语音交互正在被视为用户在未来很多场景下的主要流量入口之一。因此,寻求可靠有效的远场语音技术突破变成了当下工业界和学术界的迫切需求。一个经典的语音识别系统包含麦克风信号采集模块、信号处理模块以及语音识别模块。每个模块的处理方法都会影响最终的识别效果。
具体来说,目前远场语音识别的技术难点主要集中在以下4个部分:
第一个是多通道同步采集硬件研发;
第二个是前端麦克风阵列信号处理算法研发;
第三个是后端语音识别与前端信号处理的匹配;
第四个是前端和后端联合优化。
首先,多通道麦克风阵列技术已经被证明可以显著提升语音识别质量。当信号采集通道数足够多时,需要额外研发多通道同步技术。并且,目前消费电子上很少有集成多个麦克风的情况,相关研究成果很少,这也增加了该硬件方案的研发难度。
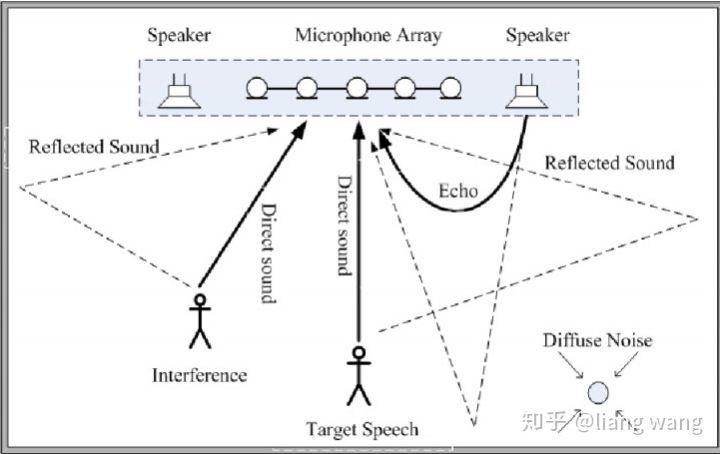
然后,在语音识别系统中,我们也要重点关注麦克风阵列信号处理算法设计的问题。如上图所示,远场语音识别主要面临着回声干扰、室内混响、多信号源干扰以及非平稳噪声的干扰等。关于语音增强方面,目前存在着两个主要的技术流派:一派认为利用深度学习的方法可以实现去混响、降噪声的目的。另外一派则采用基于麦克风阵列的传统信号处理方法。从目前的产品上看,麦克风阵列信号处理的方式占主流应用市场。例如:Echo采用7个麦克风,叮咚采用8个麦克风, Google home用了2个麦克风。本文主要阐述传统信号处理方法在远场语音识别中所面临的困境。
针对回声干扰问题,需采取回声消除技术,将设备自身播放的声音从麦克风接收到的信号中除去。该技术在手持移动端上已经非常成熟,比如speex和webrtc的开源软件中都有该算法。但是,这两个方案为了达到更大的回声抑制效果,使用了大量的非线性处理手段。而语音识别引擎对于语音信号的非线性处理非常敏感。因此,如果直接将近场回声消除技术用在远场语音识别领域,效果并不好。
房间混响是远场语音识别特有的问题。房间混响会造成麦克风接收到的信号有很长的拖尾,让人听起来感觉发闷。在实际中,人耳具有自动解混响的能力,在实际房间中相互交流并没有影响反而觉得声音饱满。但是这个对于语音识别来说是致命的。之前主要是近场识别,对去混响的需求不大,相关的研究内容不多。目前去混响技术主要以逆滤波方法、倒谱平均、谱减法为主,但这类方法对远场语音识别率提升不大。多步线性预测方法在去混响中表现不错,有兴趣的可以尝试一下。
多源信号干扰检测问题又称作“鸡尾酒会”问题。语音识别系统需要能够同时跟踪多个声源,且对每个声源都能够单独做处理。例如,对于某个目标源来说,其他信号源都是干扰,必须从接收信号中去除。或者将多个信号源同时进行识别输出,盲源分离需求对语音识别系统提出了巨大的挑战。谷歌在Google IO 2018大会上展示了能够同时识别2个人说话的技术,有兴趣的可以去找找相关的技术文献。
可以利用波束形成方法抑制非平稳噪声。在做波束形成之前需要先知道说话人的方向,这就需要对波达方向进行估计。学术界一般研究如何提高测向的精度和分辨率,但这些指标在实际中意义不大,实际中更需要解决如何在混响条件下提高DOA估计的鲁棒性。知道方向之后,就可以做波束形成,抑制周围的非平稳噪声。麦克风阵列增益和麦克风的数目与间距(满足空间采样定理)成正比,但是由于消费产品价格和尺寸的限制,麦克风的个数和间距有限,这个对算法的设计也提出来新挑战。
相对于近场语音识别来说,远场识别所面临的挑战主要是由复杂的信号传播环境引起的。因此,对于语音信号研究者来说,非常基础且重要的工作是对声音传播环境进行精准的建模。这个模型不光有助于我们认识信号衰减特性,能够设计出具有针对性的语音信号增强算法。而且,还可以借助这个模型,快速生成大量的远场语音数据用于识别端的声学模型训练,有助于解决远场语音数据难采集难的问题。
语音识别引擎对于语音信号的非线性处理非常敏感。相对于残留的背景噪声来说,语音失真程度对语音识别率起着主要的影响。前端信号处理中的非线性算法可以显著提升我们人耳的听觉效果,但是对于识别来说却会带来致命的影响。所以,对于信号处理的每个流程,我们都要结合前端和后端一起来评估信号处理算法的应用价值。而且,目前做前端和后端的人员往往属于不同的团队,所了解的知识大都有局限性,很难出一套前端后端联合设计的方案。
其次,语音识别引擎要和前端匹配。为了提升远场语音识别性能,需要用远场的语音数据训练声学模型。因为前端的信号处理和后端识别是联合使用的,所以,最佳的方法就是利用麦克风阵列采集的信号经过前端信号处理算法处理后的数据去训练语音识别引擎,效果应该会有大幅提升。同时,远场语音数据库不容易采集,如何通过信道传播模型生成包含干扰的信号来扩充数据库也是亟需研究的问题。
最后,综合上面来看,我个人觉得我们还有必要将前端信号处理和后端识别放在一个整体的框架下去做。主要方向可以考虑以下3点:
• 根据后端语音识别需求,重新评估前端信号处理模块的设计要点;
• 前端和后端进行联合设计,利用后端的神经网络来弥补前端信号处理算法性能不足的问题。尤其是当前端阵列尺寸受到限制,阵列增益有限的情况下;
• 目前的识别流程是先处理,再识别。这种方法的性能上界只能由前端和后端算法的性能的上界决定。然而,算法性能提升总是有限的,所以依靠算法去解决人机交互中的各种问题不是永远有效的。是否可以借助事先确定说话人身份的识别机制(识别+合理的猜测)来提升识别效果。
以上是我个人最近在从事相关工作中的一点感想,欢迎各位读者对上面的观点进行纠正与补充。上面所有的问题都是开放性的,我也再不断思考以上问题,期望各位读者能给出更好的解决方案。
本文转自:知乎 - liang wang,转载此文目的在于传递更多信息,版权归原作者所有。
原文链接:https://zhuanlan.zhihu.com/p/43279047