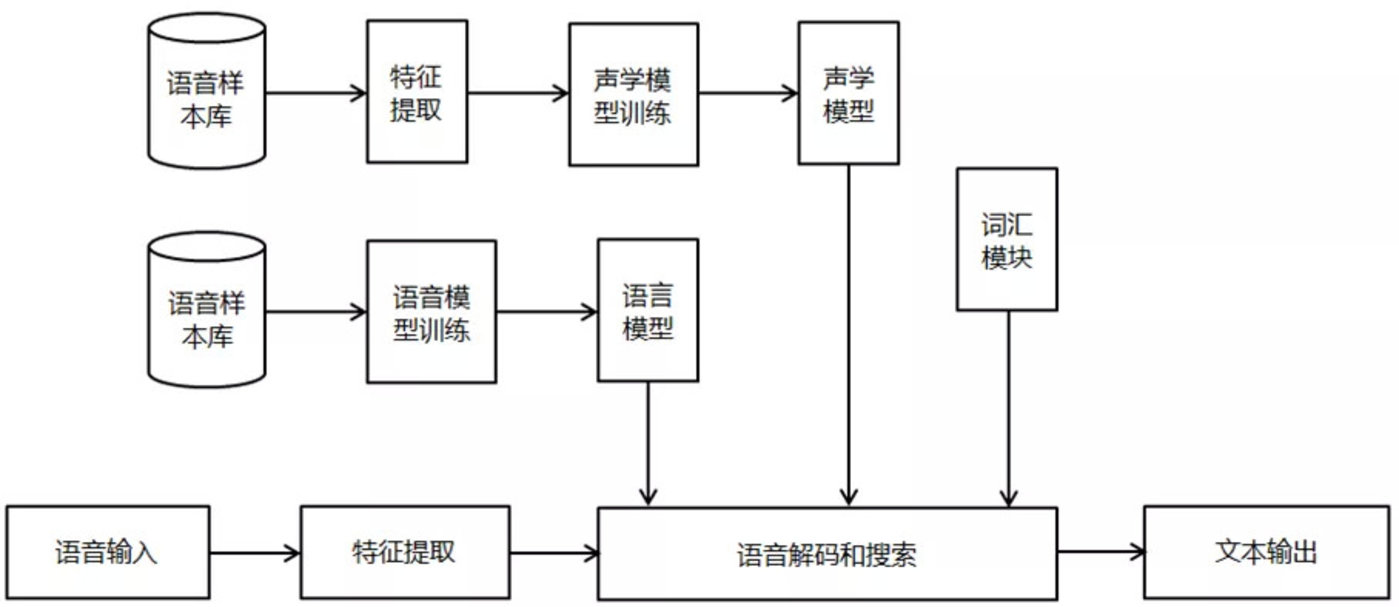
语音识别技术是让机器通过识别把语音信号转变为文本,进而通过理解转变为指令的技术。目的就是给机器赋予人的听觉特性,听懂人说什么,并作出相应的行为。语音识别系统通常由声学识别模型和语言理解模型两部分组成,分别对应语音到音节和音节到字的计算。一个连续语音识别系统(如下图)大致包含了四个主要部分:特征提取、声学模型、语言模型和解码器等。
(1)语音输入的预处理模块
对输入的原始语音信号进行处理,滤除掉其中的不重要信息以及背景噪声,并进行语音信号的端点检测(也就是找出语音信号的始末)、语音分帧(可以近似理解为,一段语音就像是一段视频,由许多帧的有序画面构成,可以将语音信号切割为单个的“画面”进行分析)等处理。
(2)特征提取
在去除语音信号中对于语音识别无用的冗余信息后,保留能够反映语音本质特征的信息进行处理,并用一定的形式表示出来。也就是提取出反映语音信号特征的关键特征参数形成特征矢量序列,以便用于后续处理。
(3)声学模型训练
声学模型可以理解为是对声音的建模,能够把语音输入转换成声学表示的输出,准确的说,是给出语音属于某个声学符号的概率。根据训练语音库的特征参数训练出声学模型参数。在识别时可以将待识别的语音的特征参数与声学模型进行匹配,得到识别结果。目前的主流语音识别系统多采用隐马尔可夫模型HMM进行声学模型建模。
(4)语言模型训练
语言模型是用来计算一个句子出现概率的模型,简单地说,就是计算一个句子在语法上是否正确的概率。因为句子的构造往往是规律的,前面出现的词经常预示了后方可能出现的词语。它主要用于决定哪个词序列的可能性更大,或者在出现了几个词的时候预测下一个即将出现的词语。它定义了哪些词能跟在上一个已经识别的词的后面(匹配是一个顺序的处理过程),这样就可以为匹配过程排除一些不可能的单词。
语言建模能够有效的结合汉语语法和语义的知识,描述词之间的内在关系,从而提高识别率,减少搜索范围。对训练文本数据库进行语法、语义分析,经过基于统计模型训练得到语言模型。
(5)语音解码和搜索算法
解码器是指语音技术中的识别过程。针对输入的语音信号,根据己经训练好的HMM声学模型、语言模型及字典建立一个识别网络,根据搜索算法在该网络中寻找最佳的一条路径,这个路径就是能够以最大概率输出该语音信号的词串,这样就确定这个语音样本所包含的文字了。所以,解码操作即指搜索算法,即在解码端通过搜索技术寻找最优词串的方法。
连续语音识别中的搜索,就是寻找一个词模型序列以描述输入语音信号,从而得到词解码序列。搜索所依据的是对公式中的声学模型打分和语言模型打分。在实际使用中,往往要依据经验给语言模型加上一个高权重,并设置一个长词惩罚分数。
本文转自网络,转载此文目的在于传递更多信息,版权归原作者所有。





