1. 介绍
这份教学包是针对那些对人工神经网络(ANN)没有接触过、基本上完全不懂的一批人做的一个简短入门级的介绍。我们首先简要的引入网络模型,然后才开始讲解ANN的相关术语。作为一个应用的案例,我们解释了后向传播算法,毕竟这一算法已经得到广泛应用并且许多别的算法也是从它继承而来的。
读者应该已经了解线性代数相关知识,也能解决一些函数和向量问题,如果掌握微积分知识更好但不是必须的。这份教学包的内容对一名高中毕业生来讲就已经能理解了。同时,对那些对ANN感兴趣或者想加深理解的人来说也是很有益处的。因此如果读者能全部看完这边教学包,应该对ANN的概念有个清楚的理解。另外对那些想运用后向传播算法但又对晦涩难懂的公式细节不想深入理解的读者来讲,这份教学包你选对了!这份包不应看做是网络上的科普读物,但也不是一篇枯燥的研究论文。为了简洁许多公式都删除了,具体细节的解释和演示在后面的参考书目里,读者可以深入学习。书中的练习章节是用来测试读者对理论知识的掌握程度的。作为对教学包的补充,列出了一些在线资源供读者网上学习。
2. 网络
复杂问题的有效解决方法就是“分而治之”。为了理解的目的,可以把复杂系统分解成一些简单的元素。同样,简单的元素也可集成为复杂系统[Bar Yam, 1997]。网络就是一种可以达到这种目的的方法。虽然网络的类型成千上万,但网络的基本元素是固定的:一系列的结点和连接结点之间的线。
这些点可以看做是运算单元。它们接受输入、处理输入、获得输出。有些处理过程可能就像计算输入总和这么简单,也有些可能会复杂一点,比如一个结点可能嵌入了另一个网络。
结点之间的连线决定了结点之间的信息流动。它们可能是单向的,连线的两个结点只能单向流动,也有可能是双向的,连线上的两个结点是相互流动的。
各结点通过连线相互交互产生了全局网络行为,这种行为只通过网络的基本元素是不可能观察到的,称这全局行为是“新显”。也就是说,紧随着网络元素而来的网络能力使网络成为了一个强大有效的工具。
物理学、计算机科学、生物化学、行为学、数学、社会学、经济学、电信和许多别的领域网络已经被应用于建立基于各自领域的模型。这是因为许多系统本身就可以看做是一个网络,比如:蛋白质、计算机、通讯等等。想想还有哪些别的系统也可以看做网络?为什么?
3. 人工神经网络
有一种类型网络把各个结点看做是“人工神经元”,这种网络就叫做“人工神经网络”(Artificial Neural Networks)。人工神经元就是受自然神经元静息和动作电位的产生机制启发而建立的一个运算模型。神经元通过位于细胞膜或树突上的突触接受信号。当接受到的信号足够大时(超过某个门限值),神经元被激活然后通过轴突发射信号,发射的信号也许被另一个突触接受,并且可能激活别的神经元。

人工神经元模型已经把自然神经元的复杂性进行了高度抽象的符号性概括。神经元模型基本上包括多个输入(类似突触),这些输入分别被不同的权值相乘(收到的信号强度不同),然后被一个数学函数用来计算决定是否激发神经元。还有一个函数(也许是不变,就是复制)计算人工神经元的输出(有时依赖于某个门限)。人工神经网络把这些人工神经元融合一起用于处理信息。
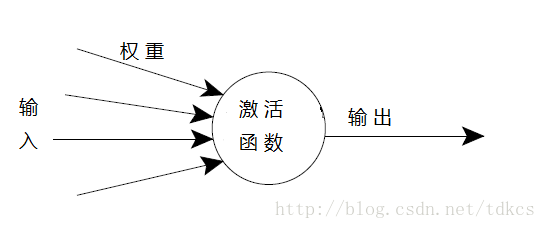
权值越大表示输入的信号对神经元影响越大。权值可以为负值,意味着输入信号收到了抑制。权值不同那么神经元的计算也不同。通过调整权值可以得到固定输入下需要的输出值。但是当ANN是由成百上千的神经元组成时,手工计算这些权值会变得异常复杂。这时就需要一些算法技巧。调整权重的过程称为“学习”或者“训练”。
ANN的类型和使用方式也有很多种。从McCulloch和Pitts(1943)建立第一个神经元模型起,已经产生了几百个不同的也被称为ANN的模型。这些模型之间的不同 也许是功能不同、也许是接受值和拓扑结构不同、也许是学习算法不同等等。同时也有一些混合模型,这些模型里的神经元有更多在上文中没有提到的属性。由于文章篇幅的原因,我们只讲解使用后向传播算法学习的ANN(Rumelhart and McClelland,1986)来学习合适的权值,这种ANN是所有ANNs里最通用的模型,并且许多模型都是基于它的。
由于ANNs是用来处理信息的,自然它被应用在与信息相关的领域。有许多的ANNs就是对真实神经元网络进行建模,用来研究动物和机器的行为与控制,但是也有许多是用于工程的,比如:模式识别、预测、数据压缩。
3.1 练习
这个练习的目的是熟悉人工神经网络的概念。建立一个包含四个人工神经元的网络。在网络中两个充当接受信号的输入端,另外两个充当发射信号的输出端。
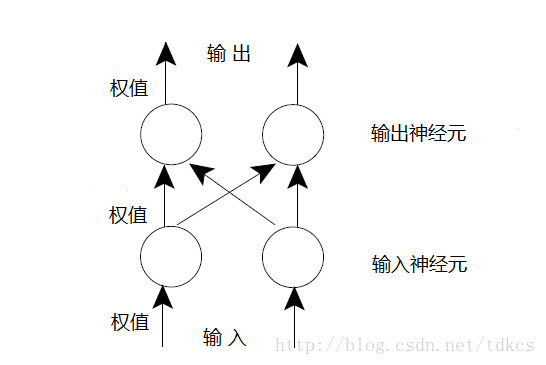
每一个箭头都有一个权值代表信息流的强度,这些值和通过箭头的信号值相乘表示对信号的增强和衰减,这个网络上的神经元只是简单的把所有输入到该神经元的信号求和。由于这里的输入神经元上只有一个输入值,因此这个神经元的输出也只是输入的权值与输入的信号相乘的结果。如果权值是负值会发生什么?如果是零呢?
处于输出层的每个神经元都接受到了来至输入层神经元的输出信号,这些输出层神经元把收到的信号乘以各自的权值再求和作为自身的输出。输出信号再被权值相乘作为整个网络的输出。
现在把这些权值全都置为1,意味着信息流上的信号不会收到影响。请分别计算在下列不同输入的条件下网络的输出是什么?输入值:(1,1),(1,0),(0,1),(0,0),(-1,1),(-1,-1)。
很好,现在在(0.5,0,-0.5)中选择权值并且随机放在网络的任意权值处。输入值和上面的一样,请计算输出值。改变一些权值,看看网络的行为发生了怎样的变化。哪些权值具有举足轻重的作用(也就是说改变这个权重值,网络的输出会发生较大变化)?
现在假如我们需要这样的一个网络,它可以把输入值的顺序进行调换(例如(0.3,0.7)->(0.7,0.3))。试一下怎么设置权值?
这很简单的。还有一个简单的网络只是把输入加倍输出。你也可以试一试。
现在,给神经元设置门限值。神经元之前的输出值如果大于神经元的门限值,这个神经元的输出值就为1,否则为0。对现存的网络设置门限,看看这些网络的行为发生了什么改变。
现在,假设我们有这样的网络,输入层神经元只接受0和1。调整权值和门限使网络的第一个输出值是网络输入的“逻辑与”运算(输入值都为1时输出值才为1,否则为0),使网络第二个输出的值是网络输出的“逻辑或”运算(输入值都为0时输出值才为0,否则为1)。你会发现满足此种要求的网络不止一种。
现在,虽然调整这么小的网络的权值轻而易举,但是这个网络具有的能力也是渺小的。如果我们需要一个包含上百个神经元的网络,为得到需要的输出值你怎么调整这些权值?有许多种方法可以使用,我们将探索最通用的一种。
4. 后向传播算法
后向传播算法(Rumelhart and McClelland,1986)是应用在分层前馈式ANN上的一种算法。这就意味着人工神经元是根据不同层次来组织划分的,并且是通过前向方式发送信号的,然后把错误率通过反馈方式传播给后向上的神经元。网络通过位于输入层(input layer)的神经元收集输入信号,网络的输出值是通过位于输出层(output)的神经元给出的。可能存在一层或者多层的中间隐藏层(hidden layers)。后向传播算法使用监督学习,也就是说我们给这个算法提供了输入值和本来想让计算的输出值,然后计算出误差(真实值和计算值之间的误差)。后向传播算法的思想就在于学习完训练样本后误差要尽量的小。训练是以权值为任意值开始的,目的就是不停的调整权值,使误差最小。
实现后向传播算法的ANN里的神经元的激发函数是加权和(输入的 xi 与各自的权值 wji 相乘后的和):
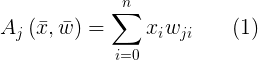
可以看出激活函数只与输入值和权值有关
如果输出函数不变(输出等于激活函数),称神经元是线性的。但是这有严重的局限性。最通用的输出函数是S型函数:
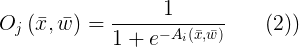
S型函数是这样的函数:对于大的正数变量,函数的值渐渐趋近与1,对于大的负数变量,函数的值渐渐趋于0,在零点,函数的值为0.5。这就给神经元输出的高低值有一个平稳的过度(接近于1或接近于0)。我们发现输出只和激活函数有关,而激活函数又与输入值和对应的权值有关。
现在,训练的目标就变成了给定输入值得到希望的输出值。既然误差是真实输出值与希望输出值的差值,并且误差依赖于权值,我们需要调整权值来最小化误差。我们可以为每个神经元的输出定义一个误差函数:

我们把输出值与希望值的差做了平方,这样可以保证误差值都为正,因为差别越大误差值也越大,差别越小误差值也越小。网络的误差值就是简单的把所有在输出层上神经元的误差求和:

后向传播算法现在计算误差是怎么随着输出值、输入值和权重而变化的。我们理解了这些,就可以通过梯度下降法来调整权值了:
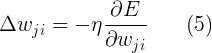
上面的公式可以按照下面的思路来理解:每个调整的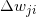 值将会根据上次调整后权重与网络误差的依赖程度进行调整,这种依赖程度是 E 关于 wi 的导数。每次调整的步长还依赖于
值将会根据上次调整后权重与网络误差的依赖程度进行调整,这种依赖程度是 E 关于 wi 的导数。每次调整的步长还依赖于 。也就是说对误差影响大的权值相比于影响小的,每次调整的值也比较大。公式(5)循环计算直到找到满意的权值才停止(误差很小了)。如果你对导数不理解,没关系,你可以把它看着一个函数,并且在下文我将立即用线性代数来代替。如果你理解了,请自己写出来然后和我这儿的做个比较。如果你还想详细的理解关于后向传播算法的推导过程,你可以根据我后面的推荐书籍进行查找,毕竟这已经超出了这份材料的范围。
。也就是说对误差影响大的权值相比于影响小的,每次调整的值也比较大。公式(5)循环计算直到找到满意的权值才停止(误差很小了)。如果你对导数不理解,没关系,你可以把它看着一个函数,并且在下文我将立即用线性代数来代替。如果你理解了,请自己写出来然后和我这儿的做个比较。如果你还想详细的理解关于后向传播算法的推导过程,你可以根据我后面的推荐书籍进行查找,毕竟这已经超出了这份材料的范围。
所以,我们只须求得 E 关于 wji 的导数。这就是后向传播算法的目标,我们需要得到这个反馈。首先,我们需要计算输出值是怎么影响误差的,它是 E 关于 Oj 的导数(来自公式(3))。
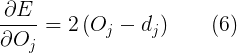
然后计算激活函数是怎么影响输出的,其次是权值怎么影响激活函数的(来自公式(1)和(2)):
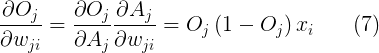
继续推导(来自公式(6)和(7)):
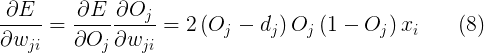
因此,对于每个权值做如下调整(来自公式(5)和(8)):

我们可以使用公式(9)来训练含有两层的ANN。现在我们想训练再多一层的网络还要考虑许多。如果我们想调整前面一层的权重(我们把它记为 υik)。我们首先需要计算误差是怎么依赖于来自上层的输入的,而和权值无关。这很简单,我们只须把公式(7),(8),(9)里的 xi 用 wji 代替。但是也需要知道网路的误差是怎么随 υik而变化的。因此:
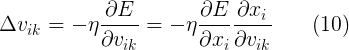
这里:

另外,假设有输入值为 υk、权重为 υik 的信号进入神经元(来自公式(7)):
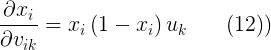
如果我们还想增加一层,用同样的方法计算误差是怎么随第一层的输入和权值而变化的。我们只须对这些牵引稍加注意,毕竟每层的神经元个数是不一样的,不能混淆。
对于实践推理来说,实现后向传播算法的ANNs不能有太多的层,因为花在计算上的时间是随层数指数级别上升的。同时,还有许多具有更快学习速度的改进算法。
4.1 练习
如果你懂得编程,实现这个后向传播算法,至少能用来训练下面的网络。要是你能实现后向传播的通用算法(随意几层、每层有任意个神经元、任意个训练序列),好好干吧。
如果你还不懂得编程,但是知道运用一些辅助工具(比如Matlab或者Mathematica),那么应用里面定义好的函数找到下面网络的合适的权值吧,这些函数能让你的工作变得轻松一点。
再如果你一点电脑经验都没有的话,还是通过手一步一步的算吧。
这里的网络在输入层有三个神经元,隐藏层有两个,输出层有三个。一般情况下训练序列是很大的,但在这个练习里,我们只用一个训练序列。当输入为(1,0.25,-0.5)时,输出应该为(1,-1,0)。记住,你应该以随机的权值开始训练。
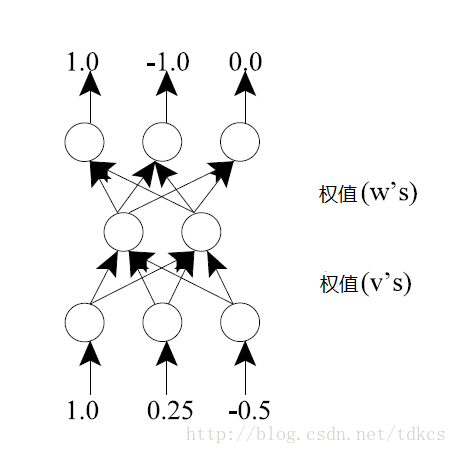
5. 进一步阅读
以下都是深入理解ANNs的大作:
Rojas, R. (1966). Neural Networks: A systematical Introduction. Springer, Berlin.
Rumelhart, D. and J. McClelland (1986). Parallel Distributed Processing. MIT Press, Cambridge, Mass.
关于网络方面的进一步资料和相关主题,这些书很有帮助且图文并茂:
Bar-Yam, Y. (1997). Dynamics of Complex Systems,Addison-Wesley.
Kauffman, S. (1993). Origins of Order, Oxford University Press.
6. 在线资源
网络上有大量的关于神经网络的资源。EPFL基于Java applets开发的卓越案例和指导手册。别的两个教程是Universidad Politécnica de Madrid和伦敦科学、技术、医学的帝国理工学院。另外作者自己一些关于神经网络编程方面的Java代码。
7. 参考书目
Bar-Yam, Y. (1997). Dynamics of Complex Systems. Addison-Wesley.
Kauffman, S. (1993). Origins of Order, Oxford University Press.
McCulloch, W. and W. Pitts (1943). A Logical Calculus of the Ideas Immanent in Nervous Activity.Bulletin of Mathematical Biophysics, Vol. 5, pp. 115-133.
Rojas, R. (1996). Neural Networks: A Systematic Introduction. Springer, Berlin.
Rumelhart, D. and J. McClelland (1986). Parallel Distributed Processing. MIT Press, Cambridge,
Mass.Young, D.Formal Computational Skills Course Notes.
本文转自:CSDN,转载此文目的在于传递更多信息,版权归原作者所有。
原文:https://blog.csdn.net/yu132563/article/details/80484324



