一、FCN
1、网络特点
全卷积(Convolutional)
上采样(Upsample)
跳跃结构(Skip Layer)
2、网络结构

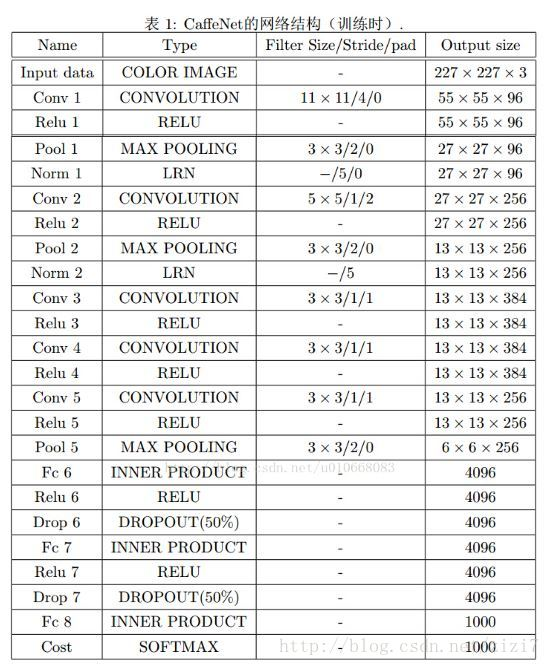
3、原理说明
全卷积
FCN将传统CNN中的全连接层转化成一个个的卷积层。如下图所示,在传统的CNN结构中,前5层是卷积层,第6层和第7层分别是一个长度为4096的一维向量,第8层是长度为1000的一维向量,分别对应1000个类别的概率。FCN将这3层表示为卷积层,卷积核的大小(通道数,宽,高)分别为(4096,1,1)、(4096,1,1)、(1000,1,1)。所有的层都是卷积层,故称为全卷积网络。
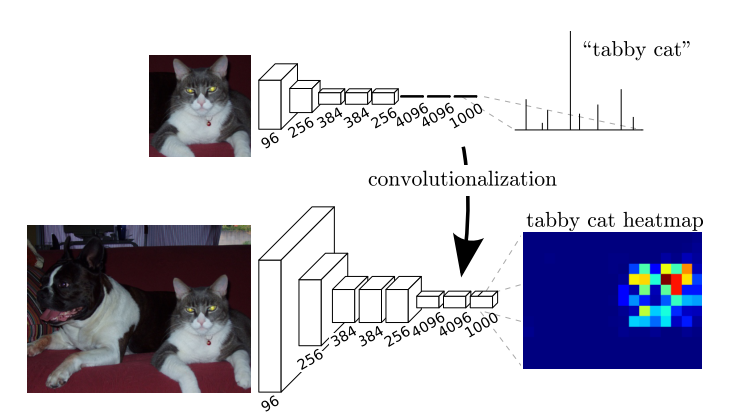
上采样——转置卷积
可以发现,经过多次卷积(还有pooling)以后,得到的图像越来越小,分辨率越来越低(粗略的图像),那么FCN是如何得到图像中每一个像素的类别的呢?为了从这个分辨率低的粗略图像恢复到原图的分辨率,FCN使用了上采样。例如经过5次卷积(和pooling)以后,图像的分辨率依次缩小了2,4,8,16,32倍。对于最后一层的输出图像,需要进行32倍的上采样,以得到原图一样的大小。这个上采样是通过反卷积(deconvolution)实现的。

一张更为形象的说明如下:

跳跃结构
对第5层的输出(32倍放大)反卷积到原图大小,得到的结果还是不够精确,一些细节无法恢复。于是Jonathan将第4层的输出和第3层的输出也依次反卷积,分别需要16倍和8倍上采样,结果就精细一些了。下图是这个卷积和反卷积上采样的过程:
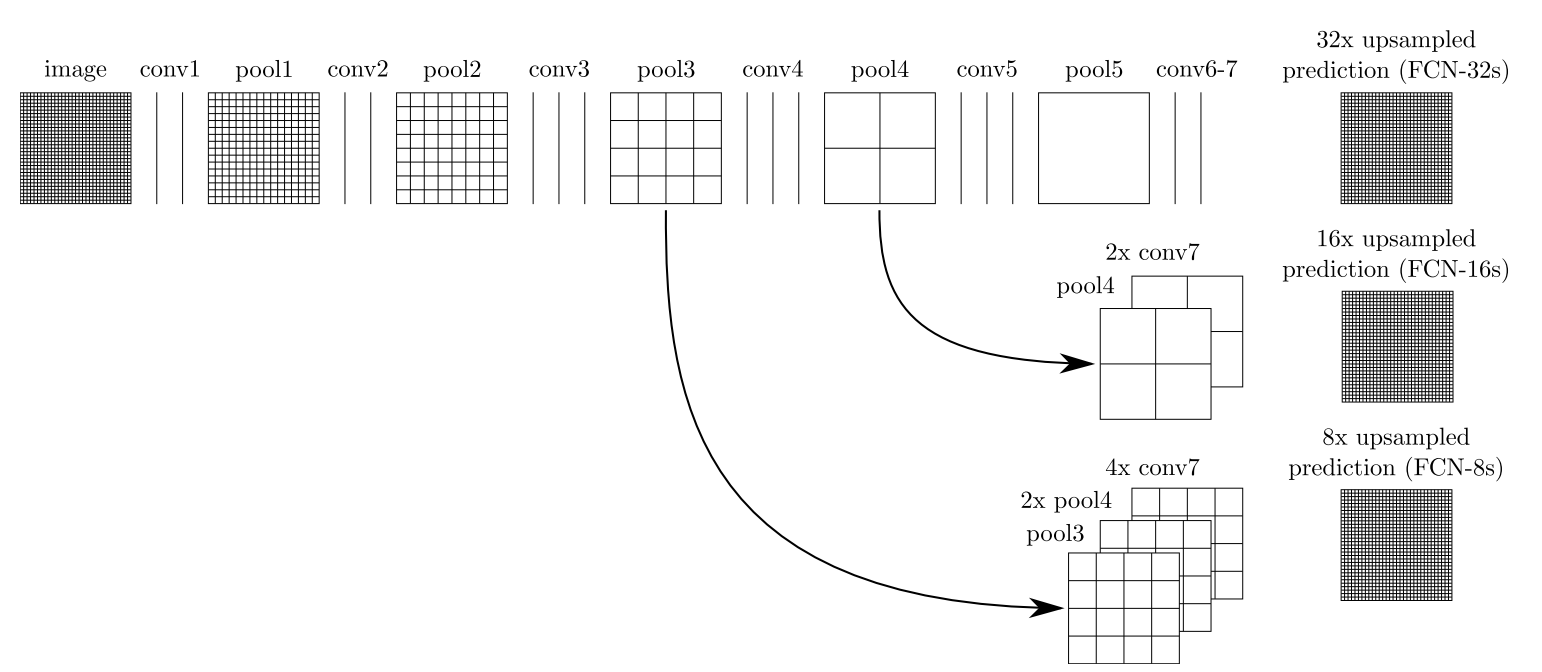
下图是32倍,16倍和8倍上采样得到的结果的对比,可以看到它们得到的结果越来越精确:

4、优点(贡献)和不足
优点和贡献
1.为深度学习解决语义分割提供了基本思路,激发了很多优秀的工作
2.输入图像大小没有限制,结构灵活
3.更加高效,节省时间和空间
不足
1.结果不够精细,边界不清晰
2.没有充分考虑到语义间的上下文关系
3.padding操作可能会引入噪声
二、SegNet
基于FCN的一项工作,修改VGG-16网络得到的语义分割网络,有两种SegNet,分别为正常版与贝叶斯版,同时SegNet作者根据网络的深度提供了一个basic版(浅网络)。
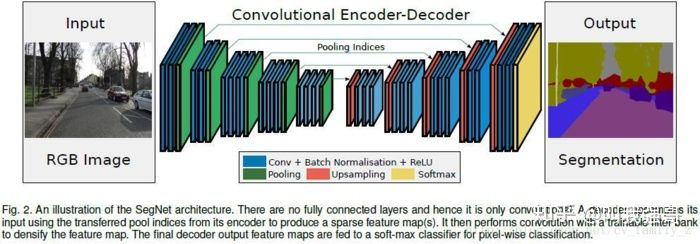
1、网络结构
作者提供了几种网络结构,上图就是通用结构:对称的encode-decode结构,想了解更为具体的实现建议查看开源实现。
2、创新点
SegNet的最大池化层和上采样层不同于通常的处理,SegNet 中使用最大池化,并且同时输出最大点的 index。同一层次的上采样根据 index 确定池化前 max 值的点的位置,并对其他丢失的点做插值。
补充一点,tensorflow对于SegNet的上采样方式并不支持(也许只是没有封装好而已,可以手动实现,不确定),所以我查到的实现一般就直接用普通的上采样了,这样tf版本的SegNet结构相较U-Net简单了不少(个人感觉两者还是很相似的)。有趣的是带索引最大池化tf是有封装好的接口的,在nn包中。
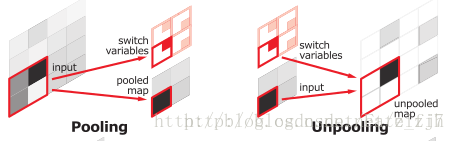
作为对比,下左为SegNet,下右为FCN中的上采样实现(FCN的上采样相较现在成熟的上采样方案也略有不同,多加了一个根据原始编码得来并保存的y,这需要消耗额外的内存):
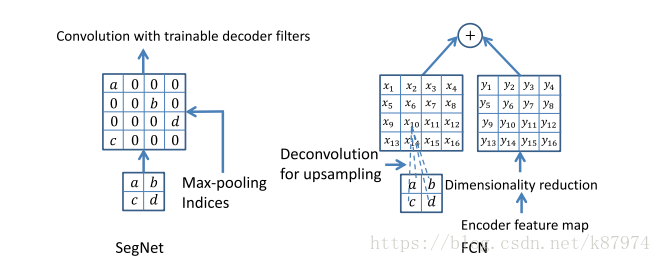
此外还有贝叶斯SegNet变种,不太懂,就不画蛇添足了。
三、U-Net
卷积网络被大规模应用在分类任务中,输出的结果是整个图像的类标签。然而,在许多视觉任务,尤其是生物医学图像处理领域,目标输出应该包括目标类别的位置,并且每个像素都应该有类标签。另外,在生物医学图像往往缺少训练图片。所以,Ciresan等人训练了一个卷积神经网络,用滑动窗口提供像素的周围区域(patch)作为输入来预测每个像素的类标签。
这个网络有两个优点:
第一,输出结果可以定位出目标类别的位置;
第二,由于输入的训练数据是patches,这样就相当于进行了数据增广,解决了生物医学图像数量少的问题。
但是,这个方法也有两个很明显缺点。
第一,它很慢,因为这个网络必须训练每个patch,并且因为patch间的重叠有很多的冗余(冗余会造成什么影响呢?卷积核里面的W,就是提取特征的权重,两个块如果重叠的部分太多,这个权重会被同一些特征训练两次,造成资源的浪费,减慢训练时间和效率,虽然说会有一些冗余,训练集大了,准确率不就高了吗?可是你这个是相同的图片啊,重叠的东西都是相同的,举个例子,我用一张相同的图片训练20次,按照这个意思也是增大了训练集啊,可是会出现什么结果呢,很显然,会导致过拟合,也就是对你这个图片识别很准,别的图片就不一定了)。
第二,定位准确性和获取上下文信息不可兼得。大的patches需要更多的max-pooling层这样减小了定位准确性(为什么?因为你是对以这个像素为中心的点进行分类,如果patch太大,最后经过全连接层的前一层大小肯定是不变的,如果你patch大就需要更多的pooling达到这个大小,而pooling层越多,丢失信息的信息也越多;小的patches只能看到很小的局部信息,包含的背景信息不够。
和SegNet格式极为相近,不过其添加了中间的center crop和concat操作实现了不同层次特征的upsample,目的同样是使上采样的层能够更多的参考前面下采样中间层的信息,更好的达到还原的效果。
U-Net的格式也不复杂,形状如下,参看github开源实现不难复现,注意用好相关张量操作API即可(如concet、slice等)。
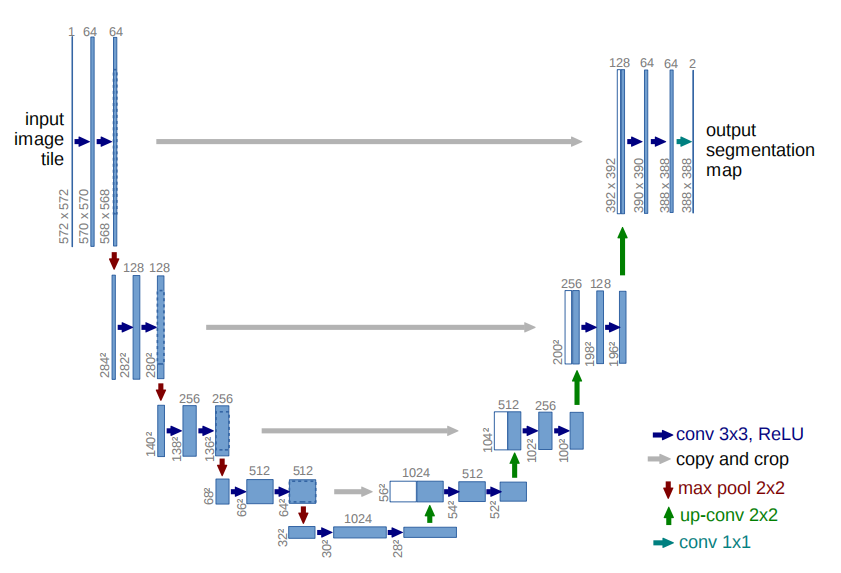
(1) 使用全卷积神经网络。(全卷积神经网络就是卷积取代了全连接层,全连接层必须固定图像大小而卷积不用,所以这个策略使得,你可以输入任意尺寸的图片,而且输出也是图片,所以这是一个端到端的网络。)
(2)左边的网络是收缩路径:使用卷积和maxpooling。
(3)右边的网络是扩张路径:使用上采样产生的特征图与左侧收缩路径对应层产生的特征图进行concatenate操作。(pooling层会丢失图像信息和降低图像分辨率且是不可逆的操作,对图像分割任务有一些影响,对图像分类任务的影响不大,为什么要做上采样?因为上采样可以补足一些图片的信息,但是信息补充的肯定不完全,所以还需要与左边的分辨率比较高的图片相连接起来(直接复制过来再裁剪到与上采样图片一样大小),这就相当于在高分辨率和更抽象特征当中做一个折衷,因为随着卷积次数增多,提取的特征也更加有效,更加抽象,上采样的图片是经历多次卷积后的图片,肯定是比较高效和抽象的图片,然后把它与左边不怎么抽象但更高分辨率的特征图片进行连接)。
(4)最后再经过两次反卷积操作,生成特征图,再用两个1X1的卷积做分类得到最后的两张heatmap,例如第一张表示的是第一类的得分,第二张表示第二类的得分heatmap,然后作为softmax函数的输入,算出概率比较大的softmax类,选择它作为输入给交叉熵进行反向传播训练。
本文转自:博客园 - 叠加态的猫,转载此文目的在于传递更多信息,版权归原作者所有。
原文链接:https://www.cnblogs.com/hellcat/p/7754795.html





