先综述下,神经网络做分类等问题的核心原理是使用升维/降维、 放大/缩小、旋转、平移、弯曲这5大类操作完成扭曲变换,最终能在扭曲后的空间找到轻松找到一个超平面分割空间。
接下来介绍的内容有:
① 神经网络每层都在做什么
② 神经网络如何完成识别任务
③ 从物质组成角度理解
神经网络每层都在做什么
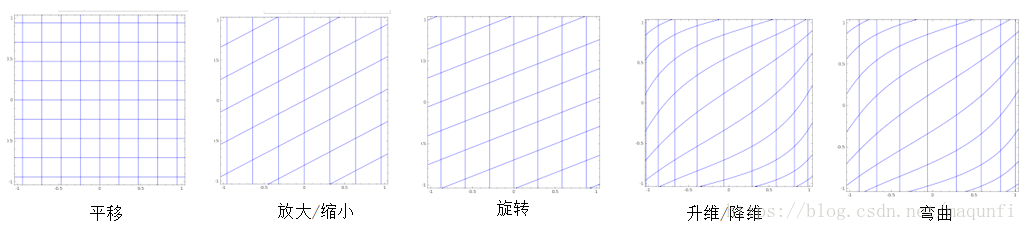
*数学式子: 网络中的每层核心的计算过程是: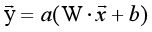 ,即对上次输入x向量进行计算得到输出向量y
,即对上次输入x向量进行计算得到输出向量y
*数学理解:上面的运算相当于对输入空间进行了以下5中操作的转换,完成了从输入空间到输出空间的变换过程。
用线性变换跟随着非线性变化a,将输入空间投向另一个空间。
*从物质世界角度理解: 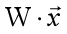 相当于组合成新物质的过程,每层神经网络相当于通过现有的不同物质的组合形成新物质。 下面举个例子,假设输入的元素
相当于组合成新物质的过程,每层神经网络相当于通过现有的不同物质的组合形成新物质。 下面举个例子,假设输入的元素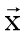 为[C元素,O元素],此时可以通过乘不同的权值矩W得到不同的组成物质:
为[C元素,O元素],此时可以通过乘不同的权值矩W得到不同的组成物质:


如果再加一层,就是通过组合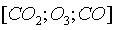 这三种基础物质,形成若干更高层的物质
这三种基础物质,形成若干更高层的物质
神经网络如何完成识别任务
*在一维空间上,以分类为例子(回归怎么搞的?),假设我们要分为正数、负数、零三类,一维空间的直线可以找到两个超平面(对应的是点)分割这三类。

对于分类奇数和偶数这类问题,会将空间使用式子进行x % 2变换,在另一空间中能找到超平面进行分离。
*在二维空间中,假设如图左的二分类问题,我们发现很难在二维空间中找到超平面进行红蓝线的分类分离,此时,神经网络是会使用类似SVM的方式,进行5种空间变换操作,比如转化到三维空间中,能找到超平面进行分类

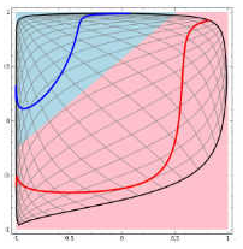
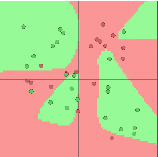
[1]举例1,使用ConvnetJS demo工具,对于分类问题,使用一层隐层情况下,分类效果为中图,空间扭曲效果为右图。
使用单隐层效果为:

双隐层下效果:
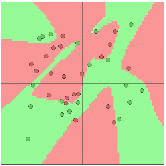
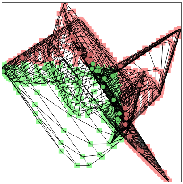
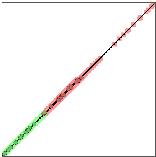
例子网址:http://cs.stanford.edu/people/karpathy/convnetjs//demo/classify2d.html
*从线性可分视角理解上面过程:
[1]神经网络的学习就是学习如何利用矩阵的线性变换加激活函数的非线性变换,将原始输入空间投向线性可分/稀疏的空间去分类/回归。
[2]增加节点数:增加维度,即增加线性转换能力。
[3]增加层数:增加激活函数的次数,即增加非线性转换次数。 多分类中获取的softmax输出实际上是获取特征组合 偏向于扭曲空间中哪个部分的分值(n个softmax输出会在扭曲面中用n-1个超平面进行切分)

从物质组成角度理解
*神经网络的学习过程可以看做学习物质组成方式的过程。是一种由简单原子不断组成到复杂抽象个体的过程,即模仿人类组织结构过程为:
DNA->细胞->组织->器官->完整的人
*比较直观的理解是在人脸识别过程中,可以模拟这种思想并应用在画面识别上。由像素组成菱角再组成五官最后到不同的人脸。每一层代表不同的不同的物质层面 (如分子层)。而每层的W存储着如何组合上一层的物质从而形成新物质。
如下图所示,浅层的图像分析的是边缘特征,越往则是复杂组合特征,不断增加的层数,能使得网络理解更加抽象的概念。

来源:CSDN,作者:马飞飞,转载此文目的在于传递更多信息,版权归原作者所有。
原文:https://blog.csdn.net/maqunfi/article/details/82634560
版权声明:本文为博主原创文章,转载请附上博文链接!





