学习的种类
参考书:图解机器学习
1. 监督学习
(1)定义:指有求知欲的学生从老师那里获取知识、信息,老师提供对错指示、告知最终答案的学习过程。
在机器学习中,计算机 = 学生,周围的环境 = 老师。
(2)最终目标:根据在学习过程中获得的经验技能,对没学习过的问题也可以做出正确解答,使计算机获得这种泛化能力。
(3)应用:手写文字识别、声音处理、图像处理、垃圾邮件分类与拦截、网页检索、基因诊断、股票预测等。
(4)典型任务:预测数值型数据的回归、预测分类标签的分类、预测顺序的排列
(5)我的理解:计算机在正确输出的不断更正和指引下,不断提高自己分析和解决问题的正确性。
2. 无监督学习
(1)定义:指在没有老师的情况下,学生自学的过程。
在机器学习中,计算机从互联网中自动收集信息,并获取有用信息。
(2)最终目标:无监督学习不局限于解决有正确答案的问题,所以目标可以不必十分明确。
(3)应用:人造卫星故障诊断、视频分析、社交网站解析、声音信号解析、数据可视化、监督学习的前处理工具等。
(4)典型任务:聚类、异常检测。
(5)我的理解:计算机从网络中获取有用的信息。
3. 强化学习
(1)定义:指在没有老师提示的情况下,自己对预测的结果进行评估的方法。通过这样的自我评估,学生为了获得老师的最高价将而不断的进行学习。
强化学习被认为使人类主要的学习模式之一。
(2)最终目标:使计算机获得对没学习过的问题也可以做出正确解答的泛化能力。
(3)应用:机器人的自动控制、计算机游戏中的人工智能、市场战略的最优化等。
(4)典型任务:回归、分类、聚类、降维。
(5)我的理解:与监督学习不同的是,强化学习没有正确输出的引导,也就是没有正确的答案;与无监督学习不同的是,强化学习需要对获取到的信息进行自我评估。
典型任务
1. 回归
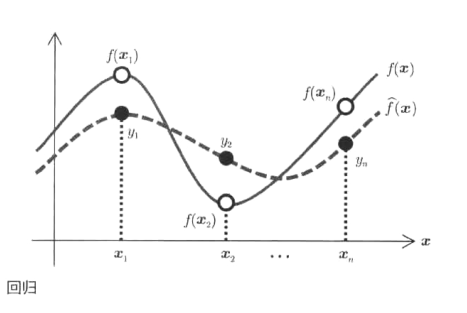
(1)定义:指把实函数在样本点附近加以近似的有监督的函数近似问题。
(2)我的理解:对于一组输入x,通过函数f计算,有一组正确的输出y,计算机通过函数f’计算,得出自己的输出y’,计算机通过比较自己的输出和正确输出的过程中,改进自己的f’,使其接近于真真实函数f(在计算机比较自己的输出与正确输出的过程中,会产生噪声)。
2. 分类
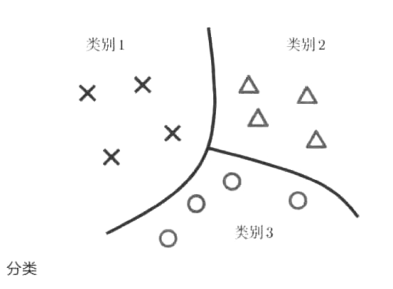
(1)定义:指对于指定的模式进行识别的有监督的模型识别问题。
(2)我的理解:与回归类似,但是输出的是对输入的分类。
3. 异常检测

(1)定义:指寻找输入样本中所包含的异常数据的问题。
(2)我的理解:计算机通过对一组数据的分析,将中间的异常数据剔除。若已知异常数据,则与有监督的分类类似;一般情况下并不知道异常数据,多采用密度估计的方法,剔除偏离密度中心的数据。
4. 聚类

(1)定义:与分类问题相同,也是模式识别的问题,但是属于无监督学习的一种。
(2)我的理解:与分类类似,但是只有输入,需要计算机自己分出数据属于哪一簇(聚类中,用簇代替类别)。
5. 降维

(1)指从高维度数据中提取关键信息,将其转换为易于计算的低维度问题进而求解。
若输入输出均已知,属于监督学习;若只有输入已知,属于无监督学习,注意在转换为低维度的样本后,应保持原始输入样本的数据分布性质,以及数据间的近邻关系不发生变化。
(2)我的理解:计算机通过对高维度数据降维,使得其维度降低但是数据特征和数据间的关系不变,便于分析和解决。
版权声明:本文为CSDN博主「Geeeeek_Xuan」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/by4_Luminous/article/details/53341334





