这篇文章介绍深度学习四种主流的规范化, 分别是Batch Normalization(BN[9]), Layer Normalization(LN[7]), Instance Normalization(IN[8])以及Group Normalization(GN[2])。
1. 作用
为啥用Normalization? 这是因为训练深度神经网络会收敛很慢,很有可能发生梯度弥散或者梯度爆炸。用了Normalization可以训练得很快,学习更好。
2. 做法
给定输入x,Normalization的处理方式可以由下面这个公式形容,不过各种Normalization对x的期望以及方差的求法不同。这个公式可以分两个部分,第一个部分是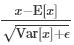 是对activation进行规范化操作,将activation变为均值为0,方差为1的正态分布,而最后的“scale and shift”(γ,β)操作则是为了让因训练所需而“刻意”加入的规范化能够有可能还原最初的输入, 保证模型的能力。[1]
是对activation进行规范化操作,将activation变为均值为0,方差为1的正态分布,而最后的“scale and shift”(γ,β)操作则是为了让因训练所需而“刻意”加入的规范化能够有可能还原最初的输入, 保证模型的能力。[1]
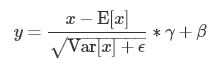
下面这张图[2]很直观地解释了各种Normalization处理张量的不同之处。
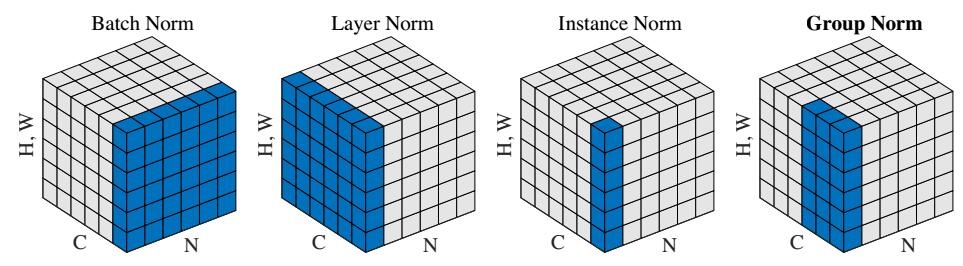
给定一个四维张量x,四维依次代表[batchsize,channel,height,width], 简单起见,表示为(N,C,H,W),上图中,张量的第三个维度以及第四个维度合起来组成了一个维度,方便展示。
BN:可以看到BN是以C为滑动轴,对BHW三个维度求和取平均,所以期望的维度是(1,C,1,1),然后利用期望求出方差。
LN: LN与BN刚好是垂直的位置,是以B为滑动轴,对CHW三个维度求和取平均,期望的维度是(N,1,1,1)。
IN: IN则是LN和BN的交汇,以B和C双轴滑动,对HW两个维度求和取平均,期望的维度是(N,C,1,1)。
GN: GN则是IN和LN的一种折中考虑,对C维度进行了分组,上图中是分成了两组,所以最后期望的维度是(N,2,1,1)。
3. 原理与使用
深度神经网络中的Normalization最先是出现在AlexNet网络中的LRN(local response normalization), 而LRN计算的是像素局部的统计量,对加速收敛没有什么作用。开山加速收敛的Normalization方法是BN,那么它是怎么加速收敛的呢?首先要弄清楚为什么没有BN,收敛会慢,对于一个深层网络来说,会发生梯度弥散, 这样在反向传播更新梯度时,会更新得非常慢,收敛也会变得慢,而BN将原来要变小的activation通过规范化操作,使activation的尺度变大,这样就消除了梯度弥散而导致参数更新慢的影响。
BN训练阶段与测试阶段:训练阶段的期望和方差通过当前批数据进行计算,γ和β则是BN层的可学习参数,由于BN层会减去期望,所以前一层是没必要加上偏置的。在测试阶段,一般是单例forward,对单例求期望和方差是无意义的,所以BN的测试阶段的期望和方差是训练时每个批次的期望和方差的累计移动平均或者指数移动平均求得的[3][4][6],找了一个简单的BN训练实现,详细见[6]。
import numpy as np
def Batchnorm(x, gamma, beta, bn_param, momentum=0.1):
# x_shape:[B, C, H, W]
running_mean = bn_param['running_mean']
running_var = bn_param['running_var']
results = 0.
eps = 1e-5
x_mean = np.mean(x, axis=(0, 2, 3), keepdims=True)
x_var = np.var(x, axis=(0, 2, 3), keepdims=True)
x_normalized = (x - x_mean) / np.sqrt(x_var + eps)
results = gamma * x_normalized + beta
# 因为在测试时是单个图片测试,这里保留训练时的均值和方差,用在后面测试时用
running_mean = momentum * running_mean + (1 - momentum) * x_mean
running_var = momentum * running_var + (1 - momentum) * x_var
bn_param['running_mean'] = running_mean
bn_param['running_var'] = running_var
return results, bn_param从BN的训练阶段中知道,BN严重依赖批数据,通过批数据的统计信息来近似估计全局的统计信息,而在测试阶段,没有进行统计信息的计算,而是通过训练阶段的统计信息来估计新数据,当新数据来自未知的domain(风格迁移将每张图片当作一个domain,图像的生成结果主要依赖于某个图像实例,BN统计的近似全局信息并不会给任务带来收益,反而会弱化实例之间的特殊性[5]),训练的统计信息就用处不那么大了,另外大网络的大batchsize很占用GPU显存,对于缺少多GPU的人来说,这是不好办的,而减小batchsize会使计算的期望与方差不能代表整体分布,网络性能就会大大折扣。
为了消除batch的影响,LN,IN,GN就出现了。这三个规范化操作均对于batch都是不敏感的。
- BN是针对不同神经元层计算期望和方差,同一个batch有相同的期望和方差。
- LN是针对同层神经元计算期望和方差,不同样本有不同的期望和方差。
- IN是不同样本的不同神经元层有不同的期望和方差。
- GN是不同样本不同分组有不同的期望和方差。
这也导致了它们的用途不同。BN统计的是数据的整体分布,判别模型的结果主要取决于数据的整体分布,所以BN经常用于固定深度的DNN,CNN中。
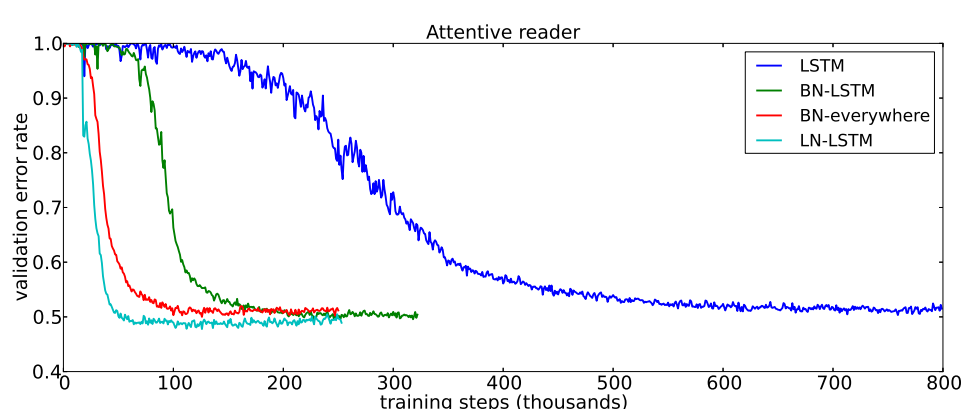
对于RNN来说,序列的长度是不一致的,也就是深度不固定,不同时间保存的统计信息不同,这对于固定批次的BN是计算很麻烦的。而LN与输入序列的长度是没有关系的,因此LN在RNN中效果明显,但在cnn中不如BN。如下图所示[7],LSTM+LN更快收敛,学习得更好。
在图像风格化任务中,生成结果主要依赖于单个图像实例,所以这类任务用BN并不合适,但可以对HW做规范化,可以加速模型收敛[6][8]。
GN根据传统的特征提取器组合特征的思路(例如HOG根据orientation分组),对channel进行分组,每一层的都有很多卷积核,被核学习到的特征不是完全独立的,有的特征可能属于频率,还有的属于形状,亮度等等,因此对特征进行分组处理是自然的思路,最后的结果也很好,与BN的效果相差无几,但对batch是无依赖的,适合小批量任务[2]。
下图是BN与GN的对比效果。

具体使用参考见pytorch官方文档
参考
[1] 魏秀参的回答
[2] GNpaper
[3] YJango的BN文章
[4] BatchNorm源码
[5] Naiyang Wang的回答
[6] liuxiao的博客
[7] LNpaper
[8] INpaper
[9] BNpaper
本文转自:博客园 - 放羊的水瓶(FANG_YANG),转载此文目的在于传递更多信息,版权归原作者所有。





