本文转自微信公众号SIGAI,全文PDF见:http://www.tensorinfinity.com/paper_168.html
1 引言
语义分割一直是计算机视觉中十分重要的领域,随着深度学习的流行,语义分割任务也得到了大量的进步。本文首先阐释何为语义分割,然后再从论文出发概述多种解决方案,并介绍目前语义分割领域主流的数据集。本文由浅层模型到深度模型,简要介绍了语义分割各种技术。本文简要地概述了每一篇重要论文的精要和亮点,希望能给读者一些指南。
如今,语义分割(应用于静态2D图像、视频甚至3D数据、体数据)是计算机视觉的关键问题之一。在宏观意义上来说,语义分割是为场景理解铺平了道路的一种高层任务。作为计算机视觉的核心问题,场景理解的重要性越来越突出,因为现实中越来越多的应用场景需要从影像中推理出相关的知识或语义(即由具体到抽象的过程)。这些应用包括自动驾驶,人机交互,计算摄影学,图像搜索引擎,增强现实等。应用各种传统的计算机视觉和机器学习技术,这些问题已经得到了解决。虽然这些方法很流行,但深度学习革命让相关领域发生了翻天覆地的变化,因此,包括语义分割在内的许多计算机视觉问题都开始使用深度架构来解决,通常是卷积神经网络CNN,而CNN在准确率甚至效率上都远远超过了传统方法。然而,相比于固有的计算机视觉及机器学习分支,深度学习还远不成熟。也因此,还没有一个统一的工作及对于目前最优方法的综述。该领域的飞速发展使得对初学者的启蒙教育比较困难,而且,由于大量的工作相继被提出,要跟上发展的步伐也非常耗时。于是,追随语义分割相关工作、合理地解释它们的论点、过滤掉低水平的工作以及验证相关实验结果等是非常困难的。
2 问题描述
更具体地,语义图像分割的目标是用对应的所表示的类来标记图像的每个像素。因为我们正在预测图像中的每个像素,所以此任务通常被称为密集预测。如下图所示。

分割模型对于多种任务都非常有用,比如:
(1) 自动驾驶

上图是用于自动驾驶的实时道路场景分割
(2)医学图像诊断

上图是一个胸腔x-射线片,包括分割出的心脏(hear,红色),肺(lungs,绿色)和锁骨(clavicles,蓝色)
3 如何构建语义分割网络?
一个比较初级的方式构造神经网络模型就是单纯堆叠数个卷积层(利用相同的padding以保证维度不变)再输出一个最终的分割图。这种模型通过一系列特征映射的变换直接学习得到一个从输入图像到输出分割结果的映射。然而,整个网络都在全分辨率下计算所带来的计算量是非常巨大的。
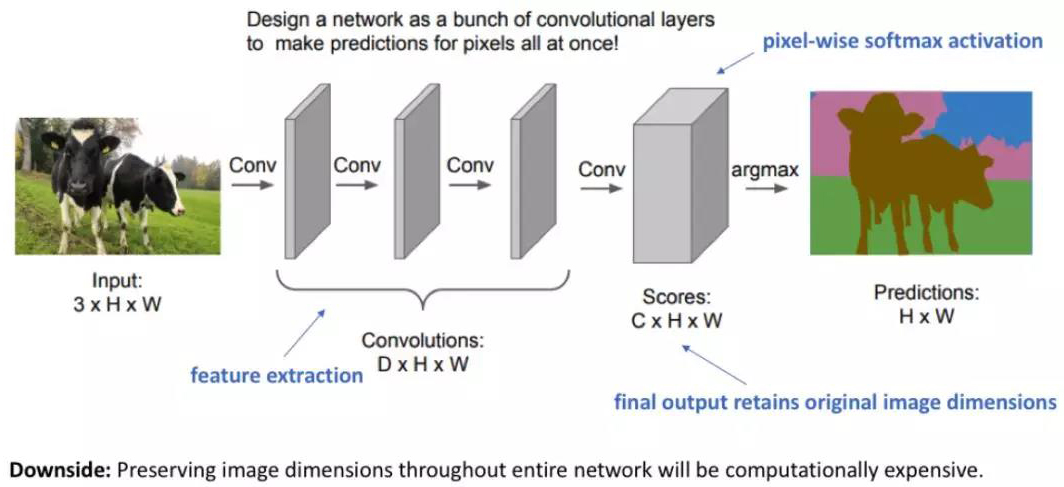
回顾在深卷积网络模型中,前面的层学习得到low-level概念,而后面的层则学到high-level(专门的)特征映射。为了保证表现,在加深网络的同时,通常需要增加特征图(通道数)的个数。
与图像分类单纯地需要目标类别不同,图像分割需要每个像素的位置信息,因此不能像分类任务中那样放心地使用pooling或大步长卷积来降低计算量,图像分割需要一个全分辨率的语义估计。
一种比较流行的图像分割模型是Encoder-Decoder结构。Encoder部分通过下采样降低输入的空间分辨率,从而生成一个低分辨率的特征映射(计算高效且能够有效区分不同类别);Decoder则对这些特征描述进行上采样,将其恢复成全分辨率的分割图。
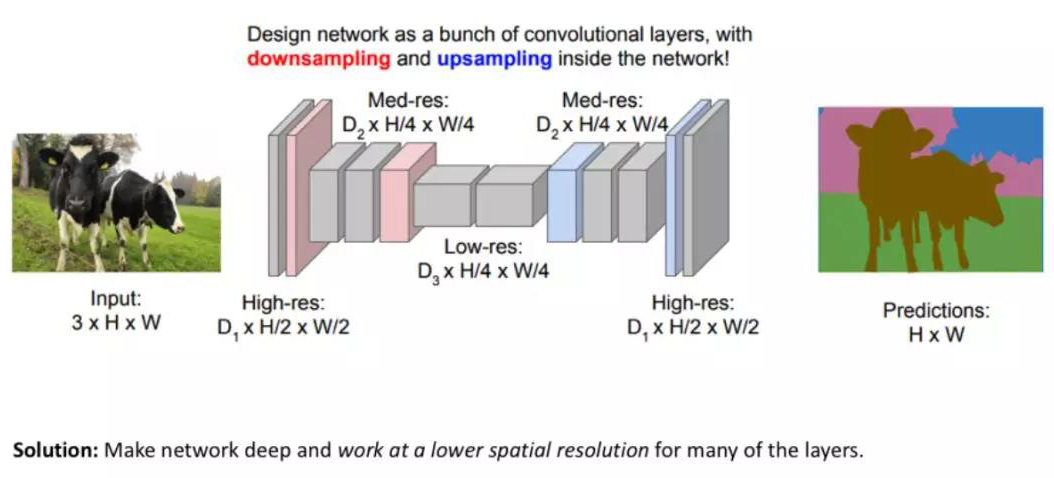
Fully convolutional networks(FCN)
FCN采用全卷积网络,没有图像分类网络中的全连接层。网络结构利用image classification networks(如AlexNet)作为编码器,利用反卷积层实现上采样恢复分辨率作为解码器,实现端到端训练的全卷积网络。

下图是完整的网络结构,可以看出网络是基于像素级别的交叉熵损失训练的。
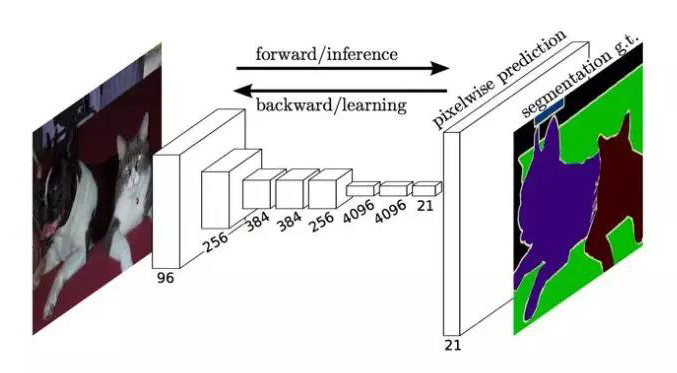
然而,由于编码器模块产生的分辨率是原始输入的1/32,解码器模块必须非常努力去恢复原始分辨率。如下图所示。

通过在早期的层上增加skip conncetions来实现缓慢(分步)上采样在对两个特征图求和的方式,上述问题得到了缓解。

这些来自网络中较早层的跳跃连接(在下采样操作之前)提供必要的细节,以便为分割边界重建精确的形状。实际上,我们可以通过添加这些跳过连接来恢复更细粒度的细节。

UNet
随后,Ronneberger等人通过扩张解码器模块的容量的方式改进了上述的全卷积结构(fully convolutional architecture)。具体来讲,这种U-Net结构“包括捕获上下文的收缩路径和实现精确定位的对称扩展路径”。这种结构目前非常流行,已经被拓展至了多种分割问题上。

改进的U-Net变体
Drozdzal等人用残差模块替换了基础卷积模块用于堆叠。这种残差模块在模块内部含有skip conncetions,同时保留了与U-Net相同的在编码器与译码器对应特征图之间的skip connections。他们称这种方式能够使得网络更快收敛,也能够适用于更深的网络结构。
基于此,Jegou等人提出了使用dense blocks,也是遵从于U-Net结构,称dense blocks的属性使得它们能够更好地适应语义分割任务,因为其天然携带skip connections和多尺度监督。这些dense blocks之所以好用是因为它们携带了从前序层中得到的low-level特征,也包含了从后续层中得到的higher level特征,从而实现更高效的特征复用。

SegNet
主要贡献
传递maxpooling indices至解码器,从而提高了分割的分辨率。
尽管FCN包含反卷积层和一些shortcut connections,其生成的分割图仍然比较粗糙。因此,SegNet引入了更多的shortcut connections。与FCN直接复制编码器特征的方式不同,SegNet复制的是maxpooling层生成的indices。这使得SegNet相比于FCN而言在存储上更高效(more memory efficient)。

扩张卷积 Dilated conv
对特征图进行下采样的一个好处是,给定相同的滤波器尺寸,其拓展了网络在输入上的感受野。考虑到这种方式比单纯增加滤波器尺寸更高效(参考这篇文章)。然而,这种做法会导致空间分辨率的降低。
扩张卷积提供了一种增加感受野但是又能保持空间分辨率的方法。具体如下图所示,其扩张的尺寸称为dilation rate。

部分网络将最后几层pooling层替换成了dilation rates逐渐升高的扩张卷积层来实现尽量减少空间细节丢失的基础上增加感受野。然而,用扩张卷积替换所有的pooling层的做法通常计算量很大。
DeepLab(v1 & v2)
主要贡献
- 使用扩张卷积(atrous/dilated convolutions)
- 提出ztrous spatial pyramid pooling (ASPP)
- 应用全连接CRF
Dilated卷积在不增加参数个数的基础上实现了感受野的增加。网络用与这篇论文(dilated convolutions paper)相同的方式进行了修改。
多尺度处理既可以通过同时传递原始图像的不同尺度进入平行CNN分支(图像金字塔)实现,也可以通过(或同时使用)多个不同采样率的平行atrous convolutional layers实现(ASPP)。
结构预测(Structured prediction)通过全连接CRF实现。CRF作为一个独立的后处理步骤单独训练。

RefineNet
主要贡献
- 包含谨慎设计的解码模块的编码器-解码器结构
- 所有部件(components)都包含残差连接设计
应用dilated/atrous卷积设计的方法的局限在于,扩张卷积的计算量巨大,且需要占用大量内存用于处理大量高分辨率的特征图。这一点输入了高分辨率下的预测计算。比如DeepLab’s预测就是原始输入的1/8尺寸。
因此,RefineNet论文中建议使用编码器-解码器结构。编码部分是ResNet-101模块,解码器包括RefineNet模块,将编码器下的高分辨率特征与前序RefineNet模块的低分辨率特征级联/融合。

每个RefineNet模块都包括通过对低分辨率特征上采样融合多分辨率特征的部件和基于5x5步长为1的pool层进行内容捕获的部件。上述的两个部件每个都应用了基于恒等映射思想(identity map mindset)的残差连接设计。

PSPNet
主要贡献
- 提出金字塔pooling结构以整合内容
- 引入辅助损失(auxiliary loss)
全局场景类别的意义在于其提供了分割类别的分布线索。金字塔pooling模型通过应用大尺寸核的pooling层以捕获这些信息。
如这篇论文,扩张卷积被应用于修改Resnet,同时增加了金字塔pooling模型。这个模型将ResNet的特征图经过上采样后整合。
除主分支上的损失外,辅助损失被应用于ResNet的第4个阶段。这个概念在其他地方也被称作intermediate supervision。

Large Kernel Matters
主要贡献
提出了含有非常大核的编码器-解码器结构
语义分割需要同时对分割对象进行分割和分类。考虑到全连接层不能实现分割任务,论文用大尺寸核的卷积运算替代全连接层。
另一个应用大尺寸核的愿意是,尽管类似于ResNet这样更深的网络结构能够拥有比较大的感受野,任由研究显示,网络其实从一个小很多的区域(有效感受野,valid receptive field)收集信息。
大尺寸核计算成本高且参数众多,因此一个kxk的卷积可以用1xk+kx1和kx1和1xk卷积(Therefore, k x k convolution is approximated with sum of 1 x k + k x 1 and k x 1 and 1 x k convolutions.)。这个模型在论文中被称为Global Convolutional Network (GCN)。
回到结构本身,ResNet(不含有任何扩张卷积)组成了编码层,GCNs和反卷积组成了解码层。算法还使用了一个简单的残差模块Boundary Refinement (BR)。

BiSeNet
主要贡献
提出spatial path 和 contex path实现实时性语义分割。
如下图(c)所示。
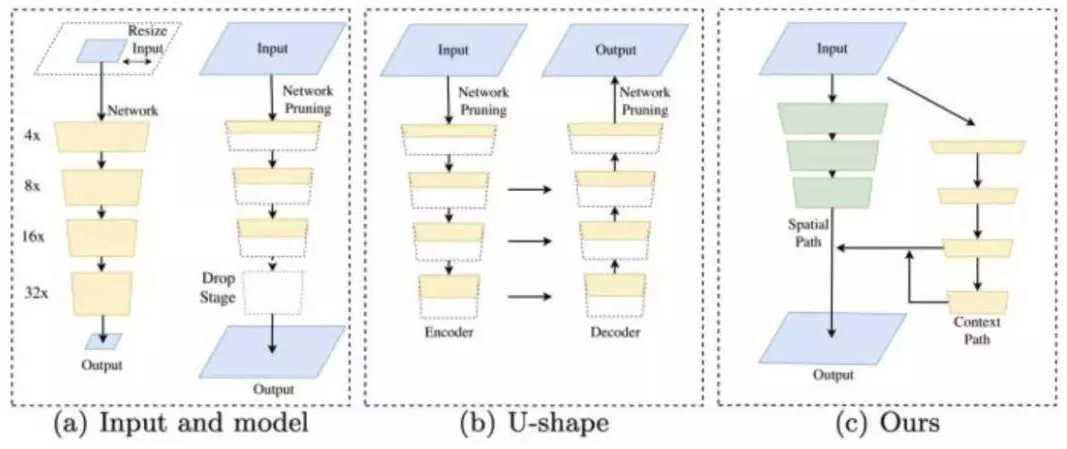
BiSeNet区别于 U-shape 和 Dilation 结构,尝试一种新的方法同时保持 Spatial Context 和 Spatial Detail 。所以,我们设计了Spatial Path和Context Path两部分。顾名思义,Spatial Path使用较多的 Channel、较浅的网络来保留丰富的空间信息生成高分辨率特征;Context Path使用较少的 Channel、较深的网络快速 downsample来获取充足的 Context。基于这两路网络的输出,文中还设计了一个Feature Fusion Module(FFM)来融合两种特征,如下图所示:

如下表所示,可以看到bisenet的精度和速度都很不错。

总结
语义分割在深度学习时代下取得了飞速的进步,然而从上面的回顾也可以看出,语义分割仍然有很多问题需要克服,目前还远称不上已经解决,更准确的分割边界,小物体的分割,实时性语义分割等问题仍然是一个挑战,要因此还需要学术界和工业界的持续努力。
Reference:
[1]Long J, Shelhamer E, Darrell T. Fully convolutional networks for semantic segmentation[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2015: 3431-3440.
[2]Ronneberger O, Fischer P, Brox T. U-net: Convolutional networks for biomedical image segmentation[C]//International Conference on Medical image computing and computer-assisted intervention. Springer, Cham, 2015: 234-241.
[3]Badrinarayanan V, Kendall A, Cipolla R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation[J]. IEEE transactions on pattern analysis and machine intelligence, 2017, 39(12): 2481-2495.
[4]Chen L C, Papandreou G, Kokkinos I, et al. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs[J]. IEEE transactions on pattern analysis and machine intelligence, 2017, 40(4): 834-848.
[5]Lin G, Milan A, Shen C, et al. Refinenet: Multi-path refinement networks for high-resolution semantic segmentation[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 1925-1934.
[6]Zhao H, Shi J, Qi X, et al. Pyramid scene parsing network[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 2881-2890.
[7]Peng C, Zhang X, Yu G, et al. Large Kernel Matters--Improve Semantic Segmentation by Global Convolutional Network[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 4353-4361.
[8] Yu C, Wang J, Peng C, et al. Bisenet: Bilateral segmentation network for real-time semantic segmentation[C]//Proceedings of the European Conference on Computer Vision (ECCV). 2018: 325-341.
本文为SIGAI原创, 如需转载,请联系微信公众号SIGAI
原文链接:https://mp.weixin.qq.com/s/_q8N8keNpcD-jXLrRd_8dw





