在相机和人体同时运动的情况,如何实现基于深度学习的预测?
作者 | Tali Dekel,Forrester Cole
译者 | 苏本如,责编 | 郭芮
出品 | CSDN(ID:CSDNnews)
以下为译文:
人类的视觉系统有非凡的能力,能够让我们从三维世界的二维投影中了解我们的三维世界。即使在具有多个移动对象的复杂环境中,人们也能够对对象的几何结构和深度顺序进行合理的解释。长期以来,计算机视觉领域一直在研究如何通过从二维图像数据中计算重建场景的几何图形来实现类似的功能,但在许多情况下,鲁棒性的场景重建仍然很困难。
当摄像机和场景中的对象都能自由移动时,会出现一个特别具有挑战性的情况。这混淆了传统的基于三角测量的三维重建算法,该算法假定同一物体可以同时从至少两个不同的视角观察到。要满足这个假设,要么需要一个多摄像头阵列(比如Google Jump 360度全景摄像装置),要么需要一个在单摄像头移动时保持静止的场景。因此,大多数现有方法要么过滤掉移动对象(将其指定为“零”深度值),要么忽略它们(导致不正确的深度值)。
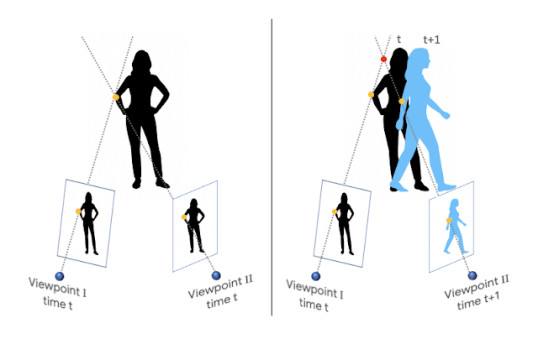
在“通过研究被冻住的人体来学习移动人体的深度预测”(https://arxiv.org/pdf/1904.11111.pdf)的研究中,我们采用了一种基于深度学习的方法来解决这个基本挑战,这种方法可以从普通视频中生成深度图,而在普通视频中,摄像机和拍摄对象都可以自由移动。
该模型通过从数据中学习人体姿势和形状的先验信息,避免了直接的三维三角测量。虽然最近在使用机器学习进行深度预测方面出现了激增,但这项工作是第一个针对相机和人体在同时运动的情况基于学习的深度预测方法。在这项工作中,我们特别关注人体,因为他们是增强现实和3D视频效果的有趣目标。

1、获取训练数据
我们以一种监督学习的方式训练我们的深度预测模型,这需要通过移动摄像头拍摄自然场景的视频,以及精确的深度图。关键问题是从哪里获得这些数据。综合生成数据需要对各种场景和自然人类行为进行真实的建模和渲染,这是一项具有挑战性的工作。
此外,在这些数据上训练的模型可能难以推广到真实场景。另一种方法可能是使用RGB-D深度传感器(如微软的Kinect 3D体感摄像头)来记录真实场景,但深度传感器通常仅限于室内环境,并且有它自己的三维重建问题。
作为替代,我们利用现有的数据来源进行监督学习:YouTube视频中,人们通过冻结各种自然姿势来模仿人体造型,而手持摄像机则在现场巡视拍摄。由于整个场景是静止的(只有相机在移动),基于三角测量的方法(如多视角立体视图(MVS))就会起作用,这样我们就可以获得整个场景(包括其中的人)的精确深度图。
我们收集了大约2000个这样的视频,跨越了广泛的真实场景,在这些场景中,人们自然地在不同的群体配置中摆出各种各样的姿势。

2、推断移动人体的深度
模仿人体造型的挑战视频为移动摄像头和“冻结”的人体提供了深度监督学习方法,但我们的研究目标是带有移动摄像头和移动的人体的视频。我们需要构造深度预测网络的输入,以便弥合这个缺口。
一种可能的方法是分别为视频的每一帧推断深度(即,模型的输入只是一个帧)。虽然这种模型已经比最先进的单图像深度预测方法有所改进,但是我们还是可以通过考虑来自多帧的信息来进一步改进结果。例如,运动视差,即静态物体在两个不同视点之间的相对表观运动的差异,提供了强烈的深度提示信息。为了利用这些信息,我们计算了视频中每个输入帧和另一帧之间的二维光流,它表示两帧之间的像素位移。这个流场取决于场景的深度和摄像机的相对位置。但是,由于摄像机位置已知,我们可以从流场中移除它们的依赖关系,从而生成初始深度图。这个初始深度仅对静态场景区域有效。
为了在测试时处理移动的人体,我们在初始深度图中应用了一个人形图像分割网络来屏蔽人体区域。这样,我们的深度预测网络的全部输入包括:RGB图像、人体区域的遮罩和一个非人体区域的初始深度图。
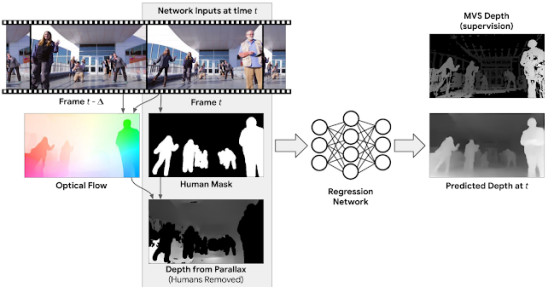
深度预测网络的任务是为有人体的地区“修复”深度值,并在其他地方细化深度。直观地说,由于人类具有一致的形状和物理维度,深度预测网络可以通过观察许多训练实例在内部学习这些先验知识。一旦经过训练,我们的模型可以处理任意摄像机和人体运动的自然视频。

3、使用我们深度图的3D视频效果
我们预测的深度图可以用来产生一系列三维感知视频效果。其中一个效果是合成散焦。下面是一个对普通视频使用我们的深度图的深度预测的示例。

我们深度图的其它可能应用包括从单目视频生成立体视频,并将合成CG对象插入到场景中。深度图还提供了用视频的其它帧中的内容填充孔和不被遮挡区域的能力。在下面的例子中,我们综合地在几个帧上晃动摄像机,并用来自视频其他帧的像素填充人体后面的区域。

原文链接:https://ai.googleblog.com/2019/05/moving-camera-moving-people-deep.html
作者:助理研究员Tali Dekel和机器感知软件工程师Forrester Cole。
本文为 CSDN 翻译,转载请注明来源出处。
译文链接:https://mp.weixin.qq.com/s/Q1l_0PoSV1jDbYyRi2XUyQ





