机器学习(深度学习)跟编程范式以及处理的数据等方面根传统的编程有较大不同,需要学习或准备转型做这个领域的需要引起足够的关注。
1、编程范式
在经典的程序设计(即符号主义人工智能的范式)中,人们输入的是规则(即程序)和需要根据这些规则进行处理的数据,系统输出的是答案 (见下图)。
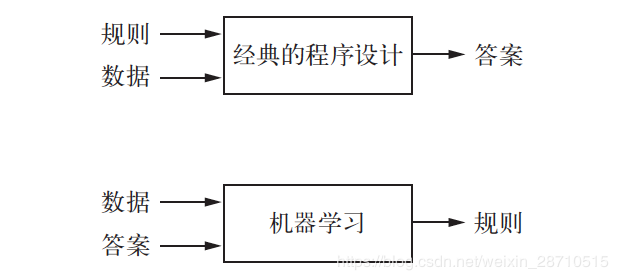
利用机器学习,人们输入的是数据和从这些数据中预期得到的答案,系统输出的是规则或者叫模型。这些规则随后可应用于新的数据,并使计算机自主生成答案。
机器学习系统是训练出来的,而不是明确地用程序编写出来的。将与某个任务相关的许多示例输入机器学习系统,它会在这些示例中找到统计结构,从而最终找到规则将任务自动化。这一点与人类思考类似,看下图人类解决问题的思路:
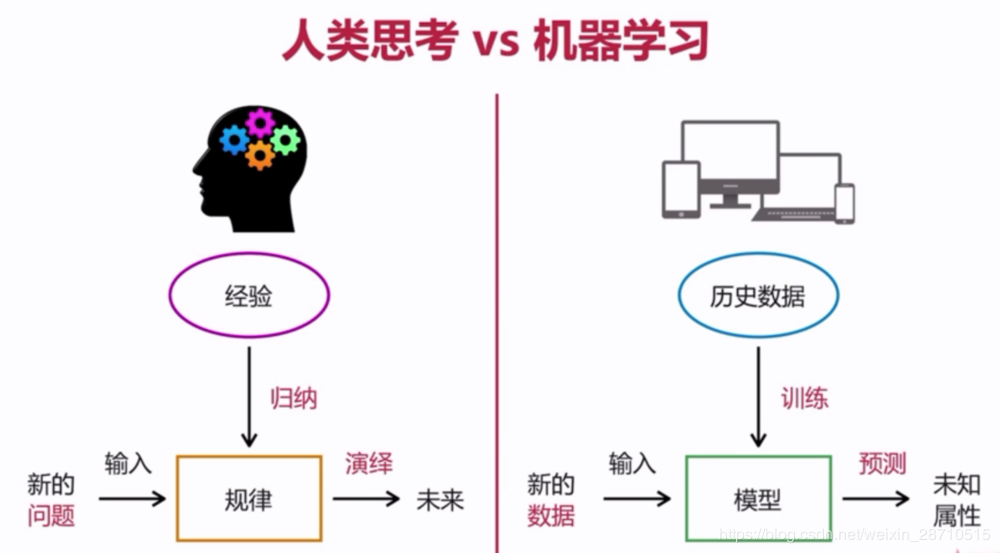
可以看出,机器学习处理的是数据,通过学习输入的数据,从而建立模型,以便预测新的数据都输出。
2、数据
在处理的数据方面,传统的编程处理的数据往往都是简单的数据或存在数据库里的关系型数据,经常的操作是对数据的增删改查(CRUD)操作,而机器学习(深度学习)处理的数据一般都是很大的数据,经常把它叫做数据集,为了高效处理这些数据,我们需要用到向量、矩阵或多维数组来存储和表达。这也是准备学习或转型到向量的同仁需要注意的,所以,你需要了解、熟悉并习惯使用多维数组来进行数据存储、变换。这里列举一下,你可能会遇到的几类数据集:
① 向量数据:2D张量,形状为 (samples, features)。这是最常见的数据,对于这种数据集,每个数据点都被编码为一个向量,因此一个数据批量就被编码为2维张量(即向量组成的数组,即矩阵),其中第一个轴是样本轴,第二个轴是特征轴。例如在手写数字识别的例子中,一副28乘28像素的图片,展成一个向量就是一个784个像素的向量,如果有10000副这样的图片,就可以使用一个形状为(10000,784)的二维张量来表达。
② 时间序列数据或序列数据:3D张量,形状为(samples, timesteps, features)。当时间(或序列顺序)对于数据很重要时,应该将数据存储在带有时间轴的3D张量中。每个样本可以被编码为一个向量序列(即2D张量),因此一个数据批量就被编码为一个3D张量。例如,股票价格数据集,每一分钟,我们将股票的当前价格、前一分钟的最高价格和前一分钟的最低价格保存下来,因此每分钟被编码为一个3D向量,整个交易日被编码为一个形状为(390, 3) 的2D张量(一个交易日有390 分钟),而250天的数据则可以保存在一个形状为(250, 390,3) 的3D张量中。这里每个样本是一天的股票数据。

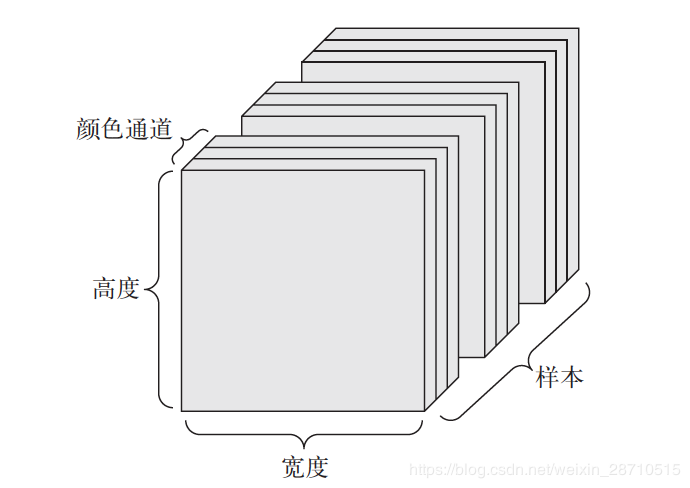
③ 图像:4D张量,形状为(samples, height, width, channels)或(samples, channels,height, width)。图像通常具有三个维度:高度、宽度和颜色深度。虽然灰度图像(比如MNIST 数字图像)只有一个颜色通道,因此可以保存在2D 张量中,但按照惯例,图像张量始终都是3D 张量,灰度图像的彩色通道只有一维。因此,如果图像大小为256×256,那么128 张灰度图像组成的批量可以保存在一个形状为(128, 256, 256, 1) 的张量中,而128 张彩色图像组成的批量则可以保存在一个形状为(128, 256, 256, 3) 的张量中。
④ 视频:5D张量,形状为(samples, frames, height, width, channels)或(samples,frames, channels, height, width)。视频数据是现实生活中需要用到5D张量的少数数据类型之一。视频可以看作一系列帧,每一帧都是一张彩色图像。由于每一帧都可以保存在一个形状为(height, width, color_depth) 的3D张量中,因此一系列帧可以保存在一个形状为(frames, height, width,color_depth) 的4D张量中,而不同视频组成的批量则可以保存在一个5D 张量中,其形状为(samples, frames, height, width, color_depth)。
读到这里可能有的同学会觉得有点晕了,就像一个习惯了舞枪弄棒的人,现在教你改用机枪和大炮,从使用冷兵器到使用热兵器,不习惯是必然的,但是学习曲线就是这样的陡!而你必须习惯,否则学习机器学习(深度学习)会比较吃力。
总之,一句话,机器学习(深度学习)大多数情况下处理的是多维数据,不管具体是几维。
3、工程性强
深度学习在理论上无法证明它为何有效,但是在实际问题上它的确有效,没有形成系统的理论。比如,各个深度学习模型为什么好用?原理本质是什么?各个模型都适用于什么场合?针对特定数据,特定问题,如何组合搭建模型,各个参数怎么选?如何根据特定模型,特定数据来训练模型?所以,机器学习(深度学习)领域工程性强,或者说实践性强。由于这一领域是靠实验结果而不是理论指导的,所以只有当合适的数据和硬件可用于尝试新想法时(或者将旧想法的规模扩大,事实往往也是如此),才可能出现算法上的改进。机器学习不是数学或物理学,靠一支笔和一张纸就能实现重大进展,这或许是人工智能一路曲折发展的一个因素。它是一门工程科学。
4、再谈维度
维度这个词语我们经常听到,在物理学上,认为我们生活的空间是个3维空间,加上时间,大家认为就是4维;但是在数学领域,可以由3维上升到N维空间,数学上的理解有所不同,有兴趣的可以查看2008年欧洲数学界的一个关于维度的专业讲解;在意识领域,也可以有多维的概念,在梁冬采访北大教授刘丰的视频中,刘丰讲到了生命的意义在于提升意识的维度,并说上升到4维就是宗教,而且说人类的智慧往往来自直觉,而直觉往往来自高维度的信息,有兴趣的可以参考这里。人工智能处理的数据,从数学上讲就是高纬度的数据,是否人类在人工智能的努力方向正在解开高纬度的秘密?高维度是否打开了通往智慧、通往上帝之门?这里只是做点延展。
以上就是学习机器学习(深度学习)需要注意的几点,供大家参考和讨论。
版权声明:本文为CSDN博主「穿越文明」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_28710515/article/details/89132804





