一、深度与模块化
对于一个分类的问题的简化,我们可以先训练一个Basic classfier,然后将其共享给following classfier,通过多层的分类器进行特征的提取,用较少的数据就可以训练好网络。而在deep的模型当中,Basic classfier是由神经网络自己学到的,然后通过更多层的网络可以使得classfier逐渐学到更加深层次的特征。这就是deep network能够work的原因。
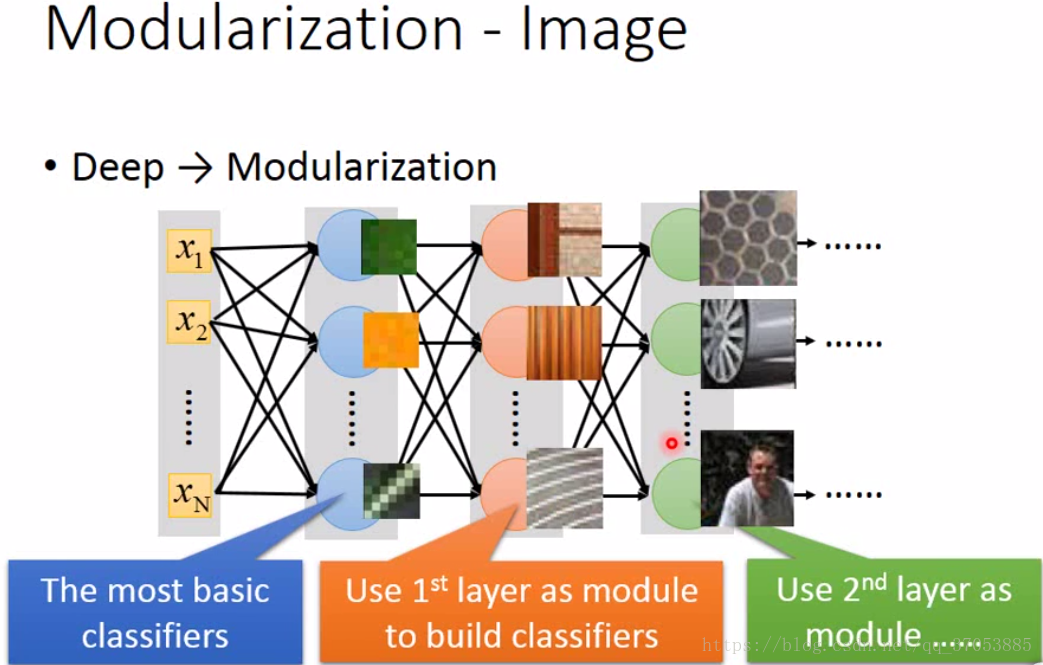
二、模块化与语音识别
语音识别的大致步骤:
①将声音信号的特征转化为状态信息(即对应标签)。
②将状态转化成音素
③将音素转化成为文字
④考虑同音异字的问题
传统方法:
HMM-GMM,每一个音素都有自己独立的分布,找出所有音素的分布,然后根据条件概率求出所给的数据属于哪一个音素。
DNN:
所有的状态都共用一个DNN。训练时DNN会根据训练数据来学习人所发出的声音时的舌头位置,然后根据不同的舌头位置将发出声音映射到不同的特征空间从而达到分类的目的。
相比于传统的语音识别方法,DNN可以利用同一组的检测器来识别不同的语音,做到了模块化,使得参数的使用更加有效率。
Universality Theorem指出:对于所有的函数 f : RN→RM 都可以用只有一个隐藏层的神经网络来实现,只要隐藏单元的个数足够。虽然浅层的神经网络可以拟合任何的函数,但是采用深层的结构可以提高模型的效率,因为深度的网络可以表征更加复杂的特征空间(保证浅层与深层的网络具有同样数量的参数),即可以通过相对较少的参数便可以实现浅层神经网络的功能。可以类比电路中的多层门电路可以利用较少的门来实现一层门电路的功能。也可以类比剪窗花的过程,通过对折我们可以把特征空间进行对折,通过较少的几剪(数据)便可以剪出复杂的形状。
三、端到端的学习
通过一个较为复杂的function将多个simple function组合在一起,端到端的网络可以自动地学习到每一个simple function应该完成的任务。
在传统的语音识别的过程中需要大量的手工提取工作,流程如下图所示:
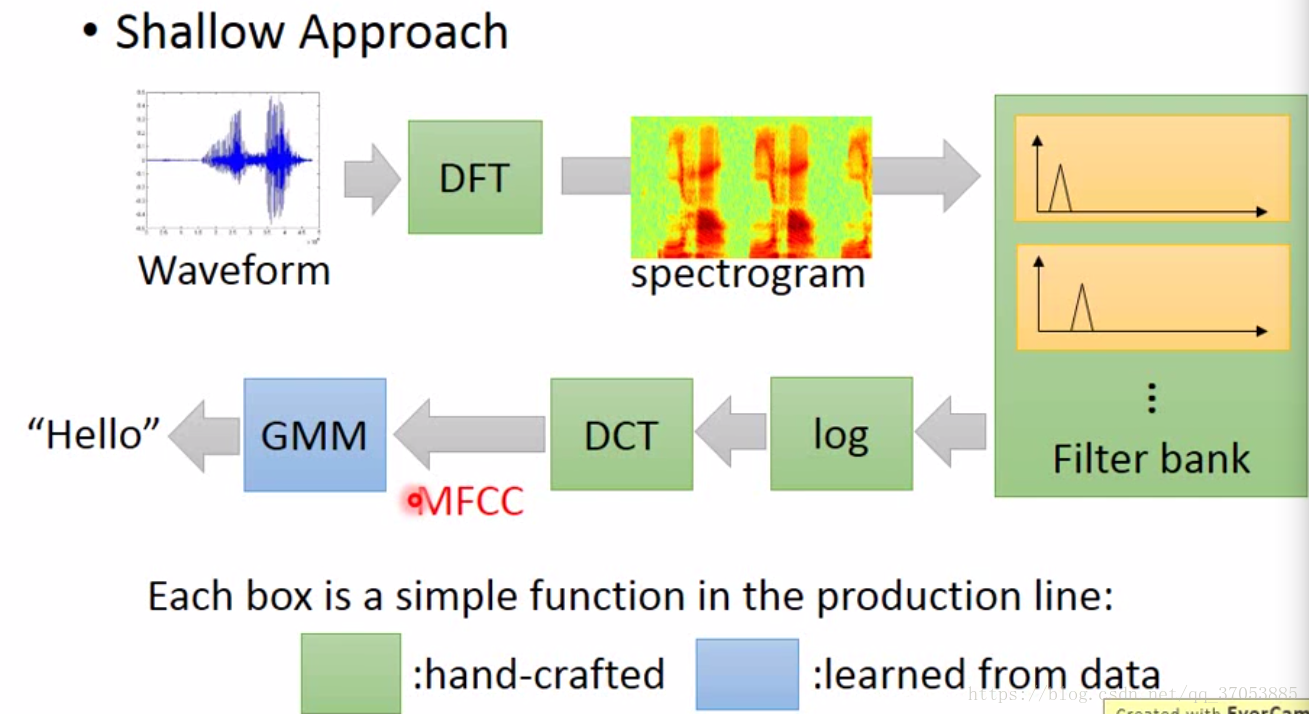
图片中只有GMM是需要通过训练数据进行训练的,其余均为根据先验的经验来进行设计。
而在深度学习中的语音识别的架构如下图所示:
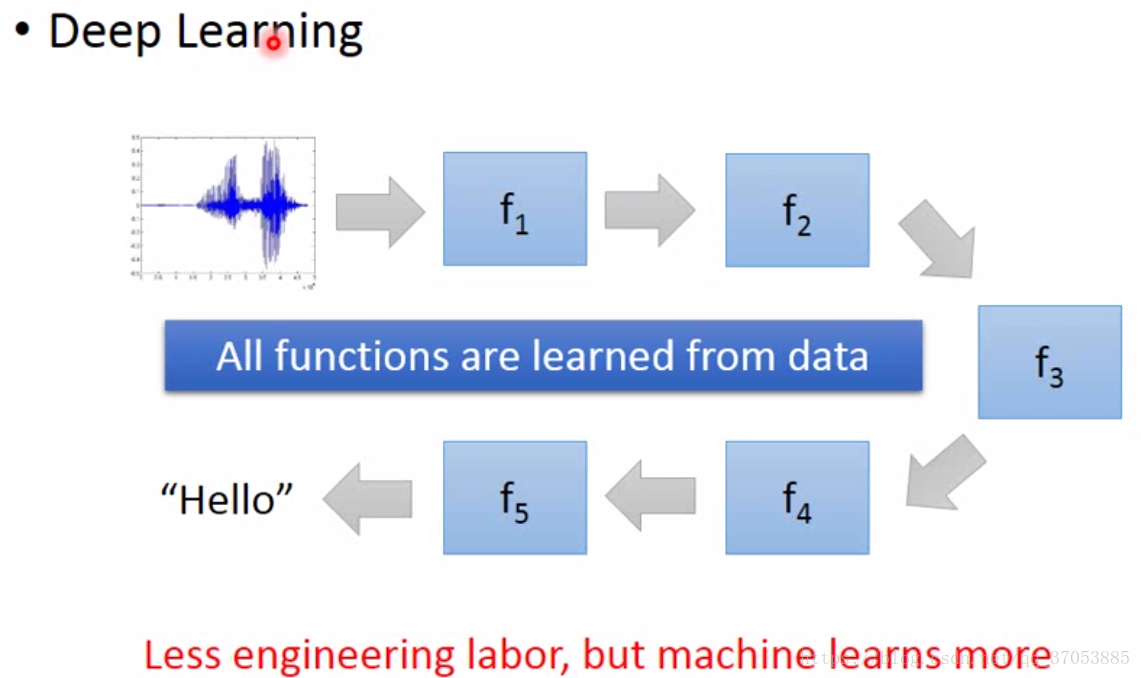
每个函数都可以通过数据来进行训练,学习到函数中的参数。在图像识别中,端到端相对于传统方法的优势与语音识别类似。
四、深度可以完成复杂的任务
①处理相似的输入,但不同的输出问题

②处理不同的输入,但相似的输出问题

深度学习可以通过多个layer的转换学习更高维度的特征来解决更加复杂的任务。
版权声明:本文为CSDN博主「SaulZhang98」的原创文章,遵循CC 4.0 by-sa版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_37053885/article/details/81628478





