近期,Unity 发布了 Object Pose Estimation 示例项目(Demo),该 Demo 将计算机视觉和仿真技术相结合,展示了 Unity 人工智能和机器学习功能如何有效地训练机器人,加速其在工业领域的应用落地。Unity 之前还推出了支持机器人操作系统(ROS)的最新版本,ROS 提供了用于编写机器人程序的灵活软件架构。这些新工具为机器人专家打开了一扇大门,让他们可以安全、经济、快速地进行机器人应用的研究、测试、开发与部署解决方案。
Unity 人工智能高级副总裁 Danny Lange 表示:“这个 Demo 是系统主动学习而非被动编程的有力例证。通过对大量合成数据的学习,系统能够捕捉到具有细微差别的图案,这是任何一个普通程序都无法做到的。它展示了真正的人工智能技术,以及在训练机器人方面可能达到的效率。这些技术加在一起,能够看到我们正不断突破界限。”

在危险、昂贵或特殊的情况下测试应用程序时,仿真技术能够发挥很大的作用。在仿真环境中验证应用程序,可以在程序实际部署到机器人之前就尽早发现潜在问题,大大缩短迭代时间。
而现实世界中的机器人想要顺利运行,就必须适应动态的环境。为此,机器人必须能感知对象、与对象交互。感知和交互的一个重要依据是获悉对象在某坐标系中的位置和方向(也可称为“姿势”)。早期的姿势法通常依赖于传统的计算机视觉技术和自定的基准标记,仅适用于特定环境,在面临环境变更或偏差时通常会产生错误。而今,传统计算机视觉的局限性被新型深度学习技术克服,Unity 内置的物理引擎与 Unity 编辑器结合,可用于创建出具有无数排列组合方式的虚拟测试环境,测试中的对象可以通过(贴近)现实世界中作用在物体上的力来控制。
本演示工程使用图像和人工标注的姿势标签来训练预测姿势的模型,模型可在运行时根据从未见过的图像预测对象姿势。深度学习模型要想充分发挥作用,通常需要搜集成千上万的带标签图像。如此大量的数据要在现实世界中收集不仅过程冗长、成本高昂,且在部分情况下(如 3D 对象定位)会非常困难。即使完成了数据的收集和标记,搜集过程也可能是有偏差、易出错、冗长,成本还高。那么,当应用所需的数据尚不能搜集或真正存在时,怎样才能利用强大的机器学习来解决问题?
Unity Computer Vision 可以生成合成数据,来满足机器学习的数据需求。本文将展示如何在 Unity 中生成数据、自动标注标签,用于模型训练。模型随后将被部署至带有机器人操作系统(ROS)的模拟 UR3 机器人手臂上,实现对姿势未知的方块的分拣。
合成数据的生成

Unity 引擎完全可以用作模拟器来生成合成数据。在前文中我们已经介绍了怎样使用 Unity Computer Vision 轻松收集大量正确标注与带有变化的数据(点击回看)。在本项目中,我们收集了许多在各种姿势和光照条件下的方块示例图像,这种场景各方面随机化的方法称为域随机化[1],多样化的数据可让深度学习模型更加耐用。
如果要在现实中搜集这么多变化的方块姿势数据,我们必须人为挪动方块再拍摄。而模型的训练使用了 30,000 多张图像,即使只要 5 秒就能拍出一张,完成所有数据的搜集也将耗费 40 多个小时。这里不包括标注图像所需的时间。而有了 Unity Computer Vision 后,我们便能在短短几分钟内生成 30,000 张训练图像和另外 3,000 张标注好的参考图像。
在本例中,摄像机、桌子和机器人的位置是固定的,而光照和方块姿势在每帧上都是随机变化的。图像标签将保存到相应的 JSON 文件中,而姿势将以 3D 坐标(x、y、z)和四元数方向(qx、qy、qz、qw)描述。这里仅有方块的姿势和环境光照有变化,但 Unity Computer Vision 完全可以随机化场景的各个方面。为了执行姿势估计,我们使用了一种监督学习技术来分析数据,并最终训练出了模型。
借助深度学习预测推测姿势
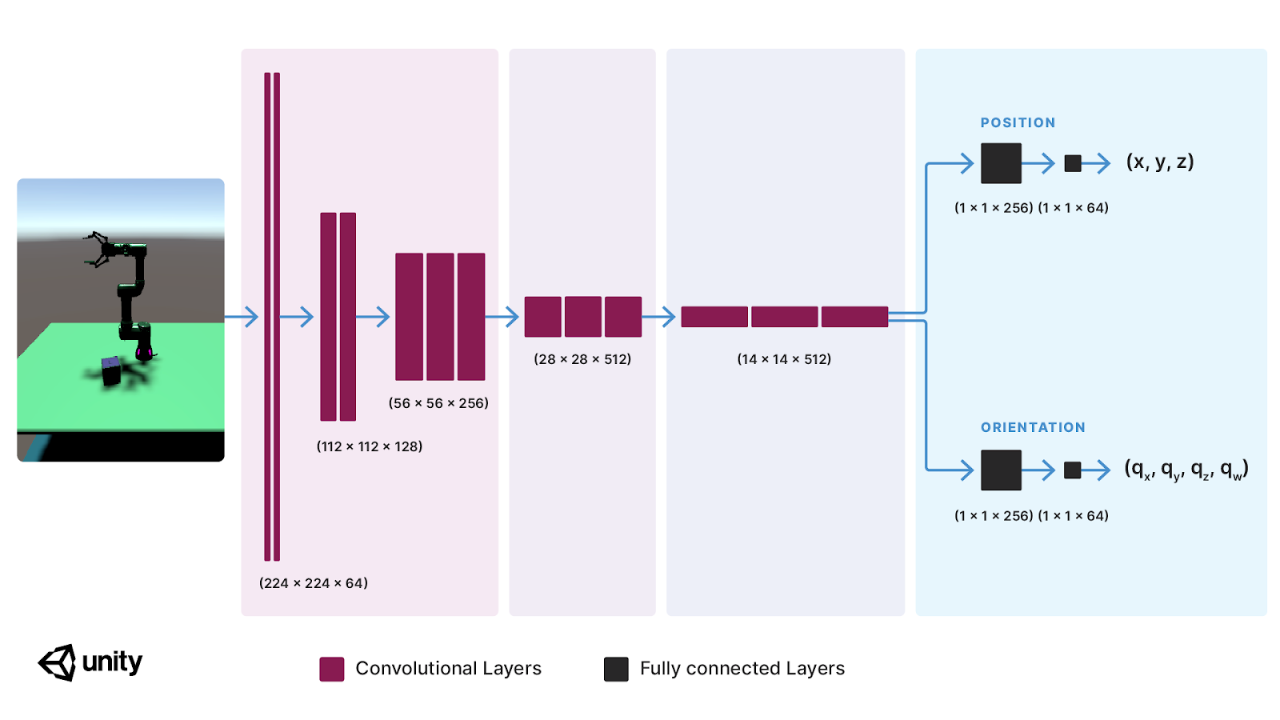
在监督学习中,模型将借助一组输入和对应的输出、图像和姿势标签来学习结果预测。在几年前,有一组研究人员推出了[2]可以预测物体位置的卷积神经网络(CNN),而我们这次扩展了神经网络,将方块的方向也加到了网络的输出中,来取得方块的 3D 姿势。为了训练模型,我们尽量降低预测姿势与真实姿势的最小平方偏差,模型在训练后预测出的方块位置偏差可缩小至 1 厘米、2.8 度(0.05 弧度)之内。接着我们来看看机器人是否能成功完成分拣任务。
ROS 动作规划
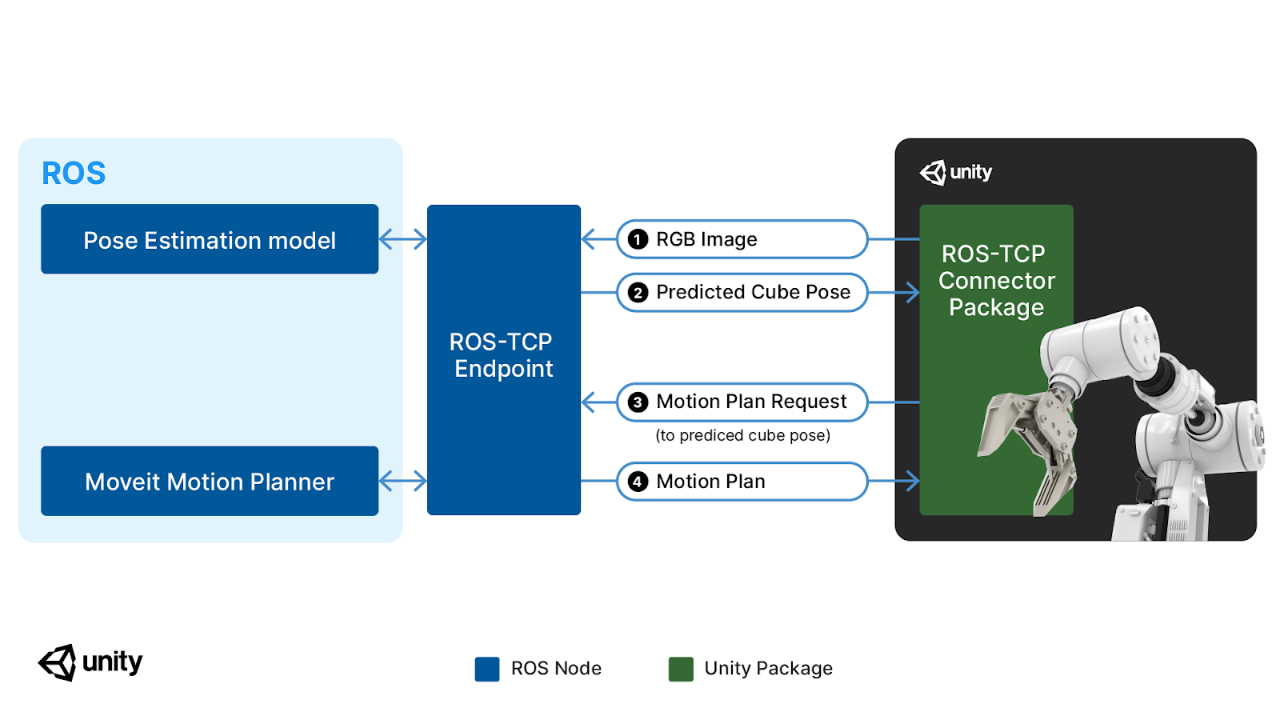
本项目中使用了配备 Robotiq 2F-140 抓手的 UR3 机械手臂,手臂使用了 Unity Robotics URDF Importer 软件包导入场景,使用 Unity Robotics ROS-TCP Connector 处理数据通讯,由 ROS MoveIt 软件包处理动作规划和控制。
这时我们已然能使用深度学习模型准确地预测方块的姿势,而这个预测姿势便能用作分拣任务中的目标姿势。在先前的 Pick-and-Place Demo 分拣演示中,我们使用的是目标对象的现实姿势。而这次机器人无需事先了解方块的姿势,只需用深度学习模型预测出的姿势即可执行分拣任务。
整个任务流程包含 4 个步骤:
- 由 Unity 记录一张目标方块图像
- 图像传入深度学习模型,由模型生成一个预测姿势
- 预测姿势传输至 Movelt 用于动作规划
- ROS 向 Unity 返回一个机器人运动轨迹,机器人试着捡起方块
每次任务中方块都会移动到一个随机位置:方块在模拟中的姿势容易获取,但在现实中却不是那么回事。要让项目能真正运行于机器人上,我们需要仅根据传感器数据来确定方块姿势。这时,姿势模型的作用就显得很大了。在模拟测试中,模拟机械臂在 89% 情况下可以正确地捡起方块。
结论

Object Pose Estimation Demo 展示了 Unity 生成合成数据、训练深度学习模型及借助 ROS 机器人解决问题的能力。我们使用了 Unity Computer Vision 工具来生成标签化合成数据,训练出了一个简单的姿势预测模型。Demo 中还带有一个重现项目的教程,你可以在场景中加入更多随机因素进行拓展。ROS 上的推理节点使用了深度学习模型来预测方块姿势,而人机交互则使用了 Unity Robotics 工具实现。
随着最新的 Demo,Unity 还发布了一款开源的 Unity 程序包 URDF Importer,可用于将机器人从其 URDF 文件导入到 Unity 场景中。Unity 中增强的关节运动支持(点击回看)可以进行更逼真的运动学模拟,此外,Unity 的 ROS-TCP-Connector 还可大幅降低 ROS 节点和 Unity 之间的信息延迟,让机器人能够几乎实时地响应模拟的环境。各位开发者们可以借助这些工具在自己的设备上探索、测试、开发和部署解决方案。在决定进一步推进开发时,可使用 Unity Simulation 来节省实际演练会产生的时间与金钱成本。
“通过 Unity,我们让人工数据合成变得更加大众化,而且使在虚拟环境中模拟高级交互成为可能。例如,为自动驾驶车辆或造价高昂的机器人手臂开发控制系统时,就不必担心破坏设备或增加工业安装成本了。如今人工智能和机器学习的发展,让机器人可以在工业各个领域执行更复杂的任务,而能够在高保真的虚拟环境中验证应用程序将节省时间和资金,加快机器人的应用落地。”Lange 补充到。
Unity Computer Vision 与 Unity Robotics 工具皆可免费使用,快来下载 Object Pose Estimation Demo 开启机器人开发之旅吧。
Object Pose Estimation Demo 下载地址:
https://github.com/Unity-Technologies/Robotics-Object-Pose-Estimation
文中提及的其他相关链接:
[1] Unity Robotics GitHub :
https://github.com/Unity-Technologies/Unity-Robotics-Hub
[2] Unity Computer Vision 页面:
https://unity.com/cn/computer-vision
[3] Unity 程序包 URDF Importer:
https://github.com/Unity-Technologies/URDF-Importer
[4] ROS-TCP-Connector:
https://github.com/Unity-Technologies/ROS-TCP-Connector
[5] Perception SDK:
https://github.com/Unity-Technologies/com.unity.perception
参考文献:
[1] J. Tobin, R. Fong, A. Ray, J. Schneider, W. Zaremba, P. Abbeel, “Domain Randomization for Transferring Deep Neural Networks from Simulation to the Real World” arXiv:1703.06907, 2017
[2] J. Tobin, W. Zaremba, and P. Abbeel, “Domain randomization and generative models for robotic grasping,” arXiv preprint arXiv:1710.06425, 2017





