在CNN中,转置卷积是一种上采样(up-sampling)的方法。如果你对转置卷积感到困惑,那么就来读读这篇文章吧。
本文的notebook代码在Github(https://github.com/naokishibuya/deep-learning/blob/master/python/transpo...)
上采样的需要
在我们使用神经网络的过程中,我们经常需要上采样(up-sampling)来提高低分辨率图片的分辨率。
上采样有诸多方法,举例如下。
最近邻插值(Nearest neighbor interpolation)
双线性插值(Bi-linear interpolation)
双立方插值(Bi-cubic interpolation)
但是,上述的方法都需要插值操作,而这些插值的操作都充满了人为设计和特征工程的气息,而且也没有网络进行学习的余地。
为何需要转置卷积
如果我们想要网络去学出一种最优的上采样方法,我们可以使用转置卷积。它与基于插值的方法不同,它有可以学习的参数。
若是想理解转置卷积这个概念,可以看看它是如何运用于在一些有名的论文和项目中的。
DCGAN的生成器(generator)接受一些随机采样的值作为输入来生成出完整的图片。它的语义分割(semantic segmentation)就使用了卷积层来提取编码器(encoder)中的特征,接着,它把原图存储在解码器(decoder)中以确定原图中的每个像素的类别归属。
转置卷积也被称作: “分数步长卷积(Fractionally-strided convolution)”和”反卷积(Deconvolution)”.
我们在这篇文章里面只使用转置卷积这个名字,其他文章可能会用到其他名字. 这些名字指的都是同样的东西.
卷积操作
我们先通过一个简单的例子来看看卷积是怎么工作的.
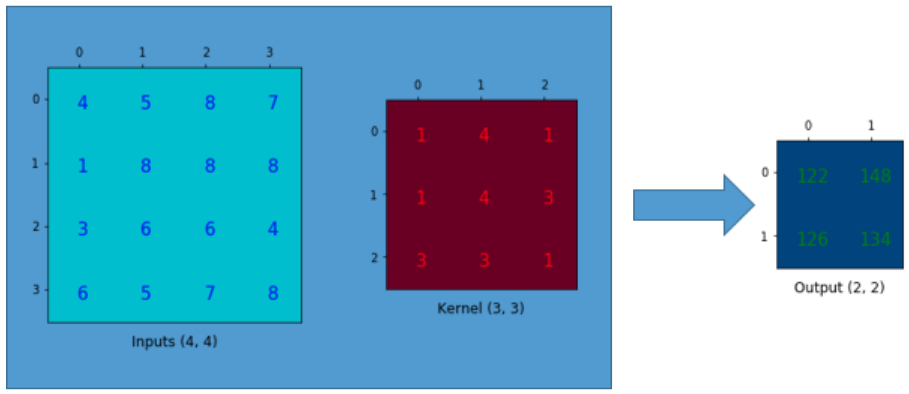
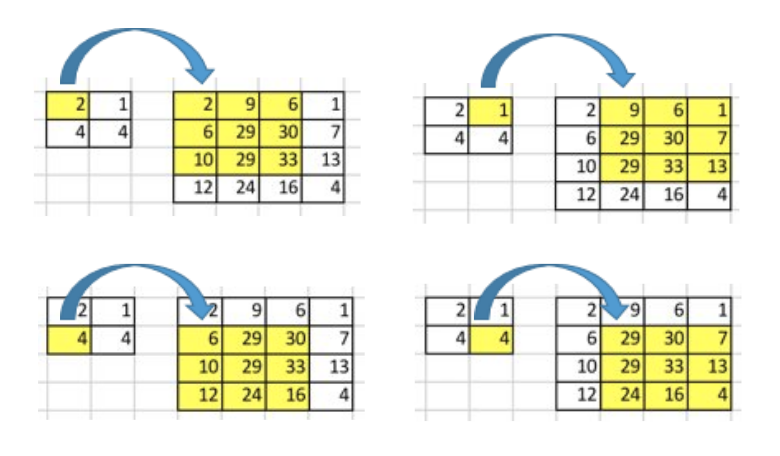
假设我们有一个4x4的input矩阵, 并对它使用核(kernel)为3x3,没有填充(padding),步长(stride)为1的卷积操作. 结果是一个2x2的矩阵,如下图所示.
(译者注: stride,kernel,padding等词以下记为英文)
卷积操作的本质其实就是在input矩阵和kernel矩阵之间做逐元素(element-wise)的乘法然后求和. 因为我们的stride为1,不使用padding,所以我们只能在4个位置上进行操作.
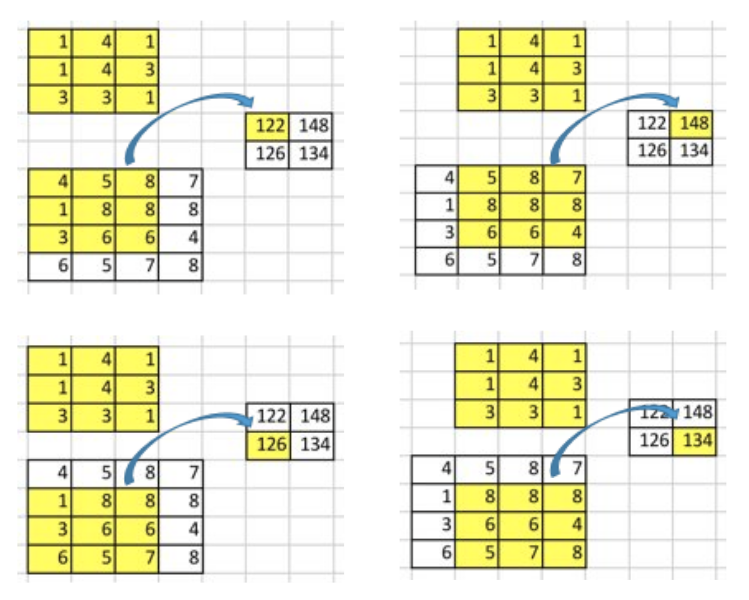
要点:卷积操作其实就是input值和output值的位置性关系(positional connectivity).
例如,在input矩阵的左上角的值会影响output矩阵的左上角的值.
更进一步,3x3的核建立了input矩阵中的9个值和output矩阵中的1个值的关系.
“卷积操作建立了多对一的关系”. 在阅读下文时,请读者务必时刻牢记这个概念.
卷积的逆向操作
现在,考虑一下我们如何换一个计算方向. 也就是说,我们想要建立在一个矩阵中的1个值和另外一个矩阵中的9个值的关系.这就是像在进行卷积的逆向操作,这就是转置卷积的核心思想.
(译者注:从信息论的角度看,卷积是不可逆的.所以这里说的并不是从output矩阵和kernel矩阵计算出原始的input矩阵.而是计算出一个保持了位置性关系的矩阵.)
但是,我们如何进行这种逆向操作呢?
为了讨论这种操作,我们先要定义一下卷积矩阵和卷积矩阵的转置.
卷积矩阵
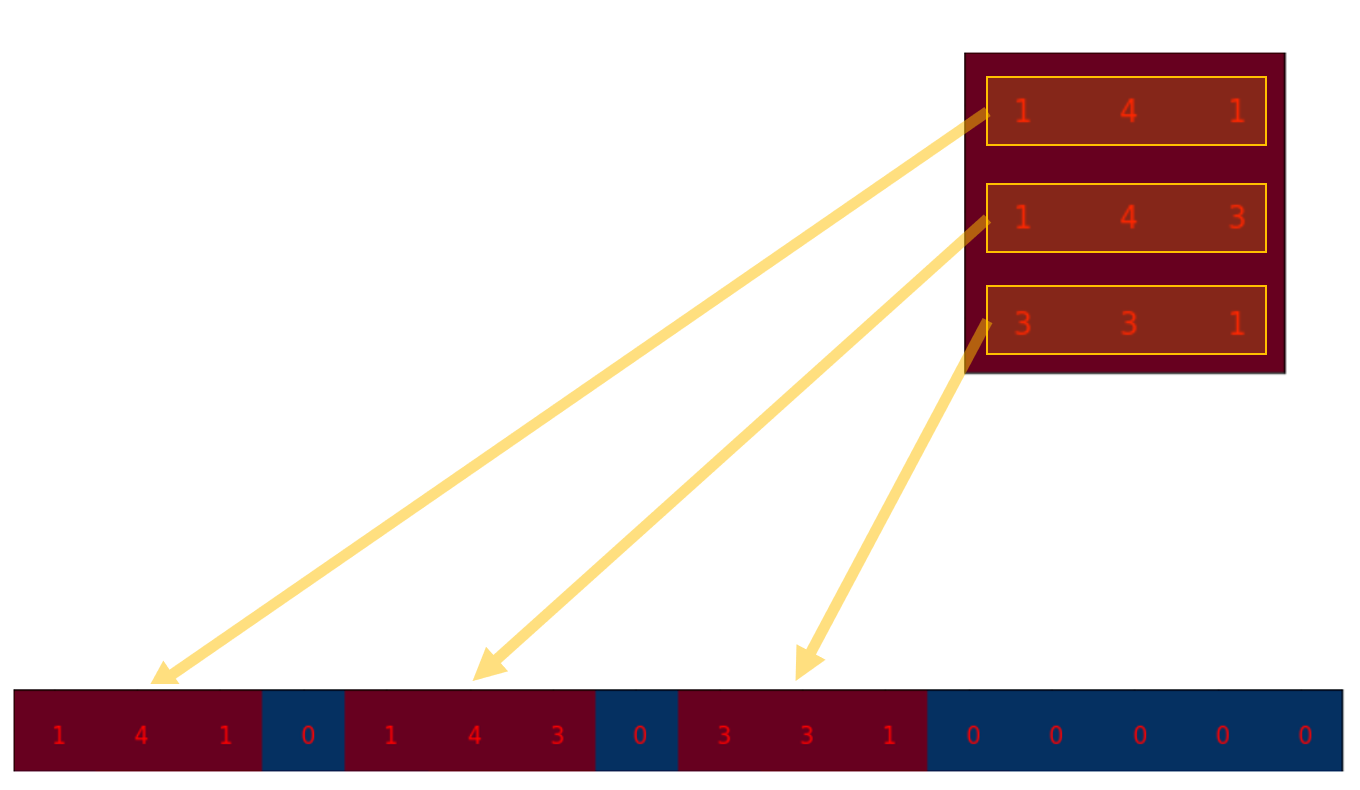
我们可以将卷积操作写成一个矩阵. 其实这就是重新排列一下kernel矩阵, 使得我们通过一次矩阵乘法就能计算出卷积操作后的矩阵.

我们将3x3的kernel重排为4x16的矩阵,如下:

这就是卷积矩阵. 每一行都定义了一次卷积操作. 如果你还看不透这一点, 可以看看下面的图. 卷积矩阵的每一行都相当于经过了重排的kernel矩阵,只是在不同的位置上有zero padding罢了.
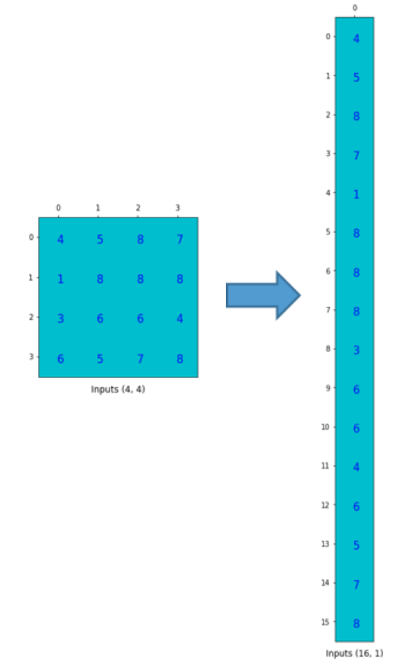
为了实现矩阵乘法,我们需要将尺寸为4x4的input矩阵压扁(flatten)成一个尺寸为16x1的列向量(column vector).
然后,我们对4x16的卷积矩阵和1x16的input矩阵(就是16维的列向量,只是看成一个矩阵)进行矩阵乘法.
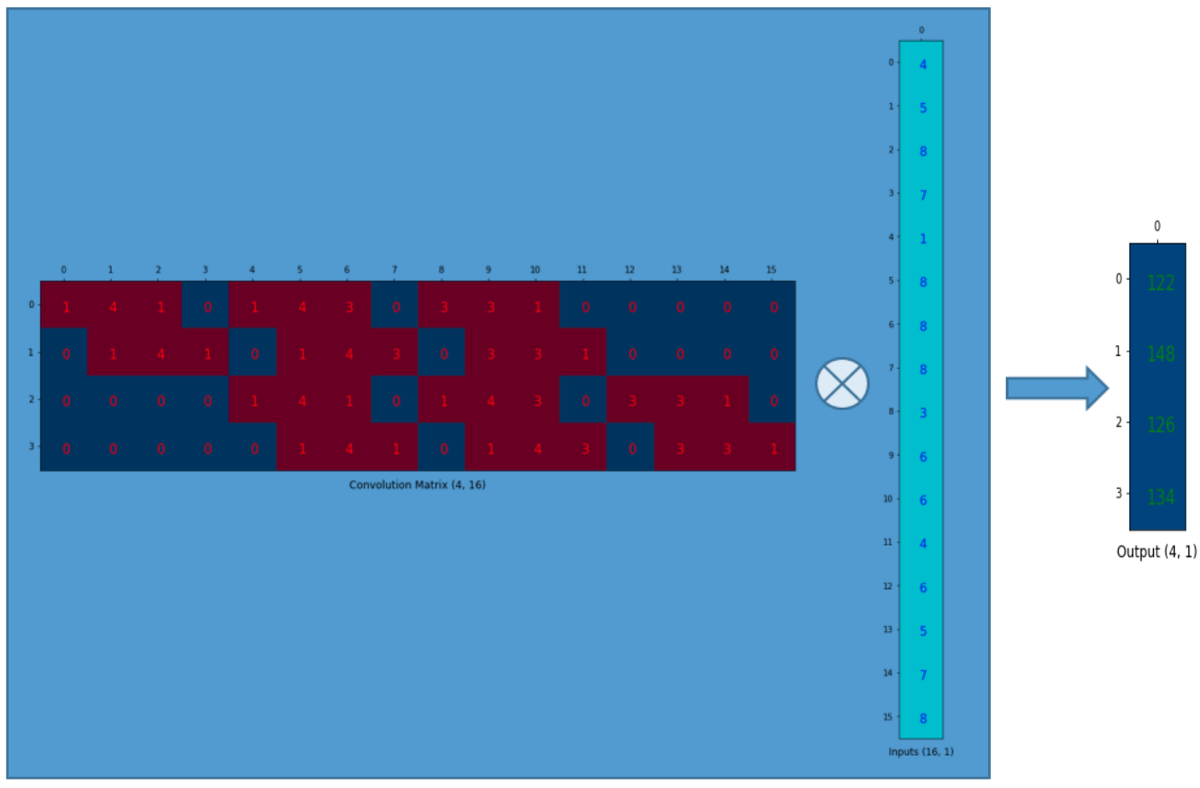
尺寸为4x1的output矩阵可以重排为2x2的矩阵.这正和我们之前得到的结果一致.

一句话,一个卷积矩阵其实就是kernel权重的重排,一个卷积操作可以被写成一个卷积矩阵.
即便这样又如何呢?
我想说的是: 使用这个卷积矩阵,你可以把16(4x4的矩阵)个值映射为4(2x2的矩阵)个值. 反过来做这个操作,你就可以把4(2x2的矩阵)个值映射为16(4x4的矩阵)辣.
蒙了?
继续读.
转置过后的卷积矩阵
我们想把4(2x2的矩阵)个值映射为16(4x4的矩阵)个值。但是,还有一件事!我们需要维护1对9的关系。
假设我们转置一下卷积矩阵C(4x16),得到C.T(16x4)。我们可以将C.T(16x4)和一个列向量(4x1)以矩阵乘法相乘,得到尺寸为16x1的output矩阵。转置之后的矩阵建立了1个值对9个值的关系。
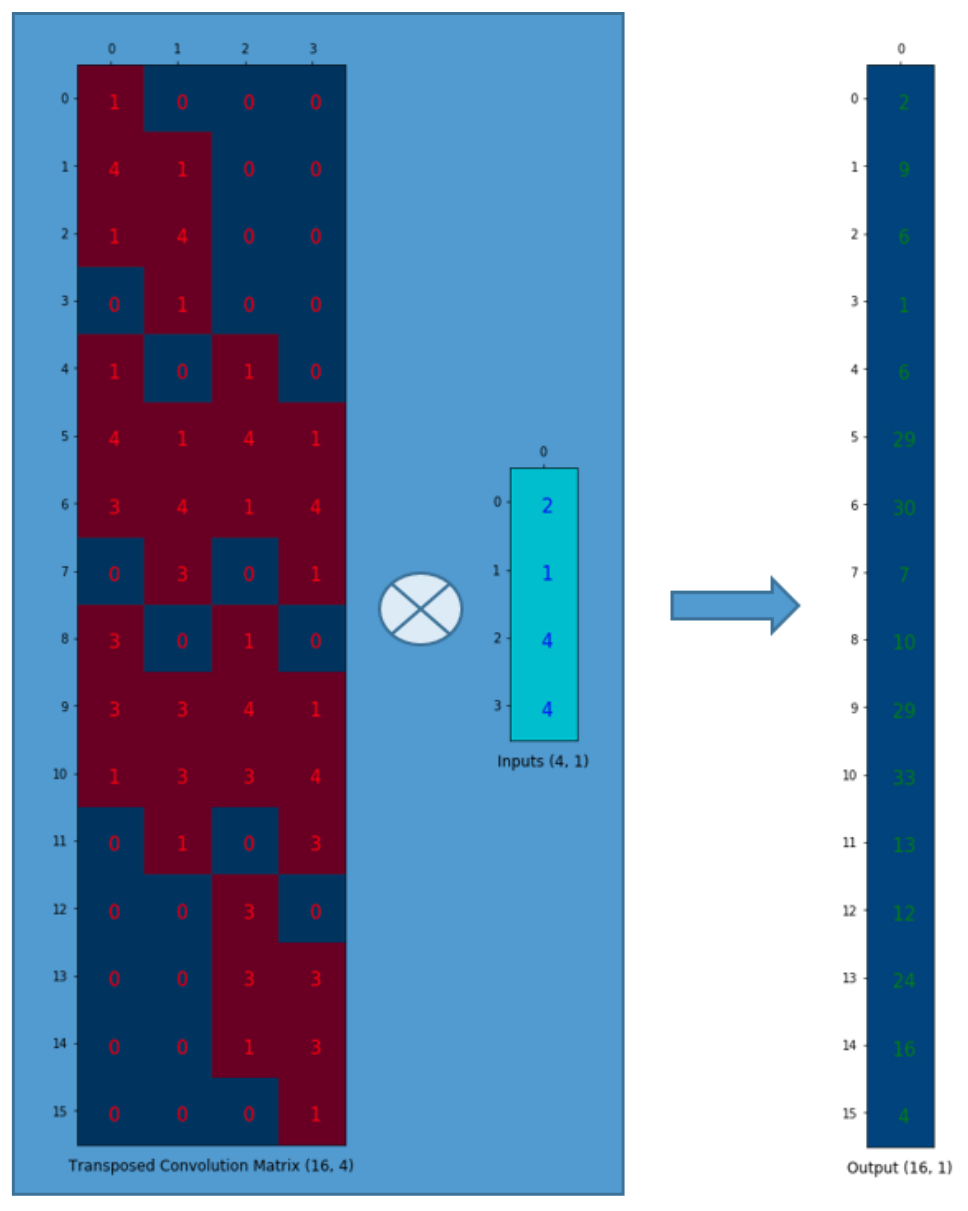
output矩阵可以被重排为4x4的.

我们已经上采样了一个小矩阵(2x2),得到了一个大矩阵(4x4)。转置卷积依然维护着1对9的关系:因为权重就是这么排的。
注意:用来进行转置卷积的权重矩阵不一定来自于(come from)原卷积矩阵。重点是权重矩阵的形状和转置后的卷积矩阵相同。
总结
转置卷积和普通卷积有相同的本质:建立了一些值之间的关系。只不过,转置卷积所建立的这个关系与普通卷积所建立的关系,方向相反。
我们可以使用转置卷积来进行上采样。并且,转置卷积中的权重是可以被学习的。因此,我们没有必要搞什么插值方法来做上采样。
尽管它被称作转置卷积,但是这并不意味着我们是拿一个已有的卷积矩阵的转置来作为权重矩阵的来进行转置卷积操作的. 和普通卷积相比,intput和output的关系被反向处理(转置卷积是1对多,而不是普通的多对1),才是转置卷积的本质。
正因如此,严格来说转置卷积其实并不算卷积。但是我们可以把input矩阵中的某些位置填上0并进行普通卷积来获得和转置卷积相同的output矩阵。你可以发现有一大把文章说明如何使用这种方法实现转置卷积。然而,因为需要在卷积操作之前,往input中填上许多的0,这种方法其实有点效率问题.
警告:转置卷积会在生成的图像中造成棋盘效应(checkerboard artifacts)。本文推荐在使用转置卷积进行上采样操作之后再过一个普通的卷积来减轻此类问题。如果你主要关心如何生成没有棋盘效应的图像,需要读一读paper。
References
[1] A guide to convolution arithmetic for deep learning
Vincent Dumoulin, Francesco Visin
https://arxiv.org/abs/1603.07285
[2] Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks
Alec Radford, Luke Metz, Soumith Chintala
https://arxiv.org/pdf/1511.06434v2.pdf
[3] Fully Convolutional Networks for Semantic Segmentation
Jonathan Long, Evan Shelhamer, Trevor Darrell
https://people.eecs.berkeley.edu/~jonlong/long_shelhamer_fcn.pdf
[4] Deconvolution and Checkerboard Artifacts
Augustus Odena, Vincent Dumoulin, Chris Olah
https://distill.pub/2016/deconv-checkerboard/
原文:Up-sampling with Transposed Convolution
https://towardsdatascience.com/up-sampling-with-transposed-convolution-9...
本文转自:CSDN - lanadeus,转载此文目的在于传递更多信息,版权归原作者所有。