1. 又叫判定树,是一种基本的分类与回归方法。
2. 优点:可读性强,分类速度快,容易转换成if-then分类规则
3. 通常分为3个步骤:特征(属性)选择、决策树的生成、决策树的修剪。
4. 特征选择即选择分裂属性,又叫属性选择度量,把数据划分成较小的分区。
5. 决策树的生成又叫决策树学习或者决策树归纳。
6. 决策树生成时采用贪心(即非回溯的、局部最优的)方法,以自顶向下递归的分治方式构造,只考虑局部最优。
7. 决策树修剪时递归地从树的叶节点向上回缩,考虑全局最优。
8. 决策算法之间的差别包括在创建树时如何选择属性和用于剪枝的机制。
9. 决策算法主要为:ID3算法,C4.5算法和CART算法。
10. ID3算法和C4.5算法只有决策树的生成,没有对决策树进行剪枝。CART算法包括决策树的剪枝。
11. 在进行特征选择时,各个算法采用的选择分裂准则不同:
- ID3算法使用信息增益准则,选择信息增益最大(熵最小)的特征作为分裂属性。
- C4.5算法使用信息增益比准则,选择信息增益比最大的特征作为分裂属性。
- CART算法使用基尼指数准则,选择基尼指数最小的特征作为分裂属性。
12. 以信息增益准则划分训练数据集的特征时,偏向于选择属性取值较多的作为分裂属性;信息增益比准则调整了这种偏倚,但它倾向于产生不平衡的划分,其中一个分区比其他分区小得多;基尼指数准则也是偏向于多值属性,并且当类的数量很大时会有困难。
13. 所有的属性选择度量都具有某种偏倚。
14. 决策树归纳时的时间复杂度一般随树的高度指数增加。因此,倾向于产生较浅的树(如多路划分而不是二元划分)的度量可能更可取。但是,较浅的树趋向于具有大量树叶和较高的准确率。
15. CART算法假设决策树是二叉树,即只进行二元划分,不进行多元划分。
16. CART算法进行划分时不仅要选择最优分裂属性,还要在该属性的各个属性值中选择最优切分点(最优分裂点)。
17. CART算法既可以对离散值的数据进行划分生成分类树;也可以对连续值的数据采用平方误差最小准则生成回归树,又叫最小二乘回归树。
18. 在决策树创建的树是一棵“完全生长”的树,包含所有的训练样本。由于数据中的噪声和离群点,许多分枝反映的是训练数据中的异常,造成过分拟合数据问题。因此需要对生成的决策树进行剪枝。剪枝后的树更小、更简单,对独立的检验集分类时具有更强的泛化能力,比未剪枝的树更快、更好。
19. 信息增益的度量标准:熵。熵越大,随机变量的不确定性就越大,分类能力就越低.
设D为用类别对训练元组进行的划分,则D的熵(entropy)表示为:

其中pi表示第i个类别在整个训练元组中出现的概率,可以用属于此类别元素的数量除以训练元组元素总数量作为估计。熵的实际意义表示是D中元组的类标号所需要的平均信息量。
现在我们假设将训练元组D按属性A进行划分,则A对D划分的期望信息为:
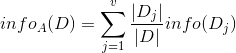
而信息增益即为两者的差值:

信息增益比:
特征A对训练数据集D的信息增益比gain_ratio(A)定义为其信息增益gain(A)与训练数据集D关于特征A的值的熵split_info(A)之比,即:
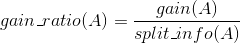
训练数据集D关于特征A的值的熵split_info(A) 为:

基尼指数:一种数据的不纯度的度量方法,其定义如下:
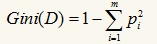
其中的m仍然表示数据集D中类别C的个数,Pi表示D中任意一个记录属于Ci的概率,计算时Pi=(D中属于Ci类的集合的记录个数/|D|)。如果所有的记录都属于同一个类中,则P1=1,Gini(D)=0,此时不纯度最低。在CART(Classification and Regression Tree)算法中利用基尼指数构造二叉决策树,对每个属性都会枚举其属性值的非空真子集,以属性R分裂后的基尼系数为:
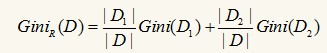
D1为D的一个非空真子集,D2为D1在D的补集,即D1+D2=D,对于属性R来说,有多个真子集,即GiniR(D)有多个值,但我们选取最小的那么值作为R的基尼指数。
本文转自:博客园 - fuleying,转载此文目的在于传递更多信息,版权归原作者所有。


