检测,搜索和索引。
- 主题发现和建模:捕获文本集合的主题和含义,并对文本进行高级分析。
- 上下文提取:自动从基于文本的源中提取结构化数据。
- 情绪分析:识别存储在大量文本中的总体情绪或主观意见,用于意见挖掘。
- 文本到语音和语音到文本的转换: 将语音命令转换为文本,反之亦然。
- 文档摘要:自动创建摘要,压缩大量文本。
- 机器翻译:自动将一种语言的文本或语音翻译成另一种语言。
在 2011 年,苹果公司的 Siri 成为世界上第一个成功被普通消费者使用的 NLP / AI 助手之一。在Siri 中,自动语音识别模块将所有的单词转换为数字解释的概念。
然后,语音命令系统会将这些概念与预定义的命令进行匹配,从而启动特定的操作。例如,如果 Siri 问:“您想听一下您的余额吗?” 它会理解你将要回答的“是”或“否”,并采取相应的行动。
通过使用机器学习技术,所有者的口语模式不必与预定义的表达式完全匹配。对于 NLP 系统来说,声音必须合理地接近才能正确翻译含义。通过使用反馈循环,NLP 引擎可以显着提高其翻译的准确性,并增加系统的词汇量。
训练有素的系统会理解“我在哪里可以得到大数据的帮助?”这样的字眼。“我在哪里可以找到大数据专家?”或“我需要大数据方面的帮助”,并提供适当的答复。
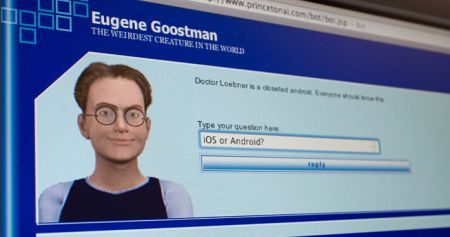
对话管理器与 NLP 的组合,使开发一个能够真正与人类对话的系统成为可能。2014 年 6 月 8 日,一个名为尤金·古斯特曼(Eugene Goostman)的电脑聊天程序成功让参与测试的 33% 人类裁判相信它是一个 13 岁的男孩,成为有史以来首台通过图灵测试的计算机。
NLP 的未来
近年来,在 NLP 领域中,使用语言模型预训练方法在多项 NLP 任务上都取得了突破性进展,广泛受到了各界的关注。
前文提到,目前神经网络在进行训练的时候基本都是基于后向传播(BP)算法,通过对网络模型参数进行随机初始化,然后通过 BP 算法利用例如 SGD 这样的优化算法去优化模型参数。
那么预训练的思想就是,该模型的参数不再是随机初始化,而是先有一个任务进行训练得到一套模型参数,然后用这套参数对模型进行初始化,再进行训练。
即通过在大量的语料上预训练语言模型,然后再将预训练好的模型迁移到具体的下游 NLP 任务,从而提高模型的能力。
得益于目前硬件算力的提升,预训练语言模型的参数规模呈指数倍增长。其中,GPT 模型是 OpenAI 在 2018 年提出的一种新的 ELMo 算法模型,该模型在预训练模型的基础上,只需要做一些微调即可直接迁移到各种 NLP 任务中,因此具有很强的迁移能力。
2019 年推出的 GPT-2 拥有 15 亿参数,到了 2020 年推出的 GPT-3 已经拥有惊人的 1750 亿参数,不仅能轻松通过图灵测试,还能完成包括写代码在内的大部分 NLP 任务。
神经网络之父、图灵奖获得者杰弗里·辛顿(Geoffrey Hinton)表示,“ 鉴于 GPT-3 在未来的惊人前景,可以得出结论:生命、宇宙和万物的答案,就只是 4.398 万亿个参数而已。”
这一观点也引发了人们的广泛讨论,被认为是对 NLP 发展尽头的预言。当未来人类的算力不断突破极限时,包含全人类文明的 GPT-N 是否会是 NLP 的终点呢?
来源:开源中国





