1、什么是池化?
我们之所以使用卷积后的特征,是因为图像具有“静态型”的属性,也就意味着在一个图像区域的特征极有可能在另一个区域同样适用。所以,当我们描述一个大的图像的时候就可以对不同位置的特征进行聚合统计(例如:可以计算图像一个区域上的某个特定特征的平均值 or 最大值)这种统计方式不仅可以降低纬度,还不容易过拟合。这种聚合统计的操作就称之为池化,或平均池化、最大池化。
2、池化的作用?
(1)保留主要特征的同时减少参数(降低纬度,类似PCA)和计算量,防止过拟合
在通过卷积获得了特征 (features) 之后,下一步用这些特征去做分类。我们可以用所有提取到的特征去训练分类器,但是这样计算成本比较高。例如softmax分类器,例如:对于一个 96X96 像素的图像,假设我们已经学习得到了400个定义在8X8输入上的特征,每一个特征和图像卷积都会得到一个 (96 − 8 + 1) * (96 − 8 + 1) = 7921 维的卷积特征,由于有 400 个特征,所以每个样例 (example) 都会得到一个 892 * 400 = 3,168,400 维的卷积特征向量。学习一个拥有超过 3 百万特征输入的分类器十分不便,并且容易出现过拟合 (over-fitting)。
(2)invariance(不变性),这种不变性包括translation(平移),rotation(旋转),scale(尺度)
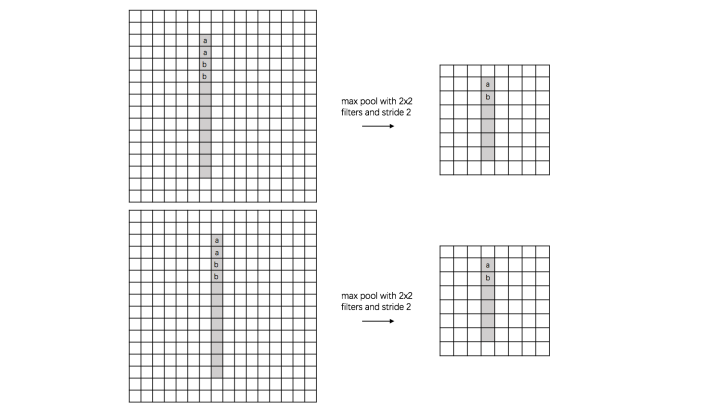
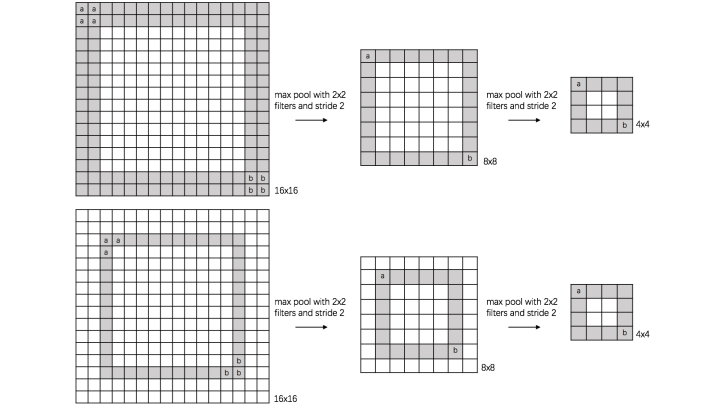
a、 translation invariance:
这里举一个直观的例子(数字识别),假设有一个16x16的图片,里面有个数字1,我们需要识别出来,这个数字1可能写的偏左一点(图1),这个数字1可能偏右一点(图2),图1到图2相当于向右平移了一个单位,但是图1和图2经过max pooling之后它们都变成了相同的8x8特征矩阵,主要的特征我们捕获到了,同时又将问题的规模从16x16降到了8x8,而且具有平移不变性的特点。图中的a(或b)表示,在原始图片中的这些a(或b)位置,最终都会映射到相同的位置。
b、rotation invariance:
下图表示汉字“一”的识别,第一张相对于x轴有倾斜角,第二张是平行于x轴,两张图片相当于做了旋转,经过多次max pooling后具有相同的特征
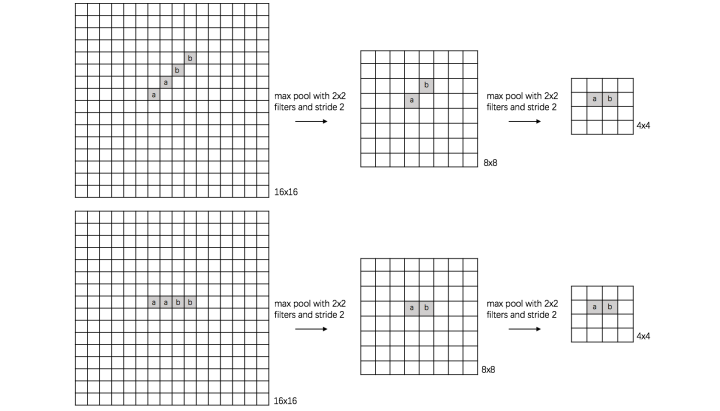
c、 scale invariance:
下图表示数字“0”的识别,第一张的“0”比较大,第二张的“0”进行了较小,相当于作了缩放,同样地,经过多次max pooling后具有相同的特征
版权声明:本文为CSDN博主「cheney康」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/cheneykl/article/details/79873424