作者:Amit Chaudhary
编译:ronghuaiyang
导读
图解半监督的各种方法的关键思想。
计算机视觉的半监督学习方法在过去几年得到了快速发展。目前最先进的方法是在结构和损失函数方面对之前的工作进行了简化,以及引入了通过混合不同方案的混合方法。
在这篇文章中,我会通过图解的方式解释最近的半监督学习方法的关键思想。
1、自训练
在该半监督公式中,对有标签数据进行训练,并对没有标签的数据进行伪标签预测。然后对模型同时进行 ground truth 标签和伪标签的训练。
a. 伪标签
Dong-Hyun Lee[1]在 2013 年提出了一个非常简单有效的公式 —— 伪标签。
这个想法是在一批有标签和没有标签的图像上同时训练一个模型。在使用交叉熵损失的情况下,以普通的监督的方式对有标签图像进行训练。利用同一模型对一批没有标签的图像进行预测,并使用置信度最大的类作为伪标签。然后,通过比较模型预测和伪标签对没有标签的图像计算交叉熵损失。
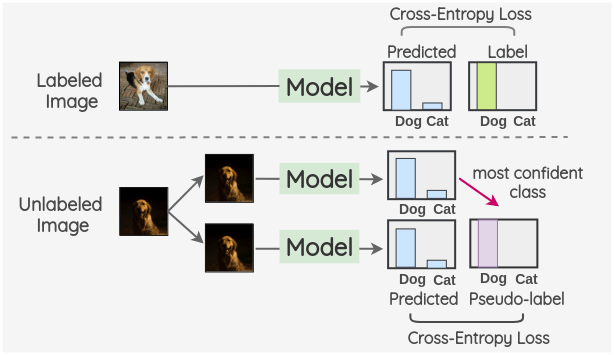
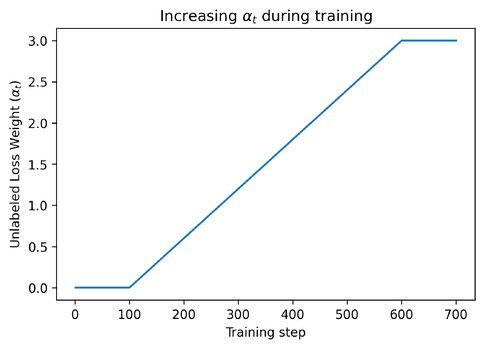
总的 loss 是有标签和没有标签的 loss 的加权和。

为了确保模型已经从有标签的数据中学到了足够的知识,在最初的 100 个 epoch 中,αt 被设置为 0。然后逐渐增加到 600 个 epochs,然后保持不变。
b. Noisy Student
Xie 等[2]在 2019 年提出了一种受知识蒸馏启发的半监督方法“Noisy Student”。
关键的想法是训练两种不同的模型,即“Teacher”和“Student”。Teacher 模型首先对有标签的图像进行训练,然后对没有标签的图像进行伪标签推断。这些伪标签可以是软标签,也可以通过置信度最大的类别转换为硬标签。然后,将有标签和没有标签的图像组合在一起,并根据这些组合的数据训练一个 Student 模型。使用 RandAugment 进行图像增强作为输入噪声的一种形式。此外,模型噪声,如 Dropout 和随机深度也用到了 Student 模型结构中。
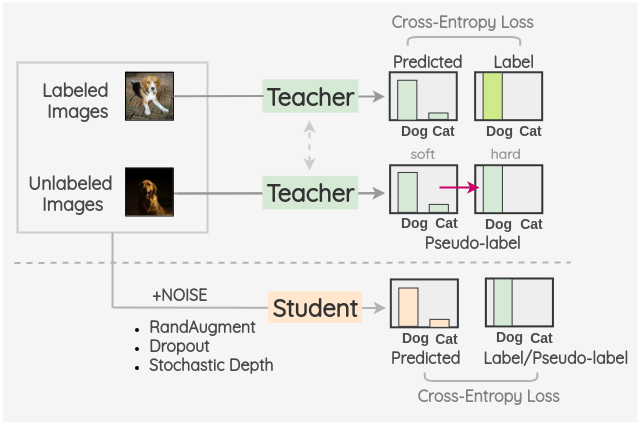
一旦学生模型被训练好了,它就变成了新的老师,这个过程被重复三次。
2、一致性正则化
这种模式使用的理念是,即使在添加了噪声之后,对未标记图像的模型预测也应该保持不变。我们可以使用输入噪声,如图像增强和高斯噪声。噪声也可以通过使用 Dropout 引入到结构中。
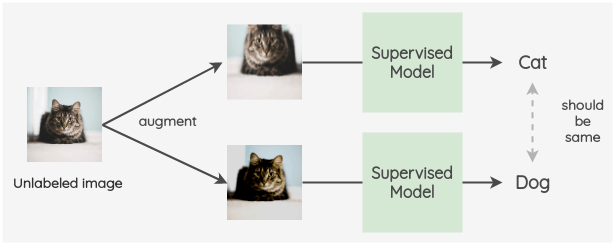
a. π-model
该模型由Laine 等[3]在 ICLR 2017 年的一篇会议论文中提出。
关键思想是为标记数据和未标记数据创建两个随机的图像增强。然后,使用带有 dropout 的模型对两幅图像的标签进行预测。这两个预测的平方差被用作一致性损失。对于标记了的图像,我们也同时计算交叉熵损失。总损失是这两个损失项的加权和。权重 w(t)用于决定一致性损失在总损失中所占的比重。
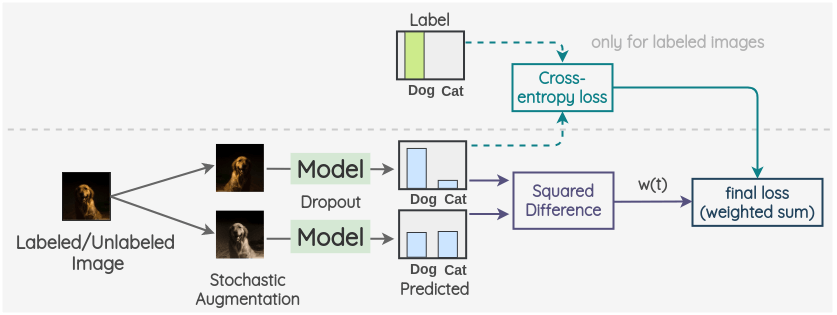
b. Temporal Ensembling
该方法也是由Laine 等[4]在同一篇论文中提出的。它通过利用预测的指数移动平均(EMA)来修正模型。
关键思想是对过去的预测使用指数移动平均作为一个观测值。为了获得另一个观测值,我们像往常一样对图像进行增强,并使用带有 dropout 的模型来预测标签。采用当前预测和 EMA 预测的平方差作为一致性损失。对于标记了的图像,我们也计算交叉熵损失。最终损失是这两个损失项的加权和。权重 w(t)用于决定稠度损失在总损失中所占的比重。

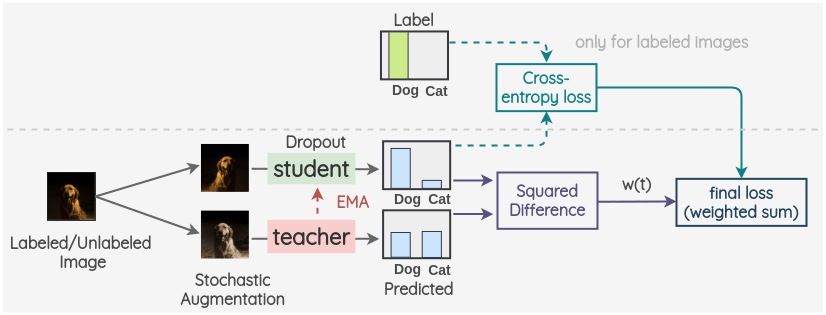
c. Mean Teacher
该方法由Tarvainen 等[5]提出。泛化的方法类似于 Temporal Ensembling,但它对模型参数使用指数移动平均(EMA),而不是预测值。
关键思想是有两种模型,称为“Student”和“Teacher”。Student 模型是有 dropout 的常规模型。教师模型与学生模型具有相同的结构,但其权重是使用学生模型权重的指数移动平均值来设置的。对于已标记或未标记的图像,我们创建图像的两个随机增强的版本。然后,利用学生模型预测第一张图像的标签分布。利用教师模型对第二幅增强图像的标签分布进行预测。这两个预测的平方差被用作一致性损失。对于标记了的图像,我们也计算交叉熵损失。最终损失是这两个损失项的加权和。权重 w(t)用于决定稠度损失在总损失中所占的比重。
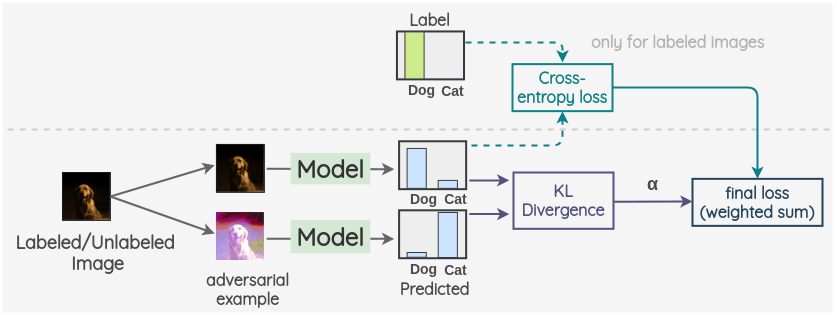
d. Virtual Adversarial Training
该方法由Miyato 等[6]提出。利用对抗性攻击的概念进行一致性正则化。
关键的想法是生成一个图像的对抗性变换,着将改变模型的预测。为此,首先,拍摄一幅图像并创建它的对抗变体,使原始图像和对抗图像的模型输出之间的 KL 散度最大化。
然后按照前面的方法进行。我们将带标签/不带标签的图像作为第一个观测,并将在前面步骤中生成的与之对抗的样本作为第二个观测。然后,用同一模型对两幅图像的标签分布进行预测。这两个预测的 KL 散度被用作一致性损失。对于标记了的图像,我们也计算交叉熵损失。最终损失是这两个损失项的加权和。采用加权偏置模型来确定一致性损失在整体损失中所占的比重。
e. Unsupervised Data Augmentation
该方法由Xie 等[7]提出,适用于图像和文本。在这里,我们将在图像的上下文中理解该方法。
关键思想是使用自动增强创建一个增强版本的无标签图像。然后用同一模型对两幅图像的标签进行预测。这两个预测的 KL 散度被用作一致性损失。对于有标记的图像,我们只计算交叉熵损失,不计算一致性损失。最终的损失是这两个损失项的加权和。权重 w(t)用于决定稠度损失在总损失中所占的比重。
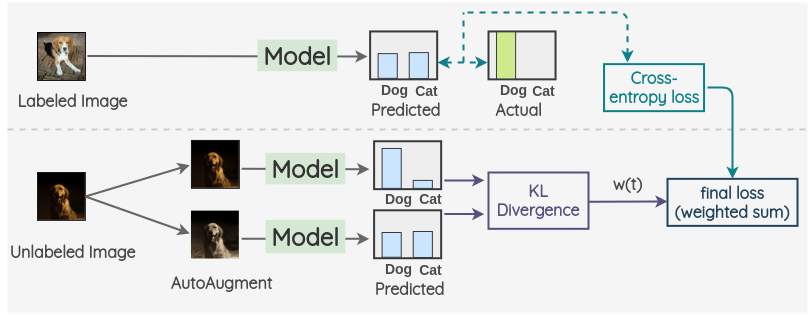
3、混合方法
这个范例结合了来自过去的工作的想法,例如自我训练和一致性正则化,以及用于提高性能的其他组件。
a. MixMatch
这种整体方法是由Berthelot 等[8]提出的。
为了理解这个方法,让我们看一看每个步骤。
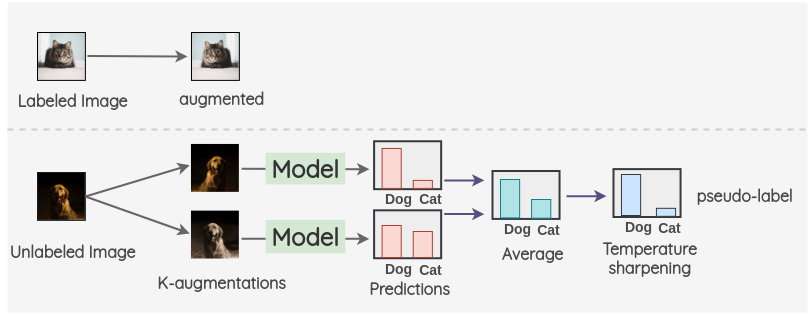
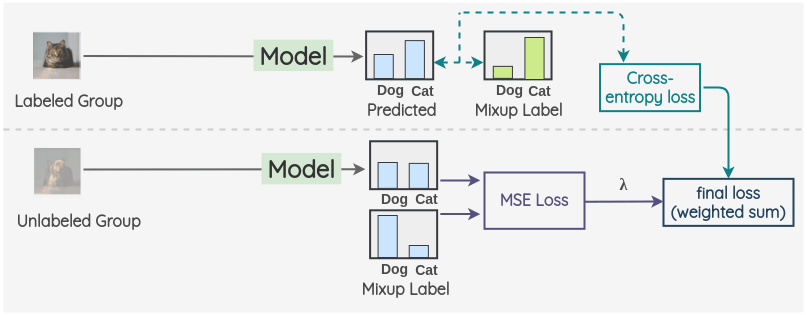
i. 对于标记了的图像,我们创建一个增强图像。对于未标记的图像,我们创建 K 个增强图像,并对所有的 K 个图像进行模型预测。然后,对预测进行平均以及温度缩放得到最终的伪标签。这个伪标签将用于所有 k 个增强。
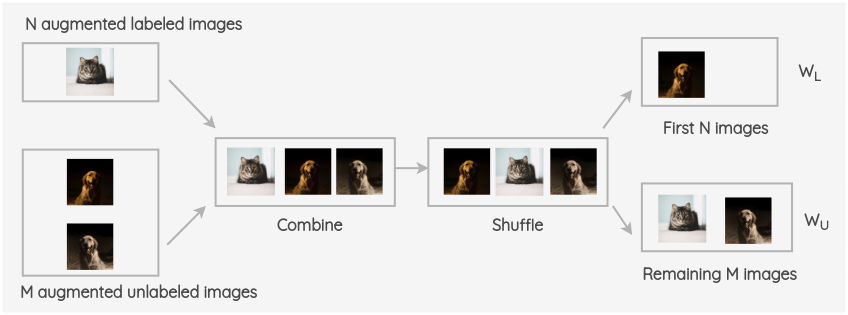
ii. 将增强的标记了的图像和未标记图像进行合并,并对整组图像进行打乱。然后取该组的前 N 幅图像为 W~L~,其余 M 幅图像为 W~U~。
iii. 现在,在增强了的有标签的 batch 和 W~L~之间进行 Mixup。同样,对 M 个增强过的未标记组和 W~U~中的图像和进行 mixup。因此,我们得到了最终的有标签组和无标签组。
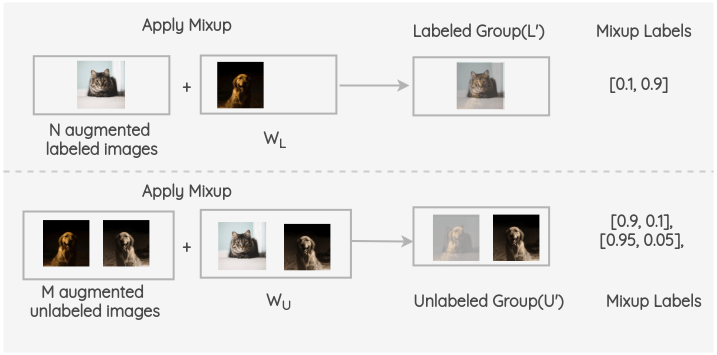
iv. 现在,对于有标签的组,我们使用 ground truth 混合标签进行模型预测并计算交叉熵损失。同样,对于没有标签的组,我们计算模型预测和计算混合伪标签的均方误差(MSE)损失。对这两项取加权和,用 λ 加权 MSE 损失。
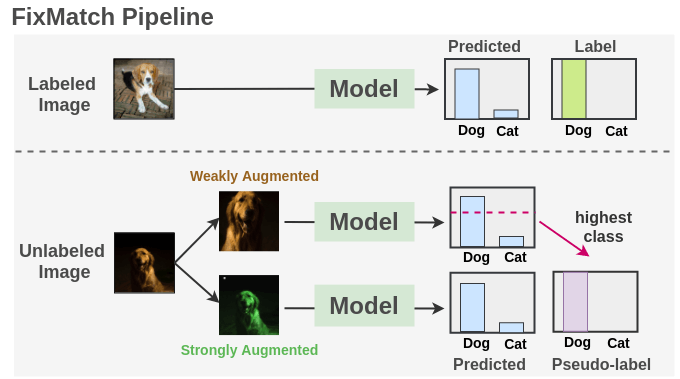
b. FixMatch
该方法由Sohn 等[9]提出,结合了伪标签和一致性正则化,极大地简化了整个方法。它在广泛的基准测试中得到了最先进的结果。
如我们所见,我们在有标签图像上使用交叉熵损失训练一个监督模型。对于每一幅未标记的图像,分别采用弱增强和强增强方法得到两幅图像。弱增强的图像被传递给我们的模型,我们得到预测。把置信度最大的类的概率与阈值进行比较。如果它高于阈值,那么我们将这个类作为标签,即伪标签。然后,将强增强后的图像通过模型进行分类预测。该预测方法与基于交叉熵损失的伪标签的方法进行了比较。把两种损失合并来优化模型。
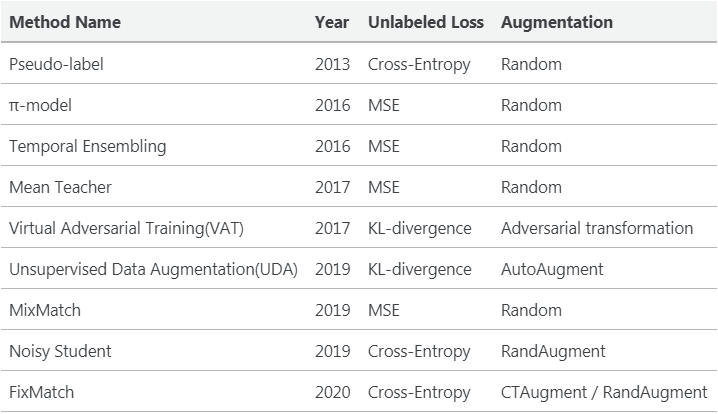
不同方法的对比
下面是对上述所有方法之间差异的一个高层次的总结。
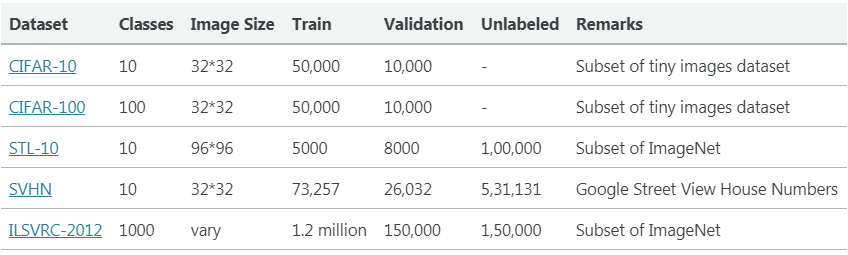
在数据集上的评估
为了评估这些半监督方法的性能,通常使用以下数据集。作者通过仅使用一小部分(例如:(40/250/4000/10000 个样本),其余的作为未标记的数据集。
结论
我们得到了计算机视觉半监督方法这些年是如何发展的概述。这是一个非常重要的研究方向,可以对该行业产生直接影响。
参考资料
[1]Dong-Hyun Lee: http://deeplearning.net/wp-content/uploads/2013/03/pseudo_label_final.pdf
[2]Xie等: https://arxiv.org/abs/1911.04252
[3]Laine等: https://arxiv.org/abs/1610.02242
[4]Laine等: https://arxiv.org/abs/1610.02242
[5]Tarvainen等: https://arxiv.org/abs/1703.01780
[6]Miyato等: https://arxiv.org/abs/1704.03976
[7]Xie等: https://arxiv.org/abs/1904.12848
[8]Berthelot等: https://arxiv.org/abs/1905.02249
[9]Sohn等: https://arxiv.org/abs/2001.07685
英文原文:https://amitness.com/2020/07/semi-supervised-learning/
本文转自: AI公园(ID:AI_Paradise),原作者:Amit Chaudhary,编译:ronghuaiyang,转载此文目的在于传递更多信息,版权归原作者所有。





