概述
数据预处理(data pre-processing)是指在主要的处理以前对数据进行的一些处理。现实世界中数据大体上都是不完整,不一致的脏数据,无法直接进行数据挖掘,或挖掘结果差强人意。为了提高数据挖掘的质量产生了数据预处理技术。
数据预处理在数据挖掘之前使用,大大提高了数据挖掘模式的质量,降低实际挖掘所需要的时间。
预处理内容
数据审核
从不同渠道取得的统计数据,在审核的内容和方法上有所不同。
对于原始数据应主要从完整性和准确性两个方面去审核。
完整性审核主要是检查应调查的单位或个体是否有遗漏,所有的调查项目或指标是否填写齐全。
准确性审核主要是包括两个方面:一是检查数据资料是否真实地反映了客观实际情况,内容是否符合实际;二是检查数据是否有错误,计算是否正确等。审核数据准确性的方法主要有逻辑检查和计算检查。逻辑检查主要是审核数据是否符合逻辑,内容是否合理,各项目或数字之间有无相互矛盾的现象,此方法主要适合对定性(品质)数据的审核。计算检查是检查调查表中的各项数据在计算结果和计算方法上有无错误,主要用于对定量(数值型)数据的审核。
对于通过其他渠道取得的二手资料,除了对其完整性和准确性进行审核外,还应该着重审核数据的适用性和时效性。
二手资料可以来自多种渠道,有些数据可能是为特定目的通过专门调查而获得的,或者是已经按照特定目的需要做了加工处理。对于使用者来说,首先应该弄清楚数据的来源、数据的口径以及有关的背景资料,以便确定这些资料是否符合自己分析研究的需要,是否需要重新加工整理等,不能盲目生搬硬套。此外,还要对数据的时效性进行审核,对于有些时效性较强的问题,如果取得的数据过于滞后,可能失去了研究的意义。一般来说,应尽可能使用最新的统计数据。数据经审核后,确认适合于实际需要,才有必要做进一步的加工整理。
数据审核的内容主要包括以下四个方面:
1. 准确性审核。
主要是从数据的真实性与精确性角度检查资料,其审核的重点是检查调查过程中所发生的误差。
2. 适用性审核。
主要是根据数据的用途,检查数据解释说明问题的程度。具体包括数据与调查主题、与目标总体的界定、与调查项目的解释等是否匹配。
3. 及时性审核。
主要是检查数据是否按照规定时间报送,如未按规定时间报送,就需要检查未及时报送的原因。
4. 一致性审核。
主要是检查数据在不同地区或国家、在不同的时间段是否具有可比性。
数据筛选
对审核过程中发现的错误应尽可能予以纠正。调查结束后,当数据发现的错误不能予以纠正,或者有些数据不符合调查的要求而又无法弥补时,就需要对数据进行筛选。
数据筛选包括两方面的内容:
一是将某些不符合要求的数据或有明显错误地数据予以剔除;
二是将符合某种特定条件的数据筛选出来,对不符合特定条件的数据予以剔除。数据的筛选在市场调查、经济分析、管理决策中是十分重要的。
数据排序
数据排序是按照一定顺序将数据排列,以便于研究者通过浏览数据发现一些明显的特征或趋势,找到解决问题的线索。除此之外,排序还有助于对数据检查纠错,为重新归类或分组等提供依据。在某些场合,排序本身就是分析的目的之一。排序可借助于计算机很容易的完成。
对于分类数据,如果是字母型数据,排序有升序与降序之分,但习惯上升序使用得更为普遍,因为升序与字母的自然排列相同;如果是汉字型数据,排序方式有很多,比如按汉字的首位拼音字母排列,这与字母型数据的排序完全一样,也可按笔画排序,其中也有笔画多少的升序降序之分。交替运用不同方式排序,在汉字型数据的检查纠错过程中十分有用。
对于数值型数据,排序只有两种,即递增和递减。排序后的数据也称为顺序统计量。
数据方法
去除唯一属性
唯一属性通常是一些id属性,这些属性并不能刻画样本自身的分布规律,所以简单地删除这些属性即可。
处理缺失值
缺失值处理的三种方法:
① 直接使用含有缺失值的特征;
② 删除含有缺失值的特征(该方法在包含缺失值的属性含有大量缺失值而仅仅包含极少量有效值时是有效的);
③ 缺失值补全。
常见的缺失值补全方法:均值插补、同类均值插补、建模预测、高维映射、多重插补、极大似然估计、压缩感知和矩阵补全。
(1)均值插补
如果样本属性的距离是可度量的,则使用该属性有效值的平均值来插补缺失的值;
如果的距离是不可度量的,则使用该属性有效值的众数来插补缺失的值。
(2)同类均值插补
首先将样本进行分类,然后以该类中样本的均值来插补缺失值。
(3)建模预测
将缺失的属性作为预测目标来预测,将数据集按照是否含有特定属性的缺失值分为两类,利用现有的机器学习算法对待预测数据集的缺失值进行预测。
该方法的根本的缺陷是如果其他属性和缺失属性无关,则预测的结果毫无意义;但是若预测结果相当准确,则说明这个缺失属性是没必要纳入数据集中的;一般的情况是介于两者之间。
(4)多重插补
多重插补认为待插补的值是随机的,实践上通常是估计出待插补的值,再加上不同的噪声,形成多组可选插补值,根据某种选择依据,选取最合适的插补值。
(5)手动插补
插补处理只是将未知值补以我们的主观估计值,不一定完全符合客观事实。在许多情况下,根据对所在领域的理解,手动对缺失值进行插补的效果会更好。
数据标准化
数据标准化是将样本的属性缩放到某个指定的范围。
数据标准化的原因:某些算法要求样本具有零均值和单位方差;
需要消除样本不同属性具有不同量级时的影响:
①数量级的差异将导致量级较大的属性占据主导地位;
②数量级的差异将导致迭代收敛速度减慢;
③依赖于样本距离的算法对于数据的数量级非常敏感。
min-max标准化(归一化):对于每个属性,设minA和maxA分别为属性A的最小值和最大值,将A的一个原始值x通过min-max标准化映射成在区间[0,1]中的值x’,其公式为:新数据=(原数据 - 最小值)/(最大值 - 最小值)
z-score标准化(规范化):基于原始数据的均值(mean)和标准差(standarddeviation)进行数据的标准化。将A的原始值x使用z-score标准化到x’。z-score标准化方法适用于属性A的最大值和最小值未知的情况,或有超出取值范围的离群数据的情况。新数据=(原数据- 均值)/ 标准差
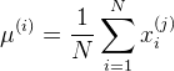

均值和标准差都是在样本集上定义的,而不是在单个样本上定义的。标准化是针对某个属性的,需要用到所有样本在该属性上的值。
数据正则化
数据正则化是将样本的某个范数(如L1范数)缩放到到位1,正则化的过程是针对单个样本的,对于每个样本将样本缩放到单位范数。
设数据集
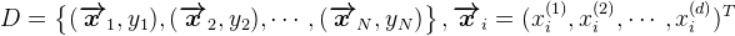
对样本首先计算Lp范数:
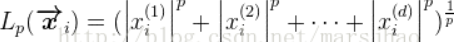
正则化后的结果为:每个属性值除以其Lp范数:
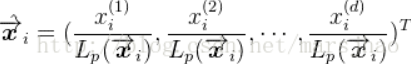
特征选择(降维)
从给定的特征集合中选出相关特征子集的过程称为特征选择。
进行特征选择的两个主要原因是:
① 减轻维数灾难问题;
② 降低学习任务的难度。
进行特征选择必须确保不丢失重要特征。
常见的特征选择类型分为三类:过滤式(filter)、包裹式(wrapper)、嵌入式(embedding)。
过滤式选择:
该方法先对数据集进行特征选择,然后再训练学习器。特征选择过程与后续学习器无关。Relief是一种著名的过滤式特征选择方法。
包裹式选择:
该方法直接把最终将要使用的学习器的性能作为特征子集的评价原则。其优点是直接针对特定学习器进行优化,因此通常包裹式特征选择比过滤式特征选择更好,缺点是由于特征选择过程需要多次训练学习器,故计算开销要比过滤式特征选择要大得多。
版权声明:本文为CSDN博主「是DRR啊」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_25041667/article/details/102021883





