本文系微信公众号《大话成像》,知乎专栏《all in camera》原创文章,转载请注明出处。
原文链接:https://mp.weixin.qq.com/s/RBNBZK3UHCarT8G11LCz6w
相机的基本任务是获得图像,而图像的含义则需要computer vision(CV)技术来提取。
现在的相机越来越多地引入计算视觉技术来丰富相机的用户体验,最近在神经网络与深度学习技术方面的进展大大提升了计算机视觉技术的性能,尤其是以下的9个典型CV技术与应用,使得相机不再停留在传统的成像(imaging)层面,已经进化到了感知(sensing)世界的新时代。
1. 图像分类 (image classification)

图像分类的求解目标:给定一组标记好为某个类别的图像,再给一组新图,把这些新图归类,并测量归类的准确性。
那么利用神经网络和深度学习如何解决这个问题呢?
首先,我们要有一个训练集,这个训练集里包含N个图像,每个图像都被标记为某个类别,类别总数为K。
然后,我们用这个训练集来训练分类器,让分类器学习每个类的样子。
最后,我们给分类器新的图,让分类器分类并标记这些新图。我们再人工校对这些图正确性。
目前最流行的图像分类器架构就是卷积神经网络(CNN),典型应用就是把图像灌倒CNN里,CNN会生成图像的类别。
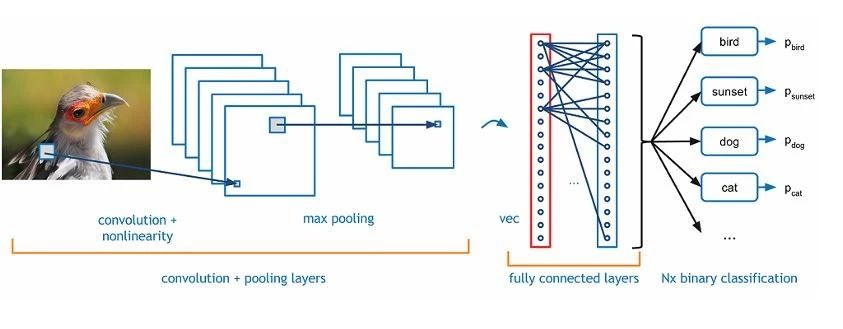
2. 图像分类定位(image classification with localization)
这是增强版本的图像分类,不仅把类别分出来,还把各个图像中的分属各个类别的物体框出来,比如标记出哪些细胞是癌细胞组织,哪些是正常的细胞。这种技术也有人把它归到目标检测这个类别里。
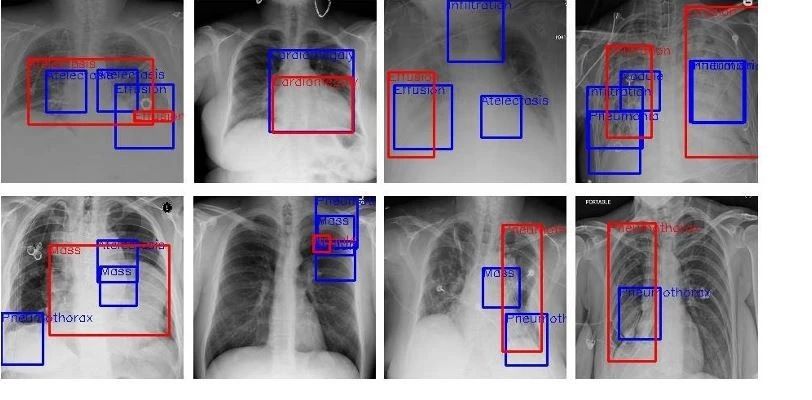
3. 目标检测(object detection)
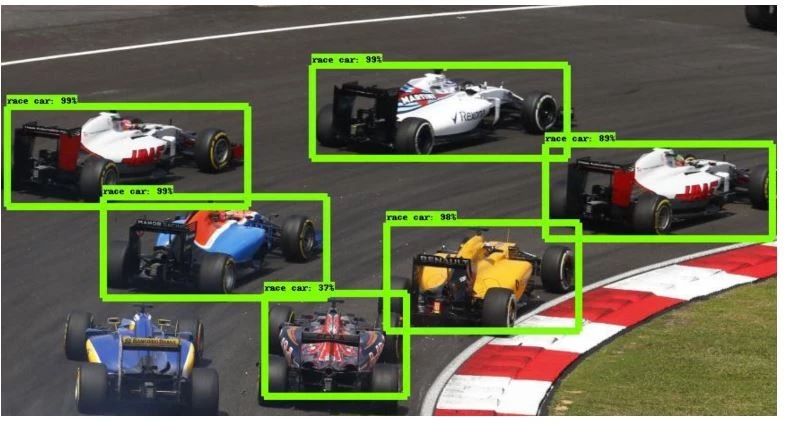
把目标从图像里检测并框出来具体位置,然后标记出来,这就是目标检测技术。学界一般把单一目标检测,比如上图所示,车辆检测,归到目标检测技术,把多目标检测,定位,归到图像分类定位这个门类里。
目标检测不能用单纯的CNN技术,因为在‘图像分类与定位’技术中常用的滑窗法(sliding window)+CNN需要把图像crop出来送进CNN,这种方法CNN需要处理太多的crop图像来分类目标与背景,计算消耗太大。于是研究员设计了R-CNN(region-based-CNN)来加速目标检测,R-CNN先是用一种叫做‘selective search’的算法把图像扫一遍,寻找可能存在物体的区域,然后产生大概2000个‘计划区域’,把这些计划区域送到CNN里跑。最后,把CNN的结果在送到SVM来做分类,再用线性回归(linear regression)来把物体准确地框出来。
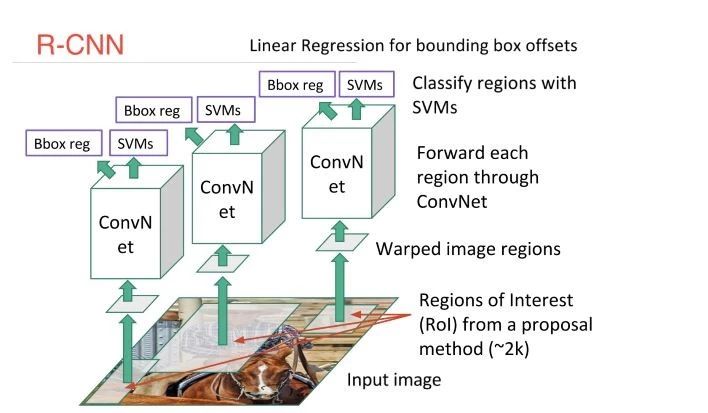
基于R-CNN又衍生出fast-R-CNN,以及faster-R-CNN技术,总之是为了更加‘多快好省’地进行目标检测。最新的技术有YOLO,SSD,R-FCN,他们都着力在避免使用不能共享的算法解决各个子问题,因为这种各自隔离的算法会导致训练时间的延长与网络精度的下降。
4. 目标跟踪 (object tracking)

目标跟踪是指一直跟随场景内的一个或多个特定目标。目标跟踪最早是在雷达系统中经常使用的一个技术,比如发现入侵飞行物,然后标记并跟踪这些飞行物。现在这个技术是自动驾驶系统里的一个关键技术,Uber和Tesla这些公司都有不少目标跟踪的技术专利。
依据观测模型来分,目标跟踪的方法有两种,一种叫通用法(generative method),一种叫有区别法(discriminative method)。通用法比如PCA算法用通用模型来描述目标特征,并且用最小重建误差的方法来搜索目标。有区别法可以用来区分目标和背景,性能更加健壮,所以逐渐变成了目标跟踪的主要方法。这种方法也被称作tracking by detection--检测出所有的候选目标,然后用深度学习的方法把真正的目标挑选出来。现在最流行的是基于SAE(stack auto encoders)技术的DLT(deep learning tracker),这种方法要预先离线训练,然后在线fine tune。
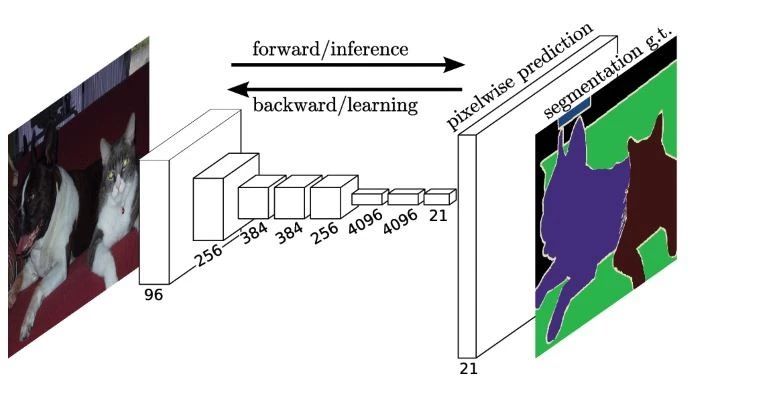
5.目标分割(Object segmentation)
目标分割(Object segmentation或者semantic segmentation)的任务就是把检测到的某目标从图像中把其所有像素分离出来,而目标检测只是画个框,框出来就可以了。

从上图可以看到,人,动物,车辆,雨伞,书包,都被‘pixel level’地标记出来。基于CNN的衍生算法在目标分割上非常成功,比如UC Berkeley提出的FCN(Fully convolutional network)。最开始用来做图像分割的patch CNN算法因为逐像素做分类,而且不重用重叠部分的特征,效率太低,被放弃了。为了加快速度,FCN方法在网络里把图像downsamping,再upsampling,这种方法速度快,但是缺点就是分割有些粗糙。所以后来图像分割算法在这方面做了大量的改进,比如Segnet等方法。
6. 风格转换 (style transfer)
照片从一种风格被转换成另外的一个风格。
如下图,照片从写实风格变成了梵高风格。

2016年,德国的Tubingen大学的研究员用CNN实现了这种照片风格转换的功能,在CVPR2016的会议上发表了他们的论文。
有人把这种方法应用在人像上,于是得到了毕加索,梵高,莫奈风格的蒙娜丽莎。

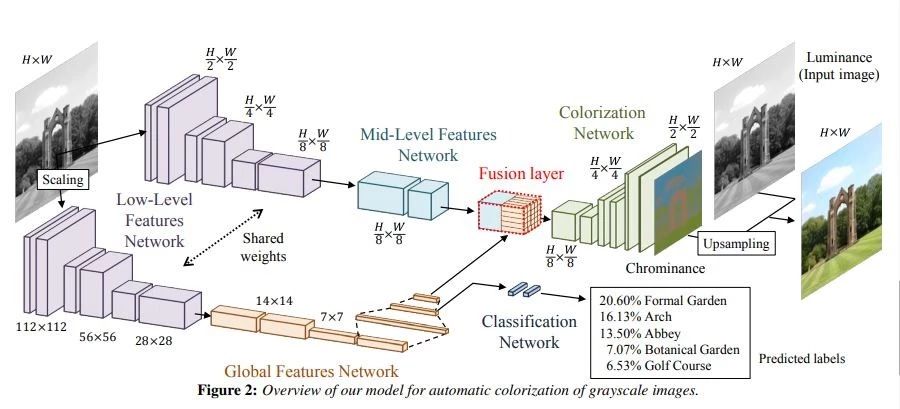
7. 图像上色(image colorization)
把老的黑白照片变成彩色照片,这确实是个很有意思的应用。

日本早稻田大学的研究员在2016年发表了基于‘端到端深度学习’方法给图像自动上色的论文。
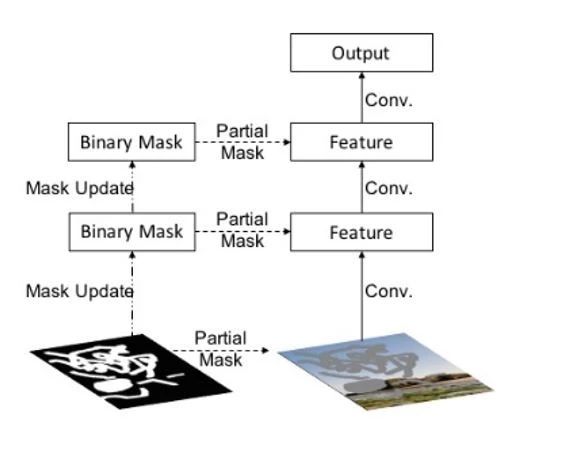
8. 图像复原(image reconstruction)
有的照片被破坏了,这时候就需要用图像复原(image reconstruction)技术修复。
NVidia的研究员在ECCV2018 发表了这篇论文《Image Inpainting for Irregular Holes Using Partial Convolutions》。
以往基于CNN的照片修复都会产生颜色差异或者模糊,如下图

因为传统方法将正常pixel和被破坏的pixel都用同样的方法扔到CNN里处理,所以这种方法提出Partial convolutions,也就是传到CNN的时候配一个Mask,告诉CNN哪些pixel是被破坏了的,可以实现更为精准的修复。
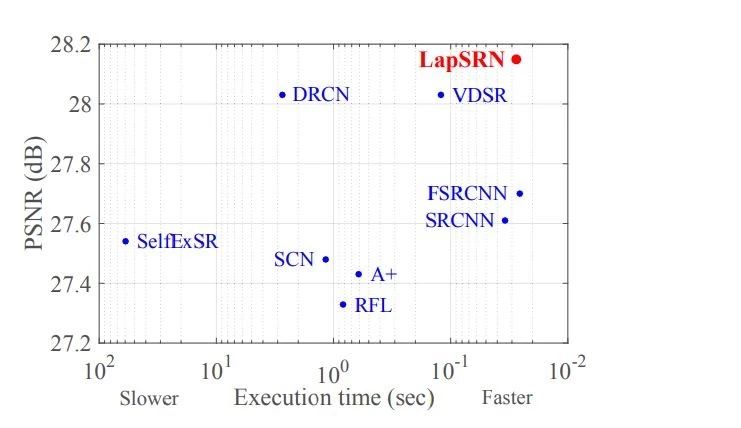
9. 图像超分辨率(image super-resolution)
超分辨率就是基于原图,产生出更高分辨率,更清晰的图像。
超分辨率这个技术已经火了很多年,2011年nokia发布4100万物理像素的手机相机,很快就有竞争对手用超分辨技术实现所谓更高像素,号称自己的相机是5000万像素的。现在有的手机相机利用超分辨率技术实现super zoom这种应用,号称相机可以实现50x的变焦。如下图,左边牌子上的字母,经过四种超分辨率技术得到明显不同的结果。

利用CNN实现超分辨率是现在的热门方法,2018年加州大学的研究员在CVPR上发表的《Deep Laplacian Pyramid Networks for Fast and Accurate Super-Resolution》据说是目前速度和精度上最好的单帧超分辨率算法。如下图,LapSRN是PSNR最高且运行速度最快的。
本文系微信公众号《大话成像》,知乎专栏《all in camera》原创文章,转载请注明出处。
原文链接:https://mp.weixin.qq.com/s/RBNBZK3UHCarT8G11LCz6w





