做好机器学习项目需要考虑的三大核心问题
一、如何根据实际项目中选择更为合适的算法?
常见的机器学习问题包括监督学习、分类、回归等问题,机器学习算法种类繁多,如何根据实际问题选择合适的机器学习算法就显得尤为重要,下面从三个方面考虑,分别为数据层面,问题层面,约束条件层面。最后介绍常用几种常用的机器学习算法。
sklearn算法流程图

(1)数据层面
数据层面要做的事情包括对数据的理解,当我们决定使用哪种算法时,我们所拥有的数据的类型和形态起着关键性的作用。有些算法可以利用较小的样本集合工作,而另一些算法则需要海量的样本。特定的算法对特定类型的数据起作用。
• 查看总结统计和数据可视化的结果(百分比,箱型图,平均数和中位数,相关系数)
• 数据处理(处理缺失值)
• 数据增强
(2)问题层面
我们面临的是个什么问题,分类,回归,预测,还是其他,按输入输出来分类
• 根据输入分类:
如果你拥有的是带标签的数据,那么这就是一个监督学习问题。
如果你拥有的是未标注过的数据,并且希望从中找到有用的结构,那么这就是一个无监督学习问题。
如果你想要通过与环境的交互来优化一个目标函数,那么这就是一个强化学习问题。
• 根据输出分类:
如果模型的输出是一个(连续的)数字,那么这就是一个回归问题。
如果模型的输出是一个类别,那么这就是一个分类问题。
如果模型的输出是一组用输入数据划分出的簇,那么这就是一个聚类问题。
你想发现一个异常点吗?此时你面对的就是一个异常检测问题。
(3)约束条件层面
• 存储数据的容量
• 预测过程的速度(实时分类系统)
• 学习过程的速度(在某些情况下,快速训练模型是十分必要的)

最初尝试时可以使用较少的数据量快速过滤出一些算法,最终选定少数的算法进行后续的优化。同时,对数据的理解程度也将影响模型的选择,对数据越熟悉越能够做出更高效的判断。
二、选择算法之后,如何评估我们模型?
机器学习是利用模型对数据进行拟合,对训练集进行拟合,训练模型,对样本外数据集进行预测。其中模型对训练集数据的误差称为经验误差(偏差), 对测试集数据的误差称为泛化误差(方差)。模型对样本外数据集的预测能力称为模型的泛化能力。建立模型之后,我们需要构建评估模型来评估模型的泛化能力,这是检验一个模型是否更为有效的方法。
两大问题
• 过拟合
欠拟合和过拟合都是模型泛化能力不高的表现。欠拟合通常表现为模型学习能力不足,没有学习到数据的一般规律。
• 欠拟合
过拟合则是模型捕捉到数据中太多的特征,以至于将所有特征都认为是数据的一般规律

最左边是欠拟合,中间是合理算法,右边是过拟合。
需要将数据拆分,即使用训练集进行训练, 测试集进行验证评估模型的准确性, 两个数据集不相交,从而验证模型的泛化能力。
K折交叉验证中k一般会选择5,10,20,其中k越大需要训练的次数越长,其误差估计的效果也越好。在验证中,训练集和测试集的数据分布应尽可能一致,如果不一致,可能会影响测试集的误差。

三、如何进一步优化模型以达到更理想的效果?
当模型的应用不理想时,我们应该如何优化模型?模型不理想主要来源于模型的欠拟合和过拟合,接下来该如何做?
学习曲线
学习曲线是通过画出不同训练集大小时训练集和交叉验证的准确率,可以看到模型在新数据上的表现,进而判断模型是否方差偏高或偏差过高,以及增大训练集是否可以减小过拟合。

当训练集与测试集的误差收敛但却很高时,为高偏差,左上角偏差较高,训练集和验证集的准确率很低,可能是欠拟合。当训练集与测试集的误差之间有很大的差距时,为高方差,右上角中方差较高,训练集的准确率要高于验证集的准确率,可能是过拟合。理想的状况是偏差和方差都很小,此时既不欠拟合也不过拟合。
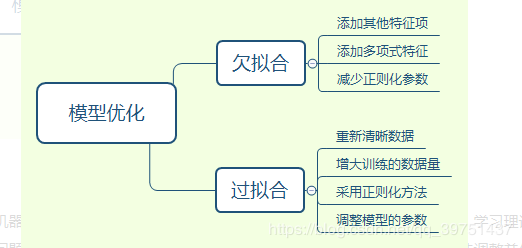
当模型出现过拟合或欠拟合时,可从以下几个方面考虑:
1. 数据量的多少。较少的数据量更容易过拟合,增大数据量对过拟合是有效的。
2. 增加或减少特征量。特征值较少会影响模型对样本数据的认识,导致欠拟合,增加特征值对欠拟合时有效的。
3. 增加或减少正则化。正则化的使用对过拟合是有效的。
优化思路:
四、常用的机器学习算法
线性回归
当你想要计算一些连续值,而不是将输出分类时,可以使用回归算法。因此,当你需要预测一个正在运行的过程未来的值时,你可以使用回归算法。然而,当特征冗余,即如果存在多重共线性(multicollinearity)时,线性回归就不太稳定。
Logistic 回归
Logistic 回归是二分类,因此输出二值标签。它将特征的线性组合作为输入,并且对其应用非线性函数(sigmoid),因此它是一个非常小的神经网络的实例。
logistic 回归提供了许多方法对你的模型进行正则化处理,可以很容易地更新你的模型以获取新的数据。如果你想要使用一个概率化的框架,或者你希望在未来能够快速地将更多的训练数据融合到你的模型中,你可以使用 logistic 回归算法。
决策树
决策树很少被单独使用,但是不同的决策树可以组合成非常高效的算法,例如随机森林或梯度提升树算法。
优点:
决策树很容易处理特征交互,并且决策树是一种非参数模型,所以你不必担心异常值或者数据是否是线性可分的。
它既可以处理离散值也可以处理连续值。
它基本不需要预处理,不需要提前归一化,处理缺失值。
缺点:
它们不支持在线学习,因此当你要使用新的样本时,你不得不重新构建决策树。
决策树算法非常容易过拟合,导致泛化能力不强。
它很容易发生过拟合,而这就是像随机森林(或提升树)这样的集成学习方法能够派上用场的地方。
决策树也需要大量的内存空间(拥有的特征越多,你的决策树可能会越深、越大)。
支持向量机
支持向量机在文本分类问题中非常流行,在该问题中,输入是一个维度非常高的空间是很正常的。然而,SVM 是一种内存密集型算法,它很难被解释,并且对其进行调优十分困难。支持向量机准确率高,对于防止过拟合很好的理论保障。当你使用一个合适的核函数时,即使你的数据在基(低维)特征空间中是线性不可分的,他们也可以很好地工作。
朴素贝叶斯
这是一种基于贝叶斯定理的分类技术,它很容易构建,非常适用于大规模数据集。如果朴素贝叶斯的条件独立假设确实成立,朴素贝叶斯分类器的收敛速度会比 logistic 回归这样的判别模型更快,因此需要的训练数据更少,最大的缺点就是它不能学习到特征之间的相互作用。
版权声明:本文为CSDN博主「田田天天甜甜」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_39751437/article/details/87353203





