缩放神经网络,无论是使用的训练数据量、模型大小还是使用的计算,对于提高许多现实世界机器学习应用程序的模型质量至关重要,例如计算机视觉、语言理解和神经机器翻译. 反过来,这又促使最近的研究仔细审查在缩放神经模型的成功中起关键作用的因素。尽管增加模型容量可能是提高模型质量的合理方法,但这样做会带来许多必须克服的系统和软件工程挑战。例如,为了训练超过加速器内存容量的大型模型,有必要在多个加速器之间划分权重和模型计算。这种并行化过程会增加网络通信开销,并可能导致设备利用率不足。此外,给定的并行化算法通常需要大量的工程工作,可能不适用于不同的模型架构。
为了解决这些扩展挑战,我们提出了“ GSPMD:ML 计算图的通用和可扩展并行化”,其中我们描述了一个基于XLA 编译器的开源自动并行化系统。GSPMD 能够扩展大多数深度学习网络架构,并且已经应用于许多深度学习模型,例如GShard-M4、LaMDA、BigSSL、ViT和MetNet-2,从而在跨领域取得最先进的结果几个域。GSPMD 还被集成到多个 ML 框架中,包括TensorFlow和JAX,它们使用 XLA 作为共享编译器。
概述
GSPMD 将 ML 模型编程任务与并行化挑战分开。它允许模型开发人员编写程序,就好像它们在具有非常高内存和计算能力的单个设备上运行一样——用户只需要将几行注释代码添加到模型代码中的关键张量子集中,以指示如何分割张量。例如,要训练一个大型模型并行的Transformer,一个人可能只需要注释少于 10 个张量(少于整个计算图中所有张量的 1%),每个张量一行附加代码。然后 GSPMD 运行编译器通道,确定整个图的并行化计划,并将其转换为数学上等效的并行化计算,可以在每个设备上执行。这使用户可以专注于模型构建而不是并行化实现,并且可以轻松移植现有的单设备程序以在更大范围内运行。
模型编程和并行性的分离还允许开发人员最大限度地减少代码重复。使用 GSPMD,开发人员可以针对不同的用例采用不同的并行算法,而无需重新实现模型。例如,支持 GShard-M4 和 LaMDA 模型的模型代码可以应用各种适用于具有相同模型实现的不同模型和集群大小的并行化策略。同样,通过应用 GSPMD,BigSSL 大型语音模型可以与以前的较小模型共享相同的实现。
通用性和灵活性
由于不同的模型架构可能更适合不同的并行化策略,因此 GSPMD 旨在支持适用于不同用例的多种并行算法。例如,对于适合单个加速器内存的较小模型,数据并行是首选,其中设备使用不同的输入数据训练相同的模型。相比之下,大于单个加速器内存容量的模型更适合流水线算法(如GPipe采用的算法),该算法将模型划分为多个、连续的阶段或运算符级并行(例如,Mesh-TensorFlow),其中模型中的单个计算运算符被拆分为更小的并行运算符。
GSPMD 支持上述所有具有统一抽象和实现的并行化算法。此外,GSPMD 支持嵌套的并行模式。例如,它可用于将模型划分为单独的流水线阶段,每个流水线阶段都可以使用运算符级并行性进一步划分。
GSPMD 还允许性能专家专注于最能利用硬件的算法,而不是涉及大量跨设备通信的实现,从而促进了并行算法的创新。例如,对于大型 Transformer 模型,我们发现了一种新颖的算子级并行算法,可以在设备的 2D 网格上划分张量的多个维度。它随着训练设备的数量线性减少峰值加速器内存使用量,同时由于其在多个维度上的平衡数据分布,保持加速器计算的高利用率。
为了说明这一点,请考虑已按上述方式注释的 Transformer 模型中的简化前馈层。为了对完全分区的输入数据执行第一个矩阵乘法,GSPMD 应用MPI风格的AllGather通信算子与来自另一个设备的分区数据进行部分合并。然后它在本地执行矩阵乘法并产生一个分区结果。在第二次矩阵乘法之前,GSPMD 在右侧输入添加另一个 AllGather,并在本地执行矩阵乘法,产生随后需要组合和分区的中间结果。为此,GSPMD 添加了一个 MPI 风格的ReduceScatter累积和划分这些中间结果的通信算子。虽然在每个阶段使用 AllGather 算子生成的张量都大于原始分区大小,但它们是短暂的,使用后会释放相应的内存缓冲区,这不会影响训练中的峰值内存使用。
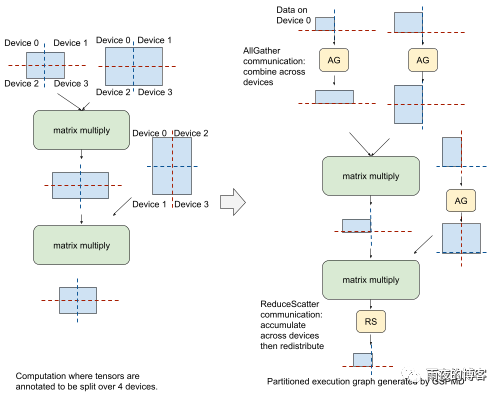
具有嵌套并行性的 Transformer 示例
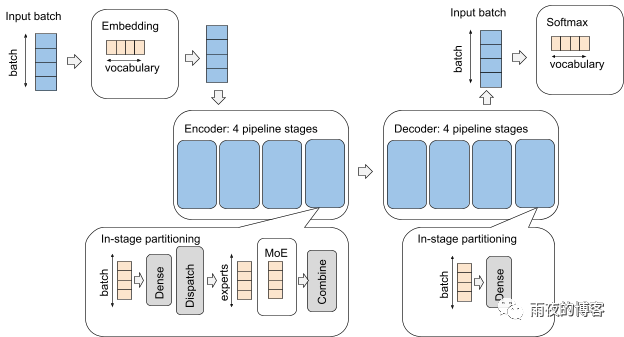
作为针对不同并行性模式的共享、健壮机制,GSPMD 允许用户方便地在模型不同部分的模式之间切换。这对于可能具有不同性能特征的不同组件的模型特别有价值,例如,处理图像和音频的多模态模型。考虑一个具有Transformer编码器-解码器架构的模型,它有一个嵌入层、一个带有Mixture-of-Expert层的编码器堆栈、一个带有密集前馈层的解码器堆栈和一个最终的softmax层。在 GSPMD 中,可以通过简单的配置实现对每一层分别处理的几种并行模式的复杂组合。
在下图中,我们展示了组织为逻辑 4x4 网格的 16 个设备的分区策略。蓝色表示沿第一个网格维度X 进行分区,黄色表示沿第二个网格维度Y 进行分区。X和Y被重新用于不同的模型组件以实现不同的并行模式。例如,X维用于嵌入层和 softmax 层中的数据并行,但用于编码器和解码器中的流水线并行。该ÿ尺寸也被用来以不同的方式来划分词汇,分批或模型专家尺寸。
计算效率
GSPMD 在大型模型训练中提供行业领先的性能。并行模型需要额外的通信来协调多个设备来进行计算。因此,可以通过检查花费在通信开销上的时间比例来估计并行模型的效率——利用率越高,花费在通信上的时间越少越好。在最近的MLPerf性能基准测试集中,一个类似 BERT 的仅编码器模型具有约 5000 亿个参数,我们在 2048 TPU-V4 上应用 GSPMD 进行并行化芯片产生了极具竞争力的结果(见下表),利用了 TPU-V4 提供的高达 63% 的峰值 FLOPS。我们还在下表中提供了一些具有代表性的大型模型的效率基准。这些示例模型配置在Lingvo 框架中开源,并附有在 Google Cloud 上运行它们的说明。更多的基准测试结果可以在我们论文的实验部分找到。
模范家庭 参数计数 已激活模型的百分比* 专家人数** 层数 TPU数量 FLOPS 利用率
密集解码器 (LaMDA) 137B 100% 1 64 1024 TPUv3 56.5%
密集编码器 (MLPerf-Bert) 480B 100% 1 64 2048 TPUv4 63%
稀疏激活编码器-解码器 (GShard-M4) 577B 0.25% 2048 32 1024 TPUv3 46.8%
稀疏激活解码器 1.2T 8% 64 64 1024 TPUv3 53.8%
结论
许多有用的机器学习应用程序(例如 NLP、语音识别、机器翻译和自动驾驶)的持续发展和成功取决于尽可能实现最高准确度。
声明:本文为转载文章,转载此文目的在于传递更多信息,版权归原作者所有,如涉及侵权,请联系小编邮箱 demi@eetrend.com 进行处理。





