简介
在几乎所有现代化汽车上,数字仪表盘从某种形式上来说属于标准功能,它们第一次出现是在20世纪80年代,最近几年它们又重新流行起来,这在很大程度上要归功于现代GPU更加强大的图形功能。虽然低配的汽车可能只有里程计算的数字显示,但是高端车型则设计了完全数字化的仪表盘,包括表盘。
相比传统的物理显示,完全数字化的仪表盘有很多的优势,提供的信息更加的精确、精细甚至更加的清晰。它们可以调节并且动态显示,准确的显示驾驶员可能随时需要看的信息,甚至还可以自定义显示从而满足驾驶员的个人喜好。它们的外观也更加的时尚、现代化,这也是吸引车主的原因。
但是在我们的研究中,我们发现数字仪表盘因为几何图形的原因设计得并不是很好,因此无法有效的利用嵌入式GPU的性能,这导致在选择GPU时做出糟糕的决定,供应商错误的认为小型的GPU无法胜任这样的需求从而指定其他硬件。
因此当我们在开发汽车组合仪表时,我们的主要目的是展示在不影响质量的情况下如何可以高效的对汽车仪表进行渲染,例如使用最小型的PowerVR Series8XE内核。

在本白皮书中,我们将会列出各种相关的优化技术,目的是确保汽车仪表盘设计师能够充分利用他们所采用的硬件。并非所有列出的技术都在我们开发仪表盘过程中都使用过,要么是出于设计原因,要么仅仅是因为达到了性能和质量的要求。但是由于某些实际应用程序可能会更加的复杂,我们还介绍了其他一些有用且必要的技术。
1 组合仪表盘用户界面(UI)
1.1 表盘的渲染
因为表盘是圆形的,想渲染得很好往往是有一定难度的。要实现完美的圆形通常是向网格中添加更多的三角形(几何),直到看起来足够的好为止。这种方法在大型且离散的GPU上运用效率是非常低的,因此,对于在汽车上通常采用的小型嵌入式GPU上是不建议这样做的,因为这意味着几乎不可能实现良好的性能。幸好有一些明智的解决方案可以将性能提升到可接受的水平,而无需去降低质量。
对于表盘来说,实际上很容易用一个四边形近似实现:alpha透明度可以使其变为圆形,而法线贴图可以实现表面细节的错觉:
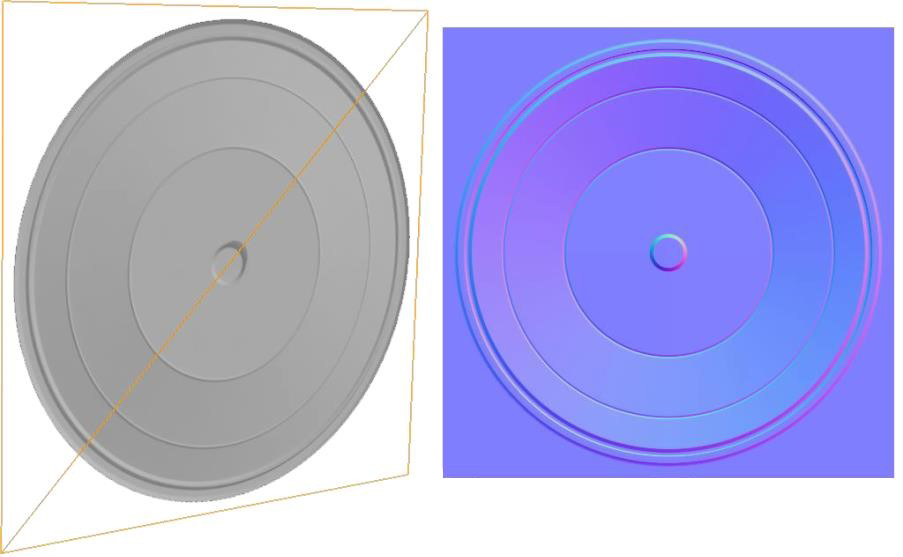
显然这是首选的集合方法,但是从透明度利用而言这确是一种浪费:中心是完全不透明的但也要使用透明度,周围的空白部分是完全透明的也要进行栅格化处理。考虑到法线贴图在分片阶段是非常耗资源的,最好是减少它占用的像素数。
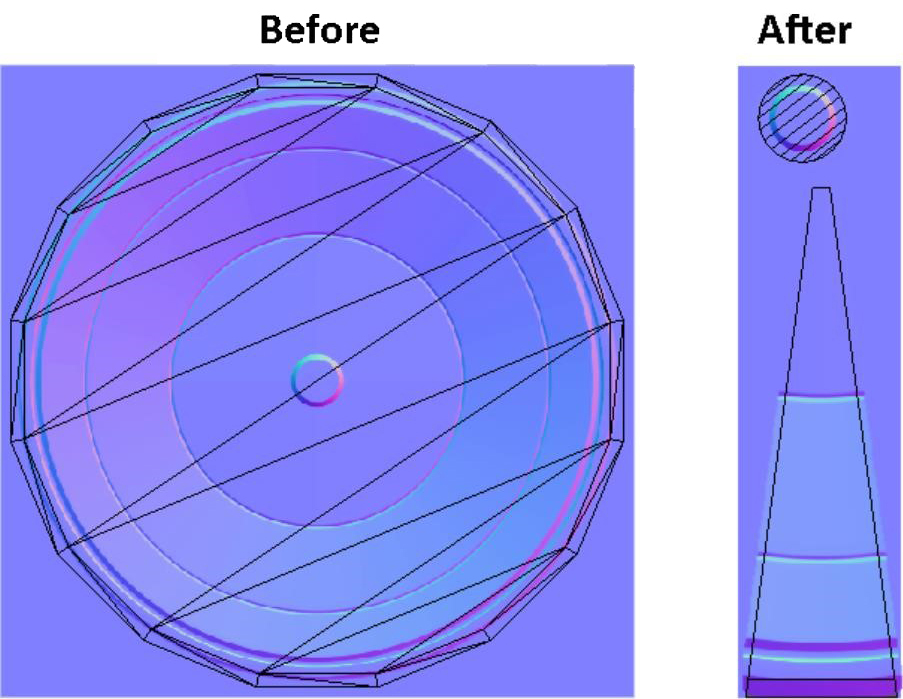
不用太夸张的缩小几何图形而是近似接近表盘形状几何,对于这个复杂几何形状我们可以划分为两个网格,中央部分是不透明的(有助于减少场景透支),外围使用alpha混合处理(使其形状变得更圆)。

对法线贴图和切线有了一些了解之后,我们可以做一些事情进一步提高纹理的利用率。本质上不是将整个形状烘焙为纹理,我们仅提取楔形的法线贴图,然后将其循环复制。因为法线贴图与切线是相对的,切线会随着几何形状旋转,从数学角度证明这是对的,一切都如期望的那样。

在这里使用alpha混合的一个巧妙的副作用是我们可以稍微修饰表盘的边缘,轻松的去掉锯齿。下图是不同MSAA(多重采样抗锯齿)情况下的对比:

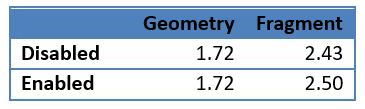
为了证明该技术在性能上是可行的,我们已经在其中一款最小型的GPU(PowerVR GE8300)上进行了测试,并且使用PVRTune工具比较了性能。测试场景包括相同的表盘网格,以1080P的分辨率每帧重复24次。

下图来自我们的PVRTune性能分析工具,显示的是在进行渲染时GPU的时间是如何分布的。下面的方框代表的是执行的任务,根据帧序号用颜色进行了标注。几何任务处理的是包括执行顶点着色器、剔除表面或屏幕外三角形等产生的几何图形。渲染任务代表的是在像素级别执行的操作,例如三角形栅格化、执行像素着色器。
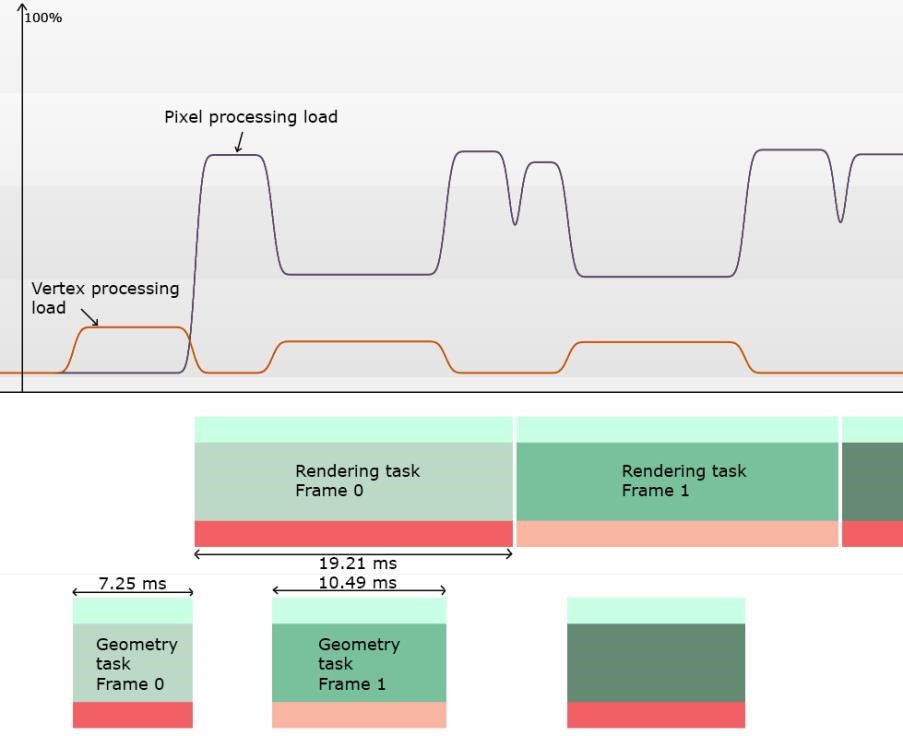
正如预期的那样,即使GPU相当多的时间用来处理几何图形,这对移动端GPU来说也仍然是可以接受的。更令人惊讶的是,将几何图形转为像素的时间是19ms。假设目标帧率要求整个帧在16.6ms以内,那么该性能水平是不可接受的,尤其考虑到在这种情况下使用的分片着色器是微不足道的,那么问题来了,究竟是什么原因占用了这么长时间呢?
很简单,光栅化根本无法很好的处理长且细的三角形,从上面的图表中可以看出:像素处理负载计数器显示像素处理时间只有一部分用来执行像素着色器,在正常情况下该值预计将接近100%。然而在这种情况下甚至没有达到60%,这意味着GPU卡住了做其他事情,大多数情况下可能很难将形状不好的几何图形栅格化。
使用4X MSAA(多重采样抗锯齿)情况变得更糟,应用程序性能从50fps下降到30fps,现在以30fps进行全高清(Full-HD)渲染并非不可接受,而且还是很多3D应用程序和游戏的标准配置,但是对于重要的汽车组件我们希望实现更高的目标。
现在我们谈谈优化后的表盘渲染,从外观上看线框似乎很合理,最后一帧看起来很完美。

然而,正如我们从下图中看到的,优化后它能够以完全的V向同步60fps来运行,从而为应用程序中的其他功能和内容提供了空间。
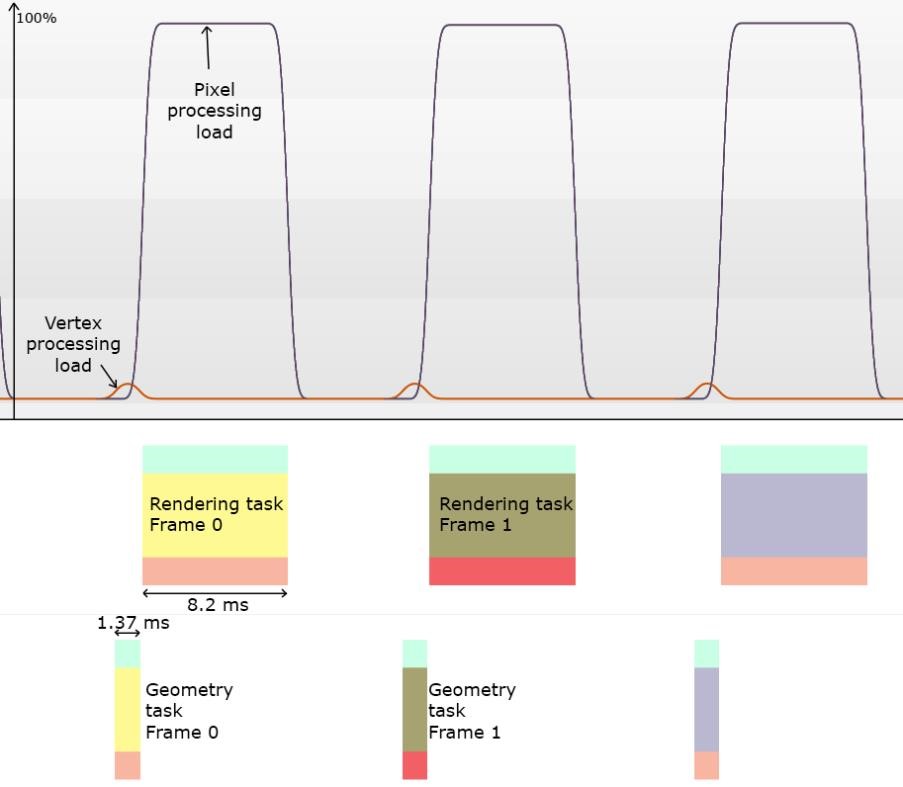
有趣的是,通过为GPU提供更高要求的分片着色器,像素渲染任务现在执行得更快——有时候优化可能与直觉是相反的。
1.2 文本渲染
正如我们在表盘上发现的那样,我们已经看到很多测试程序和应用使用镶嵌几何体来渲染文本,但是原因不清楚。将文本渲染为网格而不是纹理四边形的唯一理由可能与放大纹理时的过滤质量有关。然而事实证明,这个问题在10年前就可以通过DFF(distance field fonts,距离场字体)技术解决了,不受传统的双线性过滤假象所影响,我们建议采用这项技术。


距离场的一般作法是将距离值映射为不透明值,最基本的解决方案就是一个简单的阈值:
// 从纹理中提取距离场值 float dist = texture(sdfTexture, uv).a; // 将距离转换为alpha值 float alpha = step(_BaseThreshold, dist);
通过修改阈值,文本可以变得更粗或更细,这非常有用。“硬阈值”将会导致文本边缘很硬,这无疑是令人讨厌的,而且任何MSAA(多重采样抗锯齿)都无法修复:

但是,这时可以通过非常简单且方便的方法进行补救,将“step”函数换成“smooth step”函数,同时引入一个很小的平滑边距参数:
float alpha= smoothstep(_BaseThreshold-smoothing, _BaseThreshold+smoothing, dist);

虽然这会使放大的文字看起来令人满意,但放大文字从远处看起来效果很差,不过可以通过改变平滑值来修复,这与UV坐标的每个像素的倒数有关,如下所示:
float _BaseThreshold = 0.5; // 修改此值可使字体变粗
float _Filtering = 16.0; // 抗锯齿因子
float _MinSmoothness = 0.01; // 接近0的值可使文本更清晰
float _MaxSmoothness = 0.4; // 防止小字体过度模糊
float getFilteringSMoothness(vec2 uv, float intensity, float maxSmoothing)
{
vec2 size = fwidth(uv);
float smoothingBias = min(max(size.x, size.y)*intensity, maxSmoothing);
return smoothingBias;
}
float getOpacity(vec2 uv)
{
// 从纹理中提取距离场值
float dist = texture(sdfTexture, uv).a;
// 将距离转换为Alpha值
float smoothing = _MinSmoothness + getFilteringSMoothness(uv, _Filtering,
_MaxSmoothness);
float alpha = smoothstep(_BaseThreshold – smoothing, _BaseThreshold +
smoothing, dist);
return alpha; 这样可以使图像比使用标准透明字体和几何字体这两种方法都更加的清晰(如图10),这项技术不仅可以用于字体,而且适用于任意类型的2D UI元素,此外,这也是面向未来UI的好方法。当使用传统纹理时,渲染分辨率大幅提高,UI元素的分辨率也要进行类似的提升,这样才能都有更好的效果,但无论如何放大距离场都可以保持清晰度,因此提高分辨率不是问题,而且不需要其他额外的操作。
在性能方面,相比传统纹理,DFF性能更好,但它仍然比过度细分的网格渲染的更快。
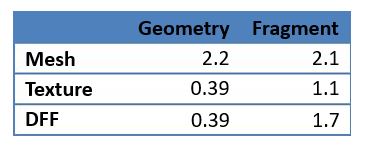
在性能测试中,全几何文字使用3dsMax默认设置创建(包括基础的网格优化),纹理字体由单个四边形字符组成,对比结果如下图:

和表盘一样,采用简单的透明度方法而不是复杂的不透明网格可以显著的提升性能。基本的纹理可能不适用所有情况,例如一个文本元素被放大,使用DFF方式可以以非常低的代价缓解所有过滤问题。
1.3 使用预乘的alpha值将CPU的开销最小化
有时有必要将alpha混合与相加混合一起使用,在我们的案例中就是这样做的,因为我们有霓虹灯设计——主要元素使用alpha透明度,周围的辉光采用相加混合的方式来实现。

传统上你必须分两次进行渲染,引入GL状态变量,实质上让绘图调用次数翻倍。对于大多数应用来说这不是一个重要的问题,但是该解决方案非常简单,值得一提的是预乘alpha值,只需要一个GL状态变量就可以创建:
glBlendFunc(GL_ONE, GL_ONE_MINUS_SRC_ALPHA);
这在软件方面是必需的,下一步是创建纹理并利用。

RGB通道应该包含黑色背景以及辉光的常规颜色信息,并且alpha层应该仅代表图标的不透明部分。完成后辉光像素会彼此融合,而alpha层会正确覆盖背景。这意味着现在可以直接渲染大部分UI元素,无需引入其他状态或着色器。
2 汽车渲染
随着仪表盘用户界面(UI)的发展,现在是时候解决最具挑战的部分了:在一款小型的嵌入式GPU上渲染整个车身,并细节化处理。
精细的汽车模型要可以从不同的角度环绕查看,驾驶员可以在仪表上看到他们的汽车模型,以及车辆周围的真实场景,这要借助车载摄像头、雷达或者激光雷达(LiDAR)。汽车厂商以及车主都希望仪表上显示的是真实的车辆,越精确越好,而不是简单的汽车模型。与表盘上的文本一样,在汽车渲染问题上省去很多的三角形无疑是一种简便的方式,但是想要获得更好的效果还有更好的方法,下面我们来详细介绍一下。
2.1 纹理的一些技巧
鉴于纹理在解决UI几何瓶颈方面取得的成功,由此推测它们在其他方面也会非常有用。以这个看起来还不错的汽车内饰为例。

但是这是通过简单的纹理技巧实现的,使得实际的几何形状非常简单。这是怎么实现的呢?这是法线贴图与烘焙光照的简单组合,可能需要花费一定的时间来创建,但是带来的成果确实巨大的。
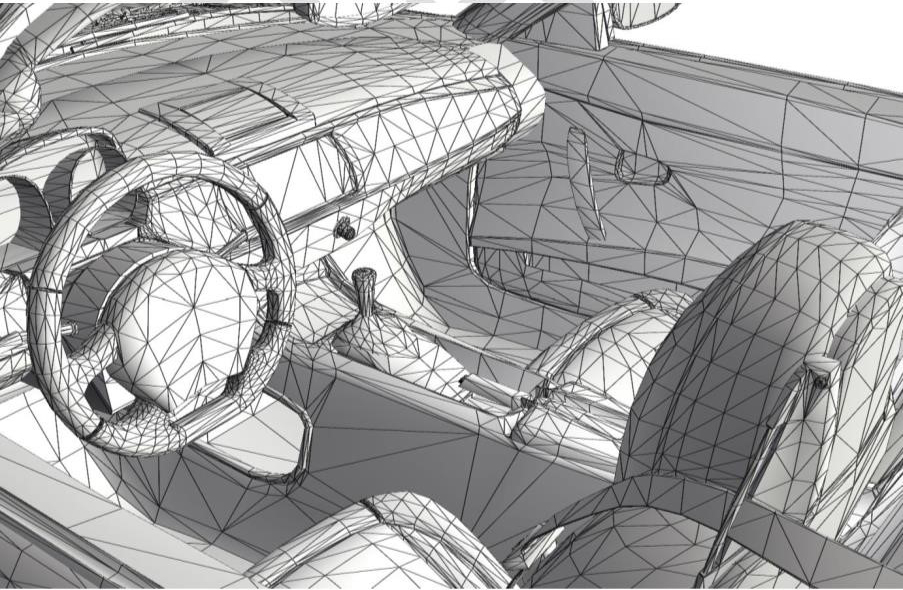
最明显的想法是将小的细节绘制到纹理中。然而这种方法的结果不足以让人信服,必须更进一步让纹理可以控制光照。
2.1.1 法线贴图
法线贴图是降低仪表盘渲染成本的便捷方法,不幸的是应用到汽车时,我们遇到两个主要的问题:
① 汽车是三维的(与表盘不一样,表盘几乎是平的),如果要让车体的轮廓非常的光滑,则需要非常密集的网格。
② 法线贴图在精度上是有限的,包括纹理精度以及深度精度,这会导致纹理外观并不理想以及出现一些条带状的假象。

这是否意味着我们应该完全忽略法线贴图呢?绝对不是!它们在很多地方都非常有用,不仅仅是汽车车身。
例如在仪表案例中,我们将车轮压缩到其原始尺寸的1.5%,而且没有明显的质量损失:

2.1.2 烘焙光照(Baked Lighting)
将高质量的网格光照投射到用于渲染的较低质量对象上是仿造细节的另一个好方法。环境光遮蔽(Ambient Occlusion)通常是首选的照明方式:它完全可以取代动态光照,甚至可以更好的提升动态光照,减少几何图形的散光程度,在场景中创建让人舒服的柔和阴影。

环境光遮蔽(Ambient Occlusion)用于漫反射以及反射效果调试是非常有效的,而且通常也是非常有用的工具。

2.1.3 插曲:UV管理
如果将整个车身转换成纹理(大概是带有环境光遮蔽的情况),那么需要进行完全的UV展开。但是车体是相对比较大的对象,使用4K纹理囊括所有的细节,这在数量上是有限制的。好消息是车身是对称的,而且环境光遮蔽是完全独立的。这意味着车身一侧的UV可以与另一面的重合,合并成一个,从而可以节省大量的纹理空间。如果我们可以提前知道车身的哪部分不需要细致的渲染,我们也可以缩小这部分UV,把空间分给更重要的部分。
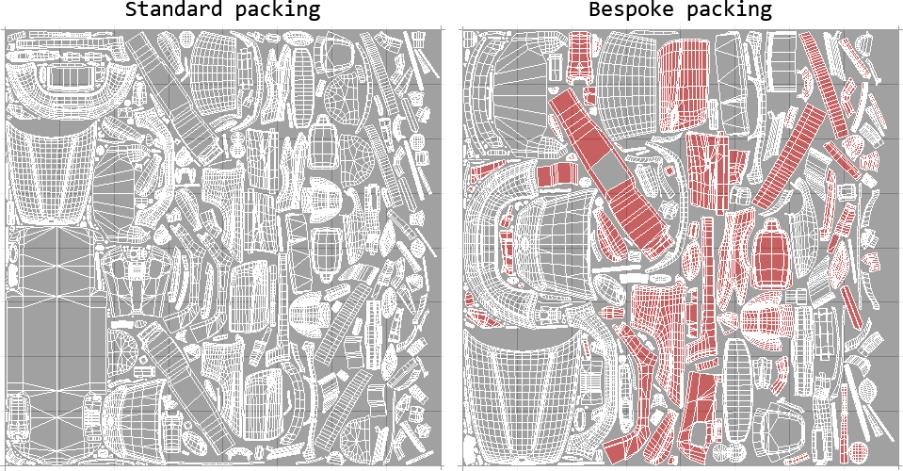
2.1.4 浮动
还需要渲染最小的按钮,螺钉和螺栓?好吧,这里有一个非常简单的方法,可以处理超级小和重复的细节,而不用创建超大的纹理资源。这个方法通常称为“浮动”——创建包含很多细节的纹理组合,在原始网格上渲染一层透明的网格。


显而易见,由于所有细节都在法线贴图中模拟,因此优化后的版本缺乏深度,除了这个缺点,它与整个模型对于光照和反射的方式是一样的。
注:在上面的示例中,此优化版本的1138个三角形中,超过1000个用于金属旋钮,这显然是浪费,应该进一步优化。

由于这些元素都是重复和映射的,纹理空间中它们是最小化的,如下使用“浮动”方法的256 x 256分辨率的法线贴图所示:

为了变得更好,从一定距离来看纹理技巧往往非常稳定,仅限几何图形的系统肯定不是这种情况,如下图所示,呈现了难以接受的不同级别的锯齿现象:

从静止图像上看起来可能很差,但是在动态情况下会下降一个数量级,尤其是当大部分像素以非常激进且分散的方式进行闪烁。
使用8倍MSAA可以极大的改善,但是不够完美,鉴于这种技术的成本,这实在令人遗憾:

然而,采用基于纹理的解决方案,相比MSAA我们可以获得更清晰的图像,并且运动时的稳定性接近完美。

2.2 几何的一些技巧
现在,我们已经整理好了车内部分和一些小的细节,我们仍然需要解决最大的问题:车身。考虑到它定义了汽车的轮廓,因此显然需要比其他部分的几何图形要更加的密集。

2.2.1 改善法线
有趣的是,在某种程度上,由3D艺术家设计的很多几何图形是不必要的:现代工具和渲染管道在过去几年中已经取得了很大的发展,但是一些旧的习惯已经不适宜了,如果还遵循过时的最佳做法,最终效果可能适得其反。
举个这种不良作法的例子,在几何图形中添加支撑边来改善法线差值,当制作工具可以完全引入法线时,这很有意义,也有可能根本不产生平滑的边缘或者边缘非常粗糙。在差值边缘添加支撑边可以帮助按需要的方式确定法线的方向,从而使光照能够更紧密的匹配密集网格的外观。
但是任何现代且好用的制作工具都应该支持局部加权法线,无需额外的几何图形就可以产生非常好的效果。下图显示了局部加权法线与密集网格阴影效果的匹配程度:

为了处理得更好,因为所做的只是改变法线的计算方式,因此不需要消耗性能,也不需要任何工程操作就可以集成到渲染器中。
尽管它们可以帮助消除很多网格中存在的一些边缘环,但是局部加权法线不会以任何方式解决轮廓的问题,所以我们仍然需要数量相对较多的三角形来实现。
2.2.2 几何格式
表面上虽然是这样,但是有很多方法可以使用PowerVR SDK工具来降低几何图形的渲染成本,PVRGeoPod可用于3D创作程序包的导出,它是最受欢迎的场景导出工具,可以用来微调几何图形的表示方式。
我们需要查看的第一个选项是索引。有了索引就可以通过索引缓存访问三角形的顶点,这个缓存可以让同一个顶点使用多次,从而避免复制多个三角形顶点的需要。我们在PowerVR GE8300 GPU上进行了测试,显示从标准的三角形列表转换为索引列表使得顶点处理的性能翻倍。
接下来是容易忽略但又很容易解决的问题:三角形和顶点排序。这里的目的是最大程度利用缓存,即确保我们不会遍历内存获取所有几何图形数据,而是尽可能采用最佳连续的方式对其进行排序。虽然不像索引一样尽如人意,但是对三角形和顶点进行排序确实提升了27%的性能。
2.2.3 剔除和细节程度
通常最好不要将不必要的工作提交给GPU来处理,尽管PowerVR基于分片的延迟渲染(TBDR)架构非常适合降低阴影隐藏几何体的着色成本,但是GPU仍然必须先处理所有的顶点,如果知道某个物体对象(被遮挡或在屏幕外)不会影响图像的质量,那么不应该提交给GPU来处理。
小的三角形(仅占用几个像素)往往会破坏GPU的并行性,因此会增加性能成本但是几乎没有视觉差异。避免这种情形的常用方法是使用不同层次几何密度的网格,根据它在屏幕的尺寸渲染最相关的部分。这对于车身渲染不是很有用,因为车身在尺寸上不会出现千差万别的现象,但是对于一些潜在的更小元素仍然是非常有用的。
2.3 清理渲染
锯齿现象通常是不可接受的,MSAA(多重采样抗锯齿)是常用的方法,可以减轻其影响。但是通常将采样数量设置为硬件支持的最大值,这样会导致图像质量提升有限同时性能急剧下降。
为了正确的消除锯齿,我们必须知道原因,仅仅认为它只是源于几何体边缘的失真,这种认识是非常浅显的。我们应该考虑以下几种锯齿类型:
2.3.1 纹理锯齿
可能是最容易修复的一种:对所有的纹理进行mipmaps(多级映射)处理,这可能导致一些纹理过于软化,使用各向异性过滤通常是修复这种问题的建议做法,这种方法更加的正确,但是代价也更高一些,因此需要慎重的考虑。代价更低的方法是为纹理指令引入第三个参数,简单的进行mipmap层级估计从而降低这种现象。
lowp vec3 colour = texture(tex, uv, -1.0).rgb;
2.3.2 几何锯齿
在这种情况下,MSAA是处理这种问题的正确方式,它本身就是非常的精确。虽然可以解决这种问题,但是代价比较高尤其是采样数量高,因此对于低端设备应避免使用2x MSAA。这听起来很严格,但是如果你已经采用了前面提到的所有小技巧,那么车身的细节部分应该已经非常清晰了。
FXAA(快速近似抗锯齿)是另一种可能性,它采用后处理方式对高对比部分(即可能是由锯齿引起的)进行了模糊处理,与MSAA不同,这种方式不会使图像清晰,但是确实能够让图像看起来更干净。适中的图像质量带来的好处并不一定会超过图像质量的损失,在MSAA基础上使用它可以产生更清晰的图像。还应该指出的是文本应该在FXAA(快速近似抗锯齿)后进行渲染,否则产生的模糊效果会使其可读性大大降低。

2.3.3 阴影锯齿
这种类型的锯齿稍微更复杂一些,产生的原因也更多。可能是着色器的条件控制导致相邻像素间的不连续或更可能是高频的表面细节导致像素光照和反射情况的急剧变化。
对于车身的渲染,大量的金属表面或非常光亮的表面将会在一些小的部位或弯曲的区域产生大量的锯齿,基于局部曲率可以减少反射的平滑度,如本演示中所解释的那样(幻灯片43)。



阴影锯齿在改善反射效果上是有效的,计算成本是非常低的,而且也容易实现。
该技术非常适合中等密度的网格,比如车身。对于其他网格若采用基于纹理的工作流程,也可以保护高质量网格的曲率使用低分辨率,使用它来偏置表面的反射率,从而避免高频反射的不稳定性。



对于其他类型的锯齿,FXAA(快速近似抗锯齿)应该能够消除它们。作为图像的过滤器它通过单程着色能够清除所有类型的锯齿
3、结合在一起
我们这个仪表板案例最重要的设计决策是将渲染的中心部分(比如3D车身)划分为单独的渲染目标。这出于以下原因:
1. 它支持复杂的过渡变换(缩放、平移、淡入淡出等)
2. 与仪表板UI不同,中心部分需要一系列的抗锯齿处理,若应用到整体会非常的浪费
3. 如果没有任何变化,则可以渲染暂停缓存(尽管我们实际上并没有使用过,因为我们想展示GPU的性能极限)或者在不同的频率下运行
4. 可以按不同的分辨率渲染,从而可以在一系列GPU上进行不同的缩放处理(出于类似的原因实际上我们也未使用)
移动端GPU适用于对带宽敏感的场合,因此对于大型且单独的渲染目标,渲染成本是非常高的。第一步(也是最显要的)是使整个渲染带宽的成本最小化,确定好合适的带宽:如果中心部分只占显示的一半尺寸,那么按照一半的分辨率进行渲染效果也是非常明显的。
但是最重要的是告诉GPU需要写入或读取哪些内容,这部分很容易就会被忽视,因为关于渲染的大部分规则最是针对台式机GPU设计的,它们不需要考虑这一点,只有最新的图形API提供了适当的机制。
对于典型的渲染操作每一帧都应该做的两件事:
1) 开始时清除之前的所有渲染
2) 在每一帧的末尾告知驱动程序舍弃深度缓冲区的内容
glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT);
// 渲染操作执行到这里
…
GLenum depthAttachment = GL_DEPTH_ATTACHMENT;
glInvalidateFramebuffer(GL_FRAMEBUFFER, 1, &depthAttachment);
这种简单的结构将大大减少渲染到纹理的带宽成本,而且在运行应用程序时能够大大降低功耗。
4、结论
在面积优化的嵌入式平台上实时运行高质量的图形内容是具有挑战性的,我们已经展示了一些技术用于创建高度详细且高效的仪表盘,其中一些技术对于其他应用案例也是非常有用的。每个项目都是不同的,因此并非此处列出的所有技术都相关或者适用,但它们通常为实现效率提供合理的基础。近年来移动端图形技术已经走了很长一段路,尽管嵌入式GPU比台式机版本小很多,但是它们支持的特性是可以比拟的,这意味着我们在对移动端优化时轻松的找到灵感,这些技术在游戏行业已经应用了很多年,支持最新工具和渲染技术的现代化流程可以在更高的帧速率情况下渲染的质量更好。
PowerVR SDK为你提供合适的工具,帮你了解在GPU内部到底发生了什么,对于特定平台上的特定应用这些工具帮助你形成自己的见解,确定哪些建议是切实可行的。
最重要的一点是记住大多数优化指导都会对一些应该避免的作出严厉明确的声明(比如“不要使用透明度”、“着色器代价很高,要保证它们尽可能的小”),虽然这些建议还不错,但应用还是要谨慎,不要盲目的认为采用复杂的技术就能够带来更好的结果。本文给出的例子就很好的说明了这一点。尽管使用透明度和复杂的着色器通常是不建议的,但是采用它们来渲染刻度盘证明是非常出色的决策。
声明:本文为原创文章,转载需注明出处及原文链接,否则,本网站将保留追究其法律责任的权利。





