作者 | Walker
深度学习和机器学习已经变得无处不在,那它们之间到底有什么区别呢?本文我们为大家总结了深度学习VS机器学习的六大本质区别。
一、数据相关性
深度学习与传统机器学习最重要的区别是,随着数据量的增加,其性能也随之提高。当数据很小的时候,深度学习算法并不能很好地执行,这是因为深度学习算法需要大量的数据才能完全理解它。
下图便能很好的说明这个事实:
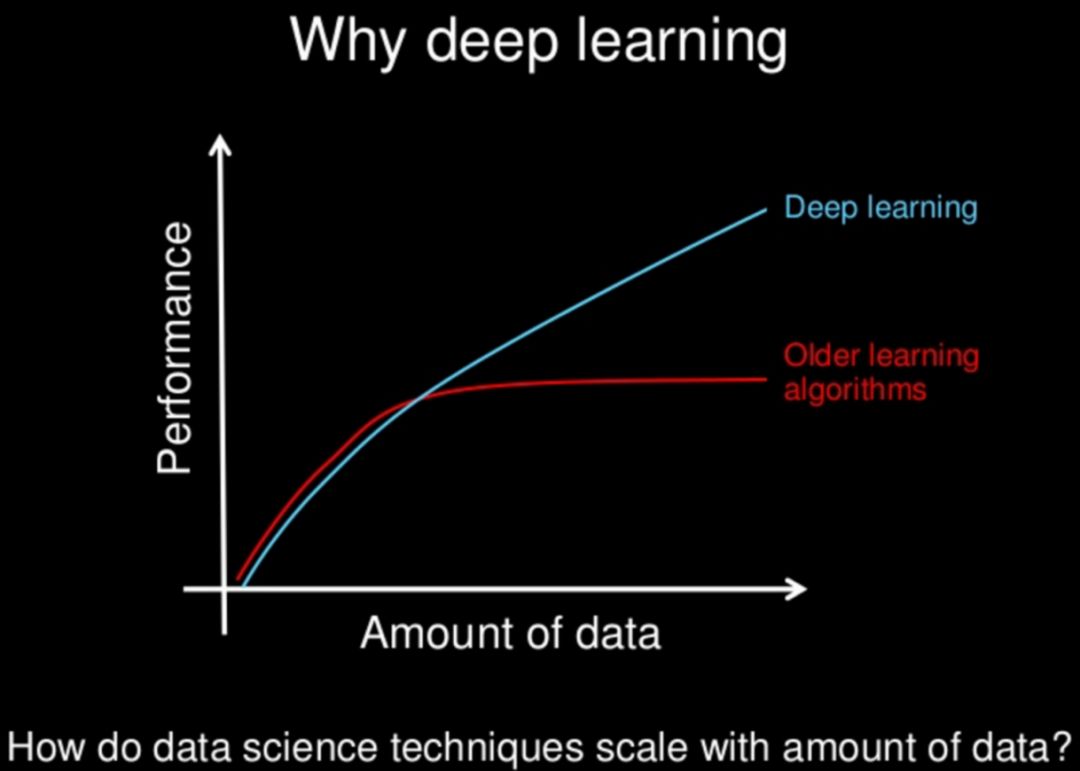
从上图我们可以看到,随着数据量的增大,深度学习的性能会越来越好,而传统机器学习方法性能表现却趋于平缓;但传统的机器学习算法在数据量较小的情况下,比深度学习有着更好的表现。
二、硬件依赖性
深度学习算法在很大程度上依赖于高端机器,而传统的机器学习算法可以在低端机器上工作。这是因为深度学习算法对GPU有较高的要求,GPU是其工作的一个组成部分。因为深度学习算法要固有地执行大量的矩阵乘法运,而使用GPU可以有效地优化这些操作,这就免不了对GPU的依赖。而相比之下,机器学习算法对硬件配置没有很高的要求。
三、特征工程
特征工程是将领域知识应用到特征抽取的创建过程,以降低数据的复杂性为目的。但这一过程在训练时间和如何提取特征方面十分地困难。
在机器学习中,大多数应用的特征需要由专家识别,然后根据域和数据类型手工编码。
例如,特征可以是像素值、形状、纹理、位置和方向,大多数机器学习算法的性能取决于特征识别和提取的准确程度。
而深度学习算法则试图从数据中学习更高级的特性。这是深度学习一个非常独特的部分,也是有别于传统机器学习的一部分。因此,深度学习减少了为每个问题开发新的特征抽取的任务,而是像卷积神经网络(CNN)这样尝试学习低层次的特征,如:早期层次的边缘和线条,然后是人脸的一部分,最后才是人脸的高层次表示。这样的方式相较于机器学习,在训练时间和成本上有较高的提升。

四、解决问题方法
在使用传统的机器学习算法解决问题时,通常的做法是将问题分解成不同的部分,然后单独解决,最后结合起来得到结果。相比之下,深度学习更提倡端到端地解决问题。让我们举个例子来理解这一点。

如图所示是一个多对象检测任务,我们的目标是哟啊确定对象是什么以及它在图像中的位置。
在典型的机器学习方法中,我们会将问题分为两个步骤:对象检测和对象识别。首先,我们将使用一个边界检测算法,如:GrabCut,来浏览图像并找到图像中所有可能的对象;然后,在所有已识别的对象中,我们再使用对象识别算法(如:SVM)来识别相关对象,最后再判断对象的位置。
不同于传统机器学习算法,在深度学习的方法中,我们将进行端到端的学习过程。例如,使用YOLO算法(一种深度学习算法)。我们往YOLO网络中传入一张图像,它将给出对象的具体位置和名称。是不是方便了很多呢?
五、执行时间
通常,深度学习算法需要很长的时间来训练,这是因为在深度学习算法中有太多的参数,所以训练这些参数的时间比平时要长。即使比较先进的深度学习算法Resnet,从零开始完全训练也需要大约两周的时间。相比之下,机器学习所需的训练时间要少得多,从几秒钟到几个小时不等。
相较于训练时间,测试时间就要短很多。在测试时,深度学习算法的运行时间要短得多。但是,如果将其与k近邻机器学习算法进行比较,测试时间会随着数据大小的增加而增加。但这并不适用于所有机器学习算法,因为其中一些算法的测试时间也很短。
六、可解释性
最后,我们将可解释性作为比较机器学习和深度学习的一个因素。这一因素也是深度学习难以在工业中取得大规模应用的主要原因。
我们举个例子:假设我们使用深度学习为论文自动评分,它在得分方面的表现相当出色,接近于人类的表现。但有一个问题:深度学习并没有揭示它为什么会给出那个分数。事实上,从数学中我们可以发现深度神经网络的哪些节点被激活,但是我们不知道神经元应该做什模型以及这些神经元层共同在做什么,所以我们无法对结果进解释。
而相较于深度学习,类似于决策树这样的机器学习算法为我们提供了清晰的规则,告诉我们什么是它的选择以及为什么选择了它,很容易解释算法背后的推理。因此,决策树和线性/逻辑回归等机器学习算法主要用于工业中需要可解释性的场景。
本文转自:磐创AI(xunixs),作者: Walker,转载此文目的在于传递更多信息,版权归原作者所有。





