【导读】数据科学家是“比任何软件工程师都更擅长统计数据的人,而且比任何统计学家都更擅长软件工程”。在这里,我们讨论程序员如何成为更好的统计学家。
不完全理解目标函数
数据科学家希望建立“最佳”模型。如果不知道目标和目标函数是什么以及它的作用,那么您就不可能构建“最佳”模型。而且,目标甚至可能不是数学函数,但可能会改进评价指标。
解决方案:大多数讨人喜欢的人都花费大量时间来理解目标函数以及数据和模型与目标函数的关系。如果要优化性能,请将其映射到适当的数学目标函数。
示例:F1分数通常用于评估分类模型。我们曾经建立了一个分类模型,其成功取决于它正确预测的百分比。 F1得分具有误导性,因为它显示模型是60%的时间的时间正确的,而事实上它只有40%的时间是正确的。
f1 0.571 accuracy 0.4
没有假设为什么某些东西应该起作用
通常数据科学家希望建立“模型”。 他们听说xgboost和随机森林效果最好所以让我们使用它们。 他们阅读了深度学习,也许这将进一步改善成果。 他们在没有查看数据的情况下抛出问题的模型,并且没有形成一个假设,哪个模型最有可能最好地捕获数据的特征。 它也很难解释你的工作,因为你只是随意地将模型投射到数据上。
解决方案:看看数据! 了解其特征并形成一个假设,该模型可能最好地捕捉这些特征。
示例:如果不通过绘制此样本数据来运行任何模型,则您已经可以看到x1与y线性相关且x2与y没有太大关系的强视图。
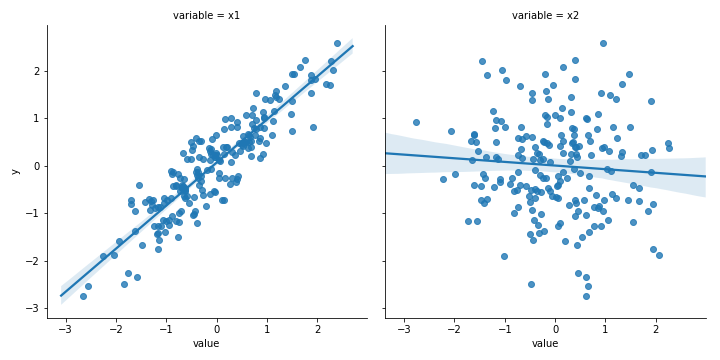
在解释结果之前不查看数据
不查看数据的另一个问题是,您的结果可能会受到异常值或其他工件的严重驱动。 对于最小化平方和的模型尤其如此。 即使没有异常值,您也可能会遇到不平衡数据集,剪切或缺失值以及您在课堂上没有看到的各种其他奇怪的现实数据工件的问题。
解决方案:重要的是它值得重复:查看数据! 了解数据的性质如何影响模型结果。
示例:对于异常值,x1斜率从0.906变为-0.375!

没有简单的基线模型
现代ML库几乎让模型变得简单......只需更改一行代码就可以运行新模型。 错误指标正在减少,调整参数 - 很棒 - 错误指标正在进一步降低......所有模型的优点,你可以忘记预测数据的愚蠢方式。 如果没有那种简单的基准,你对模型的好坏并没有很好的绝对比较,从绝对意义上说它们可能都是坏的。
解决方案:最愚蠢的预测方式是什么? 使用最后的已知值,均值或某个常数构建“模型”。将模型性能与零智能预测猴子进行比较!
示例:使用此时间序列数据集,model1必须优于model2,MSE分别为0.21和0.45。 可是等等! 只需取最后一个已知值,MSE就会下降到0.003!
ols CV mse 0.215 rf CV mse 0.428 last out-sample mse 0.003
错误的离群样本测试
模型在研发时看起来很好,但在生产中表现糟糕。 模型也许解决了大多数情况,但是,未解决的错误情况有时候是致命的。
解决方案:确保您在真实的过采样条件下运行模型,并了解它何时表现良好以及何时表现不佳。
示例:样本中的随机森林比线性回归好很多,其中mse为0.048 vs ols mse 0.183,但是样本越多,mse为0.259,线性回归为0.187。 随机森林过度训练,生产效果不佳!
in-sample rf mse 0.04 ols mse 0.183 out-sample rf mse 0.261 ols mse 0.187
错误的离群样本测试:将预处理应用于完整数据集
过度训练意味着它在训练样本中表现良好,但是测试样本很差。因此,您需要了解将训练数据泄漏到测试数据中。如果您不小心,无论何时进行特征工程或交叉验证,列车数据都会蔓延到测试数据中并使模型性能膨胀。
解决方案:确保您拥有真正的测试集,没有任何来自训练集的泄漏。特别要注意生产中可能出现的任何与时间有关的关系。
示例:这种情况有很多。将预处理应用于完整的数据集,意味着您没有真正的测试集。在将数据拆分为训练集和测试集之后,需要单独应用预处理,以使其成为真正的测试集。在这种情况下,两种方法之间的MSE(混合样本CV mse 0.187 vs真实样本CV mse 0.181)并不完全不同,因为列车和测试之间的分布特性没有那么不同,但可能并不总是如此案件。
mixed out-sample CV mse 0.187 true out-sample CV mse 0.181
错误的离群样本测试:交叉验证数据
很多人告诉你需要交叉验证。 sklearn甚至为您提供了一些不错的便利功能。但是大多数交叉验证方法都会进行随机抽样,因此您最终可能会在测试集中获得训练数据,从而提高性能。
解决方案:生成测试数据,以便准确反映您在实际生产中使用的预测数据。特别是对于时间序列,您可能需要生成自定义交叉验证数据或进行前滚测试。
示例:此处您有两个不同实体(例如公司)的数据,这些实体具有高度相关性。如果您随机分割数据,则可以使用测试期间实际上没有的数据进行准确预测,从而夸大模型性能。您认为通过使用交叉验证避免了错误#5,并发现随机森林在交叉验证中比线性回归更好。但是,运行前滚样本测试可以防止将来的数据泄漏到测试中,它再次表现更差! (随机森林MSE从0.047变为0.211,高于线性回归!)
normal CV ols 0.203 rf 0.051 true out-sample error ols 0.166 rf 0.229
不考虑决策点可获得哪些数据
在生产中运行模型时,它会获得运行模型时可用的数据。该数据可能与您认为在训练中可用的数据不同。例如,数据可能会延迟发布,因此当您运行模型时,其他输入已更改,并且您正在使用错误数据进行预测,或者您的真实y变量不正确。
解决方案:进行滚动样本前向测试。如果我在生产中使用过这个模型,我的训练数据会是什么样的,即你有什么数据可以做出预测?这是您用于进行真正的样本外生产测试的训练数据。此外,考虑一下你是否对预测采取了行动,在决策点产生什么结果?
微妙的过度训练
花在数据集上的时间越多,就越有可能推翻它。您不断修改函数并优化模型参数并使用了了交叉验证,这一切都看上去很好。
解决方案:完成模型构建后,尝试查找可以作为真实样本外数据集的代理的数据集的另一个“版本”。如果您是经理,故意隐瞒数据,以免它被用于训练。
示例:将在数据集1上训练的模型应用于数据集2,显示MSE增加了一倍以上。它们仍然可以接受吗?这是一个判断调用,但#4的结果可能会帮助您做出决定。
first dataset rf mse 0.261 ols mse 0.187 new dataset rf mse 0.681 ols mse 0.495
“需要更多数据”的谬误
与直觉相反,开始分析数据的最佳方式通常是处理有代表性的数据样本。 这使您可以熟悉数据并构建数据管道,而无需等待数据处理和模型训练。 但数据科学家似乎不喜欢这样 - 更多数据更好。
解决方案:开始使用一个小型代表性样本,看看是否可以从中获得有用的东西。 把它还给最终用户,他们可以使用它吗? 它能解决真正的痛点吗? 如果没有,问题可能不是因为你的数据太少而是你的方法。
原文链接:https://towardsdatascience.com/top-10-statistics-mistakes-made-by-data-s...
本文转自:专知(Quan_Zhuanzhi),转载此文目的在于传递更多信息,版权归原作者所有。


